
Cafedev là nơi chia sẻ kiến thức và kinh nghiệm, và chúng ta không thể bỏ qua chủ đề mới hấp dẫn về “Kotlin với Coroutines và channels”. Trong hướng dẫn này, chúng ta sẽ khám phá sức mạnh của ngôn ngữ lập trình Kotlin khi kết hợp với Coroutines và channels. Điều này không chỉ giúp tối ưu hiệu suất mã nguồn mà còn mở ra những cách tiếp cận mới trong lập trình đa luồng. Hãy cùng nhau đắm chìm vào hành trình khám phá Kotlin qua bài hướng dẫn này trên Cafedev.
Trong hướng dẫn này, bạn sẽ tìm hiểu cách sử dụng coroutines trong IntelliJ IDEA để thực hiện các yêu cầu mạng mà không chặn luồng cơ bản hoặc callback.
Không cần kiến thức trước về coroutines, nhưng bạn nên quen thuộc với cú pháp cơ bản của Kotlin.
Bạn sẽ tìm hiểu:
* Tại sao và làm thế nào sử dụng suspending functions(hàm tạm dừng) để thực hiện các yêu cầu mạng.
* Làm thế nào để gửi các yêu cầu cùng một lúc bằng cách sử dụng coroutines.
* Làm thế nào để chia sẻ thông tin giữa các coroutines khác nhau bằng cách sử dụng channels.
Đối với yêu cầu mạng, bạn sẽ cần thư viện Retrofit, nhưng cách tiếp cận được dùng trong hướng dẫn này hoạt động tương tự cho bất kỳ thư viện nào khác hỗ trợ coroutines.
Bạn có thể tìm thấy giải pháp cho tất cả các công việc trên nhánh solutions của dự án trên GitHub.
