
Các tổ chức quan tâm đến AI hiện nay có quyền truy cập vào sức mạnh tính toán đáng kinh ngạc với Tensor Processing Units (TPUs) và Graphical Processing Units (GPUs), trong khi các mô hình nền tảng như Gemini đang định nghĩa lại những gì có thể.
Tuy nhiên, đối với nhiều doanh nghiệp, một trở ngại quan trọng đối với AI chính là dữ liệu, cụ thể là dữ liệu phi cấu trúc.
Theo Enterprise Strategy Group, đối với hầu hết các tổ chức, 61% tổng dữ liệu của họ là phi cấu trúc, phần lớn trong số đó nằm im trong kho lưu trữ mà không được phân tích hoặc gán nhãn, được gọi là “dữ liệu tối”.
Nhưng với sự trợ giúp của AI, nguồn tài nguyên chưa được khai thác này là một cơ hội để mở khóa một kho tàng thông tin chi tiết thực sự.
Đồng thời, khi nói đến dữ liệu phi cấu trúc, các công cụ truyền thống chỉ giải quyết được bề mặt, và các chuyên gia trong lĩnh vực phải xây dựng các pipeline tiền xử lý thủ công đồ sộ và định nghĩa ý nghĩa ngữ nghĩa của dữ liệu.
Điều này ngăn cản bất kỳ phân tích quy mô thực sự nào, ngăn các công ty sử dụng ngay cả một phần nhỏ những gì họ lưu trữ.
Bây giờ hãy tưởng tượng một thế giới nơi dữ liệu phi cấu trúc của bạn không chỉ được lưu trữ, mà còn được hiểu.
Một thế giới nơi bạn có thể đặt các câu hỏi phức tạp về dữ liệu như hình ảnh, video và tài liệu, và nhận được những câu trả lời thú vị.
Đây không chỉ là một tầm nhìn tương lai — kỷ nguyên của lưu trữ thông minh đã đến với chúng ta.
Hôm nay, chúng tôi công bố các tính năng chú thích tự động và ngữ cảnh đối tượng mới sử dụng AI để tạo siêu dữ liệu và thông tin chi tiết trên dữ liệu của bạn, để bạn có thể sử dụng dữ liệu tối của mình cho việc khám phá, quản lý và quản trị ở quy mô.
Tốt hơn nữa, các tính năng mới giúp bạn không phải xây dựng và quản lý các pipeline dữ liệu phân tích đối tượng của riêng mình.
Nội dung chính
Tận dụng AI để chuyển đổi dữ liệu tối
Giờ đây, khi dữ liệu phi cấu trúc được đưa vàoGoogle Cloud, nó không còn được coi là một đối tượng thụ động.
Thay vào đó, một pipeline dữ liệu tận dụng AI để tự động xử lý và hiểu dữ liệu, làm nổi bật các thông tin chi tiết và kết nối quan trọng.
Hai tính năng mới là không thể thiếu cho tầm nhìn này:
chú thích tự động, giúp làm phong phú dữ liệu của bạn bằng cách tự động tạo siêu dữ liệu sử dụng các mô hình AI được đào tạo trước của Google, vàngữ cảnh đối tượng, cho phép bạn đính kèm các thẻ tùy chỉnh, có thể hành động vào dữ liệu của bạn.
Cùng nhau, hai tính năng này có thể giúp chuyển đổi dữ liệu thụ động thành tài sản chủ động, mở khóa các trường hợp sử dụng như khám phá dữ liệu nhanh chóng cho đào tạo mô hình AI, quản lý dữ liệu được hợp lý hóa để giảm thiên kiến mô hình, quản trị dữ liệu nâng cao để bảo vệ thông tin nhạy cảm và khả năng xây dựng các quy trình công việc trạng thái mạnh mẽ trực tiếp trên bộ nhớ của bạn.
Làm cho dữ liệu của bạn thông minh
Chú thích tự động, hiện đang trong giai đoạn phát hành thử nghiệm giới hạn, tự động tạo siêu dữ liệu phong phú (“chú thích”) về các đối tượng được lưu trữ trong các bucketCloud Storagebằng cách áp dụng các mô hình AI tiên tiến của Google, bắt đầu với các đối tượng hình ảnh.
Bắt đầu rất đơn giản:
bật chú thích tự động cho các bucket bạn chọn hoặc toàn bộ dự án, chọn một hoặc nhiều mô hình có sẵn và toàn bộ thư viện hình ảnh của bạn sẽ được chú thích.
Hơn nữa, hình ảnh mới sẽ tự động được chú thích khi chúng được tải lên.
Vòng đời của một chú thích luôn gắn liền với vòng đời của đối tượng của nó, đơn giản hóa việc quản lý và giúp đảm bảo tính nhất quán.
Quan trọng là, chú thích tự động hoạt động dưới sự kiểm soát của bạn, chỉ truy cập nội dung đối tượng mà bạn đã cấp quyền rõ ràng.
Sau đó, bạn có thể truy vấn các chú thích, có sẵn dưới dạng ngữ cảnh đối tượng, thông qua các lệnh gọi API Cloud Storage vàtập dữ liệu Storage Insights.
Bản phát hành ban đầu sử dụng các mô hình được đào tạo trước để tạo chú thích:
phát hiện đối tượng với điểm tin cậy, gán nhãn hình ảnh và phát hiện nội dung không phù hợp.
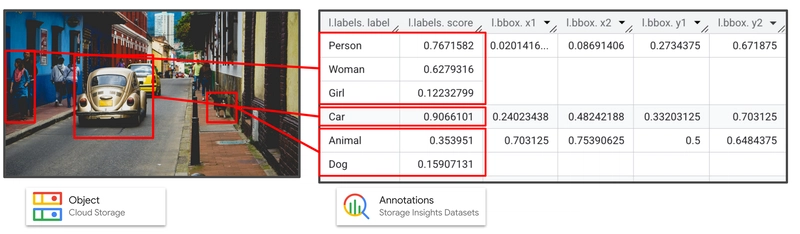
Sau đó, với ngữ cảnh đối tượng, bạn có thể đính kèm siêu dữ liệu cặp khóa-giá trị tùy chỉnh trực tiếp vào các đối tượng trong Cloud Storage, bao gồm cả thông tin được tạo bởi tính năng chú thích tự động mới.
Hiện đang trong giai đoạn xem trước, ngữ cảnh đối tượng được tích hợp nguyên bản với các API Cloud Storage để liệt kê và thao tác hàng loạt, cũng như các tập dữ liệu Storage Insights để phân tích trong BigQuery.
Mỗi ngữ cảnh bao gồm dấu thời gian tạo và sửa đổi đối tượng, cung cấp thông tin nguồn gốc có giá trị.
Bạn có thể sử dụng quyền Identity and Access Management (IAM) để kiểm soát ai có thể thêm, thay đổi hoặc xóa ngữ cảnh đối tượng.
Khi di chuyển dữ liệu từ Amazon S3 bằng cách sử dụng API Cloud Storage, các Thẻ Đối tượng S3 hiện có sẽ tự động được chuyển đổi thành ngữ cảnh.
Tóm lại, ngữ cảnh đối tượng cung cấp một cách linh hoạt và nguyên bản để thêm ngữ cảnh làm phong phú dữ liệu của bạn.
Kết hợp với một tính năng lưu trữ thông minh như chú thích tự động, ngữ cảnh đối tượng chuyển đổi dữ liệu thành thông tin, cho phép bạn xây dựng các quy trình công việc quản lý dữ liệu tinh vi trực tiếp trong Cloud Storage.
Bây giờ, hãy xem xét sâu hơn một số trường hợp sử dụng mới mà các tính năng lưu trữ thông minh này mang lại.
1. Khám phá dữ liệu
Một trong những thách thức quan trọng nhất trong việc xây dựng các ứng dụng AI mới là khám phá dữ liệu — làm thế nào để tìm dữ liệu phù hợp nhất trên khắp các kho dữ liệu rộng lớn và thường bị cô lập của một doanh nghiệp.
Việc định vị hình ảnh hoặc thông tin cụ thể trong hàng petabyte dữ liệu phi cấu trúc có thể cảm thấy bất khả thi.
Chú thích tự động tự động tạo ra các chú thích mô tả phong phú cho dữ liệu của bạn trong Cloud Storage.
Các chú thích, bao gồm nhãn và các đối tượng được phát hiện, có sẵn trong ngữ cảnh đối tượng và được lập chỉ mục đầy đủ trong BigQuery.
Sau khi tạo embeddings cho chúng, bạn có thể sử dụng BigQuery để chạy tìm kiếm ngữ nghĩa cho các chú thích này, giải quyết hiệu quả vấn đề “tìm kim đáy bể”.
Ví dụ, một nhà bán lẻ lớn với hàng triệu hình ảnh sản phẩm có thể sử dụng chú thích tự động và BigQuery để nhanh chóng tìm ‘váy đỏ’ hoặc ‘ghế sofa da’, đẩy nhanh nỗ lực quản lý danh mục và tiếp thị.
2. Quản lý dữ liệu cho AI
Xây dựng các mô hình AI hiệu quả đòi hỏi các tập dữ liệu được quản lý cẩn thận.
Việc sàng lọc dữ liệu để đảm bảo nó đại diện rộng rãi (ví dụ:
“tập dữ liệu này có ô tô với nhiều màu sắc không?”) để giảm thiên kiến mô hình, hoặc để chọn các ví dụ đào tạo cụ thể (ví dụ:
“Tìm hình ảnh có ô tô màu đỏ”), vừa tốn thời gian vừa dễ xảy ra lỗi.
Chú thích tự động có thể xác định các thuộc tính như màu sắc và loại đối tượng, để tự động hóa việc chọn các tập dữ liệu cân bằng.
Ví dụ, một công ty xe tự hành đào tạo mô hình có thể sử dụng hàng petabyte dữ liệu camera trên đường để nhận dạng biển báo giao thông, sử dụng chú thích tự động để xác định và trích xuất các hình ảnh có chứa từ ‘Dừng’ hoặc ‘Qua đường dành cho người đi bộ’.
Vivint, một công ty nhà thông minh và an ninh, đã sử dụng tính năng tự động chú thích để tìm kiếm và hiểu dữ liệu của họ.
“Khách hàng tin tưởng chúng tôi trong việc giúp ngôi nhà và cuộc sống của họ an toàn hơn, thông minh hơn và tiện lợi hơn, và AI là trái tim của các đổi mới sản phẩm và trải nghiệm khách hàng.
Siêu dữ liệu phong phú từ tính năng tự động chú thích của Cloud Storage được cung cấp trong BigQuery giúp chúng tôi mở rộng quy mô nỗ lực khám phá và quản lý dữ liệu, đẩy nhanh quá trình phát triển AI từ 6 tháng xuống chỉ còn 1 tháng bằng cách tìm ra những dữ liệu quan trọng như tìm kim đáy bể để cải thiện mô hình của chúng tôi.”
– Brandon Bunker, Phó Chủ tịch Sản phẩm AI, Vivint
3. Quản trị dữ liệu phi cấu trúc ở quy mô lớn
Dữ liệu phi cấu trúc không ngừng phát triển, và việc quản lý và quản trị thủ công dữ liệu đó để xác định thông tin nhạy cảm, phát hiện vi phạm chính sách hoặc phân loại để quản lý vòng đời là một thách thức.
Tính năng tự động chú thích và ngữ cảnh đối tượng giúp giải quyết những thách thức về quản trị dữ liệu và tuân thủ này.
Ví dụ, một khách hàng bán lẻ có thể sử dụng tính năng tự động chú thích để xác định và đánh dấu hình ảnh chứa thông tin nhận dạng cá nhân (PII) của khách hàng như nhãn vận chuyển hoặc đơn đặt hàng.
Thông tin này, được lưu trữ trong ngữ cảnh đối tượng, sau đó có thể kích hoạt các hành động quản trị tự động như di chuyển các đối tượng được đánh dấu vào nhóm hạn chế hoặc khởi động quy trình xem xét.
BigID, một đối tác xây dựng giải pháp trên Cloud Storage, báo cáo rằng việc sử dụng ngữ cảnh đối tượng đang giúp họ quản lý rủi ro của khách hàng:
“Ngữ cảnh đối tượng cung cấp cho chúng tôi cách để lấy đầu ra từ các giải pháp phân loại dữ liệu hàng đầu ngành của BigID và áp dụng nhãn cho các đối tượng Cloud Storage.
Ngữ cảnh đối tượng sẽ cho phép nhãn BigID làm sáng tỏ dữ liệu trong Cloud Storage:
xác định các đối tượng chứa thông tin nhạy cảm và giúp họ hiểu và quản lý rủi ro trên các lĩnh vực AI, bảo mật và quyền riêng tư.”
– Marc Hebrard, Kiến trúc sư Kỹ thuật Chính, BigID
Tương lai tươi sáng cho dữ liệu của bạn
Tại Google Cloud, chúng tôi cam kết xây dựng một tương lai nơi dữ liệu của bạn không chỉ là tài sản thụ động mà còn là chất xúc tác tích cực cho đổi mới.
Đừng giữ dữ liệu quý giá của bạn trong bóng tối.
Hãy mang dữ liệu của bạn đến Cloud Storage và kích hoạt tính năng chú thích tự động và ngữ cảnh đối tượng để mở khóa toàn bộ tiềm năng của nó với Gemini, Vertex AI và BigQuery.
Bạn có thể bắt đầu sử dụng ngữ cảnh đối tượng ngay hôm nay.
Khi bạn có quyền truy cập, chỉ cần bật tính năng tự động chú thích cho các nhóm được chọn hoặc toàn bộ dự án, chọn một hoặc nhiều mô hình có sẵn và toàn bộ thư viện hình ảnh của bạn sẽ được chú thích.
Sau đó, bạn có thể truy vấn các chú thích có sẵn dưới dạng ngữ cảnh đối tượng thông qua các lệnh gọi API Cloud Storage và tập dữ liệu Storage Insights.
Để tìm hiểu thêm, hãy đọc về tầm nhìn end-to-end của chúng tôi trong một bài báo giới thiệu với Enterprise Strategy Group:Làm sáng tỏ Dữ liệu Tối với Lưu trữ Thông minh từ Google Cloud.






 trong C++")


{kind=link}