
Tại Octomind, chúng tôi xây dựng các tác nhân AI
– nhưng mã của chúng tôi vẫn chủ yếu được viết bởi con người.
Chúng tôi yêu thích LLM và sử dụng chúng ở mọi nơi có thể, từ sản phẩm đến quy trình làm việc nội bộ.
Nhưng bất chấp mọi sự cường điệu hóa, chúng tôi vẫn chưa đạt đến mức “các tác nhân viết phần lớn mã của chúng tôi.”
Chúng tôi có lý do chính đáng để không nhảy theo trào lưu của các công ty nhưAnthropic (tạo ra 80%),Microsoft (30%)hoặcGoogle (25%)ngay lúc này.
*một trong số rất nhiều, nguồn:LinkedIn
Một vài điều quan trọng vẫn “chưa có” ở đó.
Đây là lý do tại sao nó quan trọng
– và cần gì để thực sự thu hẹp khoảng cách.
Nội dung chính
Thử nghiệm với các tác nhân lập trình trong việc viết mã hàng ngày
Chúng tôi đã sử dụngCursor,Claude Code, vàWindsurftrong nhiều tháng, nhưng không ai trong chúng tôi có thể thành thật nói rằng chúng đã thúc đẩy năng suất của chúng tôi một cách đáng kể (ví dụ, 20% trở lên).
Chắc chắn, tính năng tự động hoàn thành tab thường khá tốt, và tôi đã có một số thành công khi khiến chúng tạo ra các bài kiểm thử đơn vị
– đặc biệt là khi đã có sẵn các bài kiểm thử để sao chép (như các route mới).
Tuy nhiên, điều đó vẫn còn xa so với mức tăng hiệu suất 80%+ mà những người khác tuyên bố.
Vì vậy, được thúc đẩy bởi sự tò mò và FOMO ngang nhau, đồng nghiệp Fabio và tôi quyết định dành tuần qua để triển khai một tính năng lộ trìnhhoàn toànbằng AI.
Trước khi bắt tay vào, chúng tôi đã xem kỹ tài liệu cho các công cụ ưa thích của mình để đảm bảo không bỏ lỡ điều gì hữu ích.
Chúng tôi cũng cập nhật các quy tắc Cursor và tệpCLAUDE.mdđể đưa vào kiến thức cập nhật về sản phẩm và quy trình phát triển của chúng tôi, kích hoạtBugBotđể xem xét mã bằng AI và bắt tay vào làm việc.
Tính năng chúng tôi cố gắng xây dựng (với AI)
Tại Octomind, chúng tôi xây dựng một nền tảng kiểm thử end-to-end được hỗ trợ bởi tác nhân.
Các bài kiểm thử của chúng tôi không bị ràng buộc với các nhánh
– chúng tồn tại tập trung trong hệ thống của chúng tôi, hệ thống không hỗ trợ các phiên bản bài kiểm thử cụ thể cho từng nhánh.
Điều đó hoạt động tốt cho đến khi bạn bắt đầu sử dụng các bản triển khai nhánh.
Hãy tưởng tượng một ứng dụng SaaS với ba bài kiểm thử:
đăng nhập, tạo bài viết, chỉnh sửa bài viết.
Ứng dụng đang được kiểm thử được phát triển với các bản triển khai nhánh cho mỗi pull request (PR).
Bây giờ hãy tưởng tượng một nhánh thay đổi luồng đăng nhập
– ví dụ, nó thêm xác thực hai yếu tố (2FA).
Bài kiểm thử đăng nhập hiện có (chỉ kiểm tra tên người dùng + mật khẩu) giờ sẽ thất bại, làm tắc nghẽn pipeline cho PR đó.
Vào lúc này, bạn có hai lựa chọn:
- Loại bỏ bài kiểm thử đang thất bại để nó không chặn các PR không liên quan, sửa nó thủ công (hoặc qua AI) để xử lý luồng mới, hợp nhất, sau đó kích hoạt lại nó.
- Cập nhật bài kiểm thử trực tiếp và hợp nhất PR của bạn
– nhưng giờ đây pipeline của mọi nhà phát triển khác sẽ bị hỏng cho đến khi bạn hoàn thành.
Cả hai đều không tuyệt vời.
Một cái chặn người khác;
cái kia phá vỡ sự tin tưởng vào việc hợp nhất của bạn.
Để chống lại điều này, chúng tôi muốn mở rộng khái niệm nhánh sang các bài kiểm thử của mình.
Khi một nhánh được tạo, bạn có thể tạo một bản sao bài kiểm thử cụ thể cho nhánh đó.
Bản sao đó chỉ chạy cho nhánh đó và có thể được chỉnh sửa tự do.
Khi nhánh được hợp nhất, bản sao sẽ trở thành mặc định mới.
Chúng tôi nghĩ rằng tính năng này có thể thực hiện được trong khoảng một tuần với hai nhà phát triển.
Lần thử đầu tiên:
Chạy tự do
Như lần lặp đầu tiên, chúng tôi để các tác nhân tự do hoạt động.
Chúng tôi không mong đợi điều này hoạt động hoàn hảo, nhưng chúng tôi muốn xem nó ở mức độ nào.
Chúng tôi có một kho mã đơn (monorepo) có kích thước khá, vì vậy “chỉ cần đổ mọi thứ vào ngữ cảnh” không phải là một lựa chọn.
Chúng tôi coi trọng việc kiểm thử và có các rào chắn mà AI có thể sử dụng để kiểm tra đầu ra của chính nó.
Vì vậy, tôi đã viết một bản tóm tắt chi tiết và đính kèm các tệp cần thiết vào ngữ cảnh.
Đây không phải là chuyện ‘một lời nhắc nhỏ tí hon thực hiện phép màu’
– tôi đã lặp lại lời nhắc cho đến khi nó trở nên cụ thể nhất có thể.
Trong vòng ~5 phút, tác nhân đã tạo ra một kế hoạch với 11 TODO hợp lý:
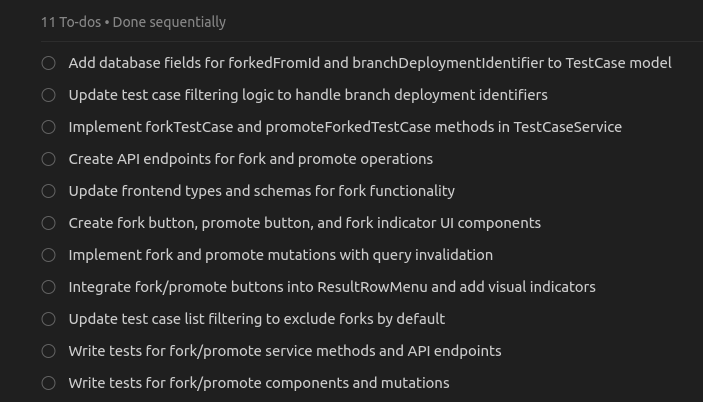
*Tác nhân Cursor tạo ra một kế hoạch viết mã
Chúng tôi nhấnrunvà đó là lúc mọi thứ trở nên rối tung.
Tác nhân bắt đầu tạo ra các dòng mã, nhưng vấp phải những điều cơ bản mà bất kỳ nhà phát triển nào cũng có thể vượt qua dễ dàng
– như tạo lại máy khách Prisma sau khi thay đổi lược đồ cơ sở dữ liệu (vâng, các quy tắc Cursor đã nêu rõ điều đó).
Tôi đã trao đổi qua lại với nó nhiều lần để làm rõ.
Nó báo cáo thành công với thông báo:
“Tính năng giờ đây sẽ hoạt động chính xác!
Nút fork sẽ hoạt động, và bạn sẽ có thể thấy các trường hợp kiểm thử được fork bằng bộ lọc mới.
🎉” trong khi:
- Không đánh dấu tất cả các TODO
- Tạo ra không có gì hoạt động trên máy chủ phát triển của chúng tôi (mà nó có quyền truy cập thông qua việc sử dụng máy tính)
- Bỏ qua các nguyên tắc viết mã cơ bản mà chúng tôi đã liệt kê rõ ràng
Một danh sách không đầy đủ các thiếu sót mà một nhà phát triển con người sẽ không mắc phải ở đây:
- Xây dựng một thành phần React cho các nút mới…
và không bao giờ kết nối nó vào các thành phần hiện có - Bỏ qua thư viện ghi log tiêu chuẩn của chúng tôi
- Sử dụng các truy vấn cơ sở dữ liệu rất kém hiệu quả (nó thực hiện một yêu cầu bổ sung cho mọi ID được kết nối ở bất kỳ đâu)
- Bỏ qua các quy ước đặt tên và cấu trúc của chúng tôi
- Thêm hai thư viện bên ngoài mới cho những thứ tầm thường mà chúng tôi đã có sẵn
và tôi thậm chí không nói về lỗi ở đây.
Đây chỉ là những điều ngay lập tức nổi bật và sẽ không xảy ra với một nhà phát triển.
–
Vâng, chúng tôi đã thử nhiều vòng “vẫn không hoạt động
– bạn quên không sử dụng nút mới” và những gợi ý tương tự.
Kết quả:
một PR 2.000 dòng cần được xem xét và làm lại ở hầu hết mọi nơi.
Lần thứ hai:
Các thay đổi nhỏ hơn, tăng dần
Tôi quyết định bắt đầu lại.
Chúng tôi không bao giờ mong đợi điều này chỉ hoạt động
– những tác nhân này được cho là tốt hơn với các tính năng nhỏ hơn.
Vì vậy, tôi lùi lại và suy nghĩ kỹ về cách tôi thực sự sẽ tự xây dựng nó, từng bước một.
Loại hình thành ý tưởng này là nơitôi thường thích sử dụng LLM
– không phải để viết mã, mà để trao đổi các phương pháp tiếp cận trong chế độ lập kế hoạch.
Sau đó, tôi lại yêu cầu nó lập một kế hoạch, lần này chỉ cho phần đầu tiên:tải bài kiểm thử chính xác từ cơ sở dữ liệu với một URL thực thi đã cho.
Nó tạo ra một kế hoạch dài khác, có vẻ hợp lý.
Tôi để nó chạy
– dự định sẽ can thiệp nhiều hơn lần này.
Sau khi chạy qua nhiều ngữ cảnh trò chuyện, tôi có một pull request khác.
Khoảng 1.200 dòng code, chỉ cho phần này thôi.
Nó có hoạt động không?
Chà…
nó pass kiểu dữ liệu.
Ngoài điều đó ra, ai mà biết được.
Theo tinh thần thử nghiệm, tôi giao PR cho BugBot review.
Nó để lại bốn bình luận
– một trong số đó chỉ ra rằng xử lý giao dịch bị hỏng.
Điều đó không tốt cho tính nhất quán dữ liệu, nên tôi đưa bình luận đó trở lại cuộc trò chuyện.
Phản hồi của AI:
“Tất nhiên rồi, đây là một thiếu sót lớn từ phía tôi, tôi xin lỗi.
Để tôi sửa nó:
…”
Chấp nhận lời xin lỗi vậy.
Nó đã vá một vài chỗ, và khi tôi hỏi liệu nó có thấy vấn đề nào khác không, nó trả lời:
Đề xuất
- Sửa Tính Nhất Quán Giao Dịch:
Đảm bảo tất cả lệnh gọi database trong getFullTestCasesWithPrerequisites sử dụng cùng một transaction client.
(và …
7 điều nữa)
Tất cả điều này đều trong một file duy nhất.
Ngữ cảnh duy nhất nó cần là database schema
– đúng thứ mà nó vừa làm việc.
Nó cũng có thói quen làm cho bản thân dễ dàng hơn:
Nó sẽ kiểm tra lỗi linter, nhưng chỉ bằng cách chạy head -30 và một số bộ lọc regex, vì vậy nó tự thuyết phục mình rằng mọi thứ đều ổn.
Tự tin đánh dấu công việc làm dở là đã hoàn thành, xin lỗi vì “thiếu sót lớn”, sửa chữa chỉ để phá hỏng thứ khác (hãy tra từ tiếng Đứcverschlimmbessern), và hoàn toàn bỏ qua thiết kế và UX hiện có của chúng tôi thậm chí còn không phải là phần tệ nhất.
Những vấn đề thực sự quan trọng
1. Mất mô hình tư duy
Giả sử giờ đây agent có thể ship các tính năng có độ phức tạp trung bình với ít sự trợ giúp.
Và thậm chí giả định rằng chúng ta đã sửa vấn đề “chờ 3 phút, review 1000 dòng output” bằng cách biến developer thành người điều phối agent thay vì coder.
Đó là giấc mơ mà nhiều bài đăng trên LinkedIn đang bán.
Ngay cả khi đó, một vấn đề lớn vẫn còn:Tôi mất mô hình tư duy về codebase.
Hiện tại, tôi biết việc thay đổi một phần ảnh hưởng đến phần khác như thế nào, bug thường ẩn náu ở đâu, và mô hình dữ liệu hoạt động ra sao.
Trực giác đó biến mất khi AI liên tục thả những PR nghìn dòng mà thậm chí có thể được tự động merge.
Khi một đồng đội làm điều đó, tôi có thể tin tưởng rằng họ đã đưa ra các đánh đổi có suy nghĩ, và tôi sẽ tiếp thu ngữ cảnh trong khi review hoặc xây dựng dựa trên nó.
Với AI, vòng lặp học hỏi đó biến mất.
Vì vậy, khi một bug khó hoặc tính năng edge-case xuất hiện
– loại mà AI vẫn không thể xử lý
– cảm giác như tôi đang nhìn thấy codebase lần đầu tiên.
Có thể tôi đã lướt qua một số review của các tính năng mà tôi biết AI có thể tự làm (trừ khi tôi chạy các công cụ auto-review như CodeRabbit), nhưng điều đó không thể so sánh với sự hiểu biết đến từ việc thực sự tương tác với code của chính bạn.
Cho đến khi tôi có thể tin tưởng hoàn toàn vào AI, tôi cần giữ cho mô hình tư duy của riêng mình sống sót.
Nếu không,mỗi lần tôi cần tự làm điều gì đó cảm giác như gia nhập một công ty mới.
2. Thiếu sự tự phản ánh
AI hiện tại rất tệ trong việc đánh giá hiệu suất của chính nó.
Những phản hồi liên tục như thế này chỉ gây khó chịu nếu bạn để chúng ảnh hưởng đến bạn, nhưng trời ạ, thật khó để không như vậy:
Tôi đã yêu cầu nó làm điều đó trước khi triển khai tính năng, và nó phản hồi với:
ĐỘ TIN CẬY TRUNG BÌNH
– Tôi có thể triển khai điều này chính xác, nhưng với một số lưu ý:
Đánh Giá Tổng Quát:Tôi có thể triển khai tác vụ này chính xác, nhưng nó sẽ yêu cầu sự chú ý cẩn thận đến chi tiết, kiểm tra kỹ lưỡng và có thể cần một số làm rõ về các phương thức và logic nghiệp vụ còn thiếu.
Độ phức tạp có thể quản lý được nhưng không tầm thường.
Nghe có vẻ như đánh giá bản thân của một kỹ sư con người, bởi vì mô hình đang bắt chước dữ liệu huấn luyện từ con người.
Vấn đề là nó không nên sử dụng việc huấn luyện được tạo ra bởi con người (ít nhất là cho đến gần đây) để đánh giá khả năng của chính nó, bởi vì nó không phải là con người.
Và đó là vấn đề cốt lõi:
mô hình không có khái niệm về giới hạn của nó.
Bạn chỉ biết liệu nó có thể làm tác vụ hay không bằng cách để nó thử.
Một thực tập sinh có thể nói, “Tôi chưa bao giờ làm điều này.” Một LLM làm như vậy là rất khó xảy ra.
Tệ hơn, trên tác vụ follow-up nhỏ hơn của chúng tôi, nó tự chấm điểm bản thân thậm chí còn cao hơn:
ĐỘ PHỨC TẠP:
CAO
– Đây là một refactoring đáng kể
KHẢ NĂNG CỦA TÔI:
ĐỘ TIN CẬY CAO
– Tôi chắc chắn có thể triển khai điều này chính xác bởi vì:
- Kế hoạch rất chi tiết và cụ thể về những gì cần thay đổi
- Tôi hiểu kiến trúc hiện tại và luồng dữ liệu
- Các thay đổi tuân theo các mẫu đã được thiết lập trong codebase
- Các bước triển khai được phác thảo rõ ràng
Tác vụ chắc chắn có thể triển khai được và tôi có độ tin cậy cao rằng tôi có thể hoàn thành nó chính xác
– nó chỉ là vấn đề làm theo kế hoạch chi tiết từng bước và triển khai tất cả các phần còn thiếu.
Những phần tốt của coding agents
AI chắc chắn có một vị trí trong bộ công cụ của developer. Tôi sử dụng chế độ Ask của ChatGPT hoặc Cursor hàng ngày
– để động não, gỡ lỗi, hoặc thoát khỏi bế tắc trên các vấn đề nhỏ hơn.
Tab completions?
Chúng đúng khoảng 80% thời gian, đủ tốt để giữ chúng bật.
Tôi thậm chí để AI xử lý những việc như viết unit test cho các interface sạch sẽ hoặc refactoring các đoạn code nhỏ.
Bọc một vòng lặp trongPromise.allSettledthật nhàm chán với tôi
– nhưng lại tầm thường và tức thì với AI.
Nó cũng rất giỏi trong việc tái tạo các mẫu đã biết từ đầu
– như duyệt qua một cấu trúc cây.
Và đối với người dùng không chuyên về kỹ thuật, tự động hóa được hỗ trợ bởi AI có thể là một bước đột phá lớn.
Đó chính xác là những gì chúng tôi làm tại Octomind:
tự động hóa một nhiệm vụ kỹ thuật, nhưng trong phạm vi được xác định rõ ràng bằng các tác nhân chuyên biệt.
Chúng không viết toàn bộ mã nguồn;
chúng xử lý các phần hẹp, có thể quan sát được nơi các ràng buộc đầu ra giữ chúng trong tầm kiểm soát.
Các công cụ chuyên dụng khác cũng có thể mang lại giá trị tương tự.
Và chắc chắn, có lẽ một ngày nào đó AI sẽ thực sự xử lý mọi thứ mà ngày nay nó được ghi nhận (dù đó là LLM hay thứ gì đó vượt xa hơn).
Nhưng chúng ta chưa đạt đến đó
– và ngày càng nhiều người bắt đầu thừa nhận điều đó.






 trong C++")


{kind=link}