Nội dung chính
1. Trước khi bạn bắt đầu cần phải biết
1. Tải và cài đặt IDE
phiên bản mới nhất của IntelliJ IDEA.2. Sao chép mẫu dự án bằng cách chọn Get from VCS trên màn hình
Chào mừng hoặc chọn File | New | Project from Version Control.
Bạn cũng có thể sao chép nó từ dòng lệnh:
git clone https://github.com/kotlin-hands-on/intro-coroutines2. Tạo token phát triển viên GitHub
Bạn sẽ sử dụng API GitHub trong dự án của mình. Để có quyền truy cập, cung cấp tên tài khoản GitHub của bạn và một mật khẩu hoặc token. Nếu bạn đã kích hoạt xác thực hai yếu tố, chỉ cần một token là đủ.
Tạo một token GitHub mới để sử dụng API GitHub với tài khoản của bạn:
1. Chỉ định tên của token của bạn, ví dụ: coroutines-tutorial: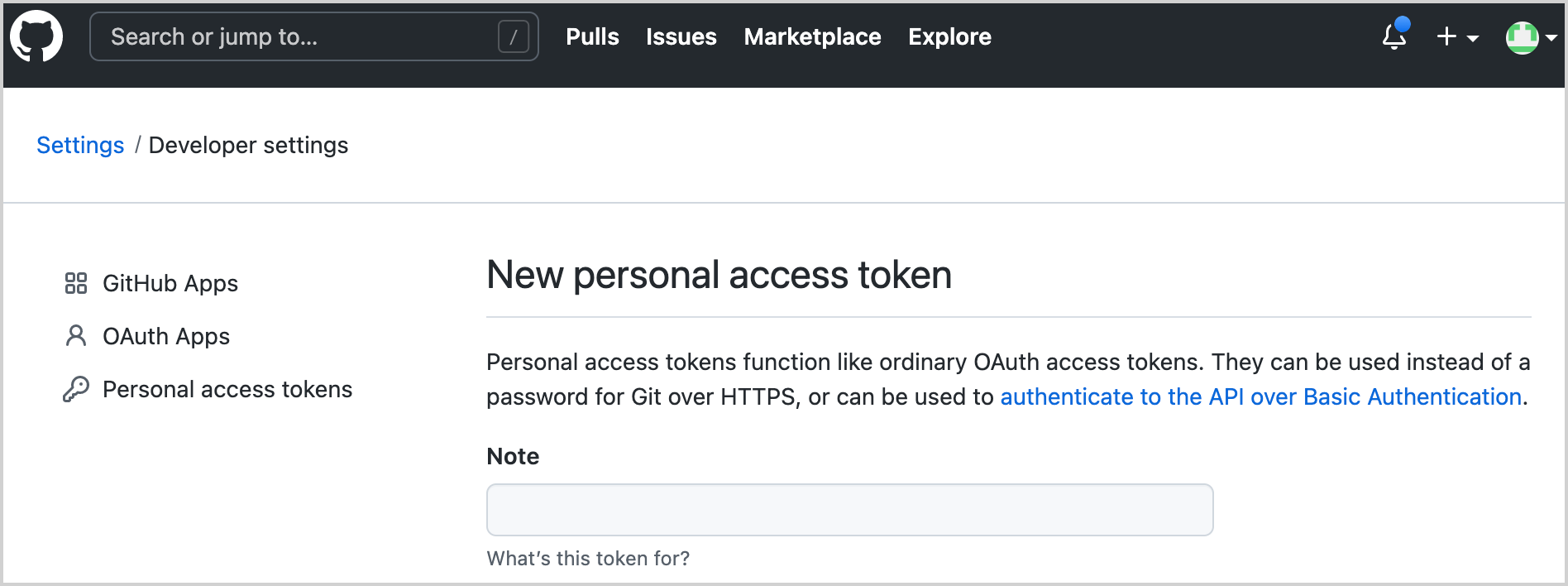
2. Không chọn bất kỳ phạm vi nào. Nhấp vào Generate token ở dưới trang.
3. Sao chép token đã tạo.
3. Chạy mã
Chương trình tải thông tin người đóng góp cho tất cả các kho lưu trữ dưới tổ chức cụ thể (mặc định là “kotlin”). Sau đó, bạn sẽ thêm logic để sắp xếp người dùng theo số lượng đóng góp của họ.
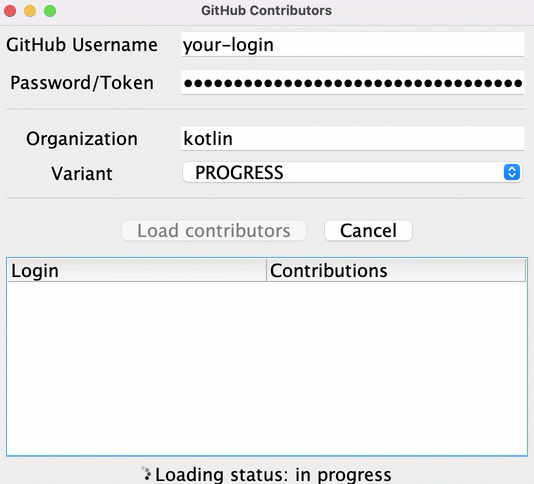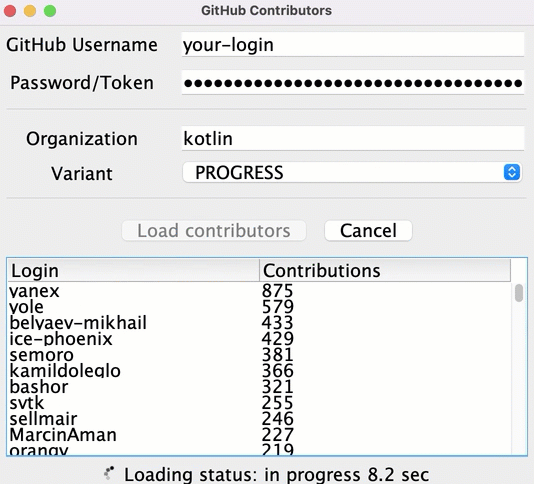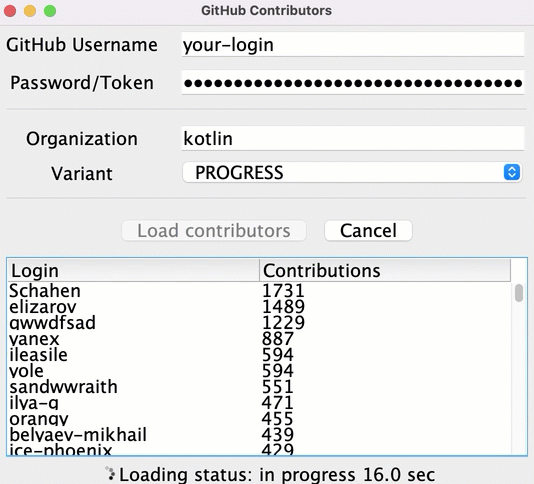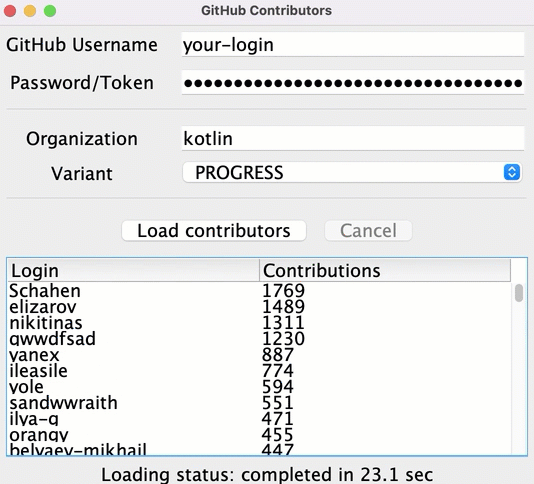
1. Mở tệp src/contributors/main.kt và chạy hàm main(). Bạn sẽ thấy cửa sổ như sau: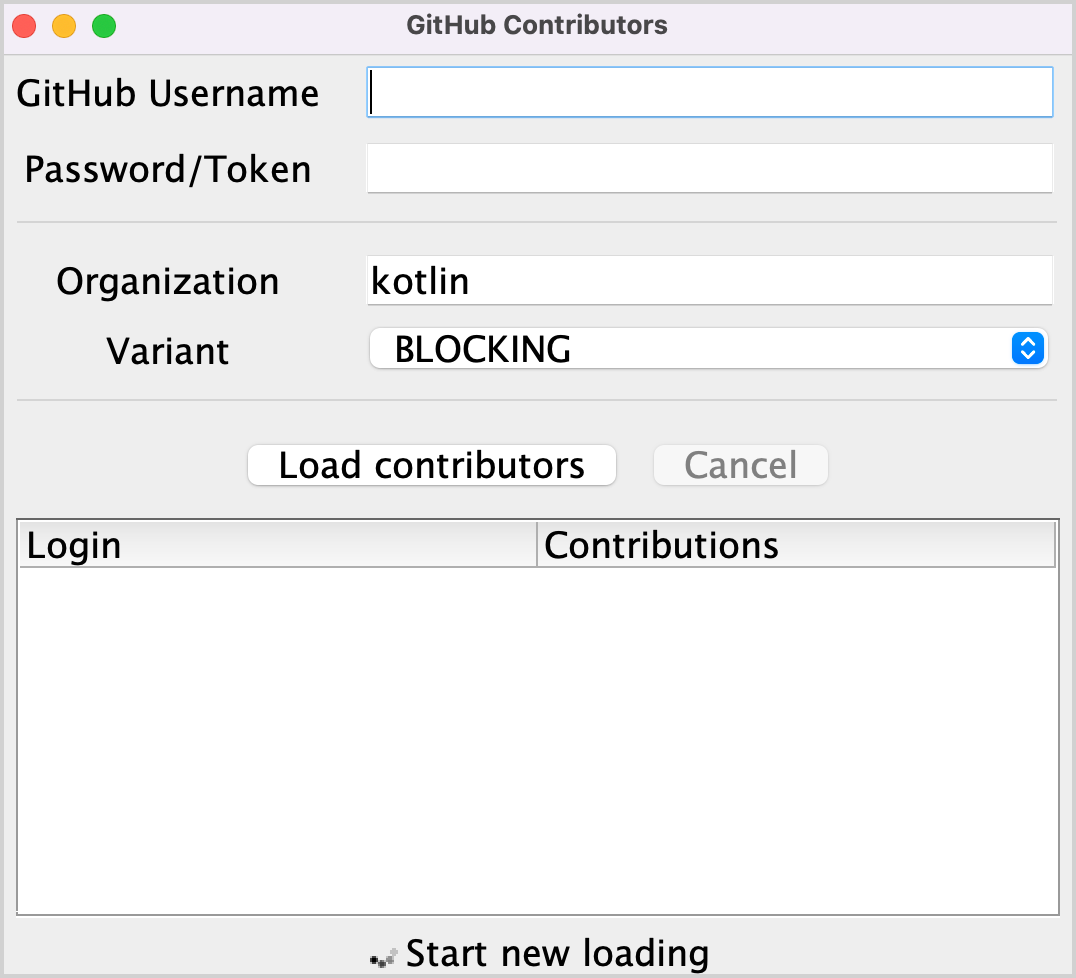
Nếu font quá nhỏ, điều chỉnh bằng cách thay đổi giá trị setDefaultFontSize(18f) trong hàm main().
2. Nhập tên người dùng GitHub và token (hoặc mật khẩu) của bạn vào các trường tương ứng.
3. Đảm bảo rằng tùy chọn BLOCKING được chọn trong menu thả xuống Variant.
4. Nhấp vào Load contributors. Giao diện người dùng sẽ đóng băng trong một khoảng thời gian và sau đó hiển thị danh sách người đóng góp.
5. Mở đầu ra chương trình để đảm bảo rằng dữ liệu đã được tải. Danh sách người đóng góp được đăng nhập sau mỗi yêu cầu thành công.
Có nhiều cách triển khai logic này: bằng cách sử dụng yêu cầu chặn(Blocking requests) hoặc callbacks. Bạn sẽ so sánh những giải pháp này với một giải pháp sử dụng coroutines và xem làm thế nàochannels có thể được sử dụng để chia sẻ thông tin giữa các coroutines khác nhau.
4. Yêu cầu chặn(Blocking requests)
Bạn sẽ sử dụng thư viện Retrofit để thực hiện các yêu cầu HTTP đến GitHub. Nó cho phép yêu cầu danh sách các kho lưu trữ dưới tổ chức đã chọn và danh sách người đóng góp cho mỗi kho lưu trữ:
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
fun getOrgReposCall(
@Path("org") org: String
): Call<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Call<List<User>>
}
API này được sử dụng bởi hàm loadContributorsBlocking() để lấy danh sách người đóng góp cho tổ chức đã chọn.
1. Mở src/tasks/Request1Blocking.kt để xem cách nó được triển khai:
fun loadContributorsBlocking(service: GitHubService, req: RequestData): List<User> {
val repos = service
.getOrgReposCall(req.org) // #1
.execute() // #2
.also { logRepos(req, it) } // #3
.body() ?: emptyList() // #4
return repos.flatMap { repo ->
service
.getRepoContributorsCall(req.org, repo.name) // #1
.execute() // #2
.also { logUsers(repo, it) } // #3
.bodyList() // #4
}.aggregate()
}- Ban đầu, bạn nhận được danh sách các kho lưu trữ dưới tổ chức đã chọn và lưu trữ nó trong danh sách
repos. Sau đó, với mỗi kho lưu trữ, danh sách người đóng góp được yêu cầu và tất cả các danh sách được hợp nhất thành một danh sách cuối cùng của người đóng góp.
getOrgReposCall()vàgetRepoContributorsCall()đều trả về một thể hiện của lớp*Call(#1). Tại thời điểm này, không có yêu cầu nào được gửi.
Call.execute()sau đó được gọi để thực hiện yêu cầu (#2).execute()là một cuộc gọi đồng bộ làm chặn luồng cơ bản.
- Khi bạn nhận được phản hồi, kết quả được đăng nhập bằng cách gọi các hàm
logRepos()vàlogUsers()cụ thể (#3). Nếu phản hồi HTTP chứa lỗi, lỗi này sẽ được đăng nhập ở đây. - Cuối cùng, nhận thân phản hồi, chứa dữ liệu bạn cần. Trong hướng dẫn này, bạn sẽ sử dụng một danh sách trống như kết quả trong trường hợp có lỗi và bạn sẽ đăng nhập lỗi tương ứng (
#4).
2. Để tránh lặp lại.body() ?: emptyList(), một hàm mở rộngbodyList()được khai báo:
fun <T> Response<List<T>>.bodyList(): List<T> {
return body() ?: emptyList()
}
3. Chạy chương trình lại và xem đầu ra hệ thống trong IntelliJ IDEA. Nó nên có gì đó giống như sau:
1770 [AWT-EventQueue-0] INFO Contributors - kotlin: loaded 40 repos
2025 [AWT-EventQueue-0] INFO Contributors - kotlin-examples: loaded 23 contributors
2229 [AWT-EventQueue-0] INFO Contributors - kotlin-koans: loaded 45 contributors
...- Mục đầu tiên trên mỗi dòng là số mili giây đã trôi qua kể từ khi chương trình bắt đầu, sau đó là tên luồng trong dấu ngoặc vuông. Bạn có thể thấy từ luồng nào yêu cầu tải dữ liệu.
- Mục cuối cùng trên mỗi dòng là thông báo thực tế: đã tải bao nhiêu kho lưu trữ hoặc người đóng góp.
Đầu ra log này chứng minh rằng tất cả kết quả đều được đăng nhập từ luồng chính. Khi bạn chạy mã với tùy chọn BLOCKING, cửa sổ đóng băng và không phản ứng đối với đầu vào cho đến khi quá trình tải hoàn thành. Tất cả các yêu cầu được thực hiện từ cùng một luồng như luồng gọi loadContributorsBlocking(), đó là luồng giao diện người dùng chính (trong Swing, đó là luồng phân phối sự kiện AWT). Luồng chính này bị chặn và đó là lý do tại sao giao diện người dùng đóng băng:
Sau khi danh sách người đóng góp đã được tải, kết quả được cập nhật.
4. Trong src/contributors/Contributors.kt, tìm hàm loadContributors() chịu trách nhiệm chọn cách người đóng góp được tải và xem cách loadContributorsBlocking() được gọi:
when (getSelectedVariant()) {
BLOCKING -> { // Blocking UI thread
val users = loadContributorsBlocking(service, req)
updateResults(users, startTime)
}
}- gọi
updateResults()diễn ra ngay sau cuộc gọiloadContributorsBlocking(). updateResults()cập nhật giao diện người dùng, nên nó luôn phải được gọi từ luồng UI.- Vì
loadContributorsBlocking()cũng được gọi từ luồng UI, luồng UI trở thành bị chặn và giao diện người dùng đóng băng.
Bài tập 1
Nhiệm vụ đầu tiên giúp bạn làm quen với lĩnh vực công việc. Hiện tại, tên mỗi người đóng góp được lặp lại nhiều lần, một lần cho mỗi dự án họ tham gia. Thực hiện hàm aggregate() để kết hợp người dùng sao cho mỗi người đóng góp chỉ được thêm một lần. Thuộc tính User.contributions nên chứa tổng số đóng góp của người dùng đã cho tất cả các dự án. Danh sách kết quả nên được sắp xếp theo số đóng góp giảm dần.
Mở src/tasks/Aggregation.kt và thực hiện hàm List.aggregate(). Người dùng nên được sắp xếp theo tổng số đóng góp của họ.
Tệp kiểm thử tương ứng test/tasks/AggregationKtTest.kt hiển thị một ví dụ về kết quả mong đợi.
Bạn có thể chuyển đổi giữa mã nguồn và lớp kiểm thử tự động bằng cách sử dụng tắt IntelliJ IDEA Ctrl+Shift+T / ⇧ ⌘ T.
Sau khi thực hiện nhiệm vụ này, danh sách kết quả cho tổ chức “kotlin” nên giống như sau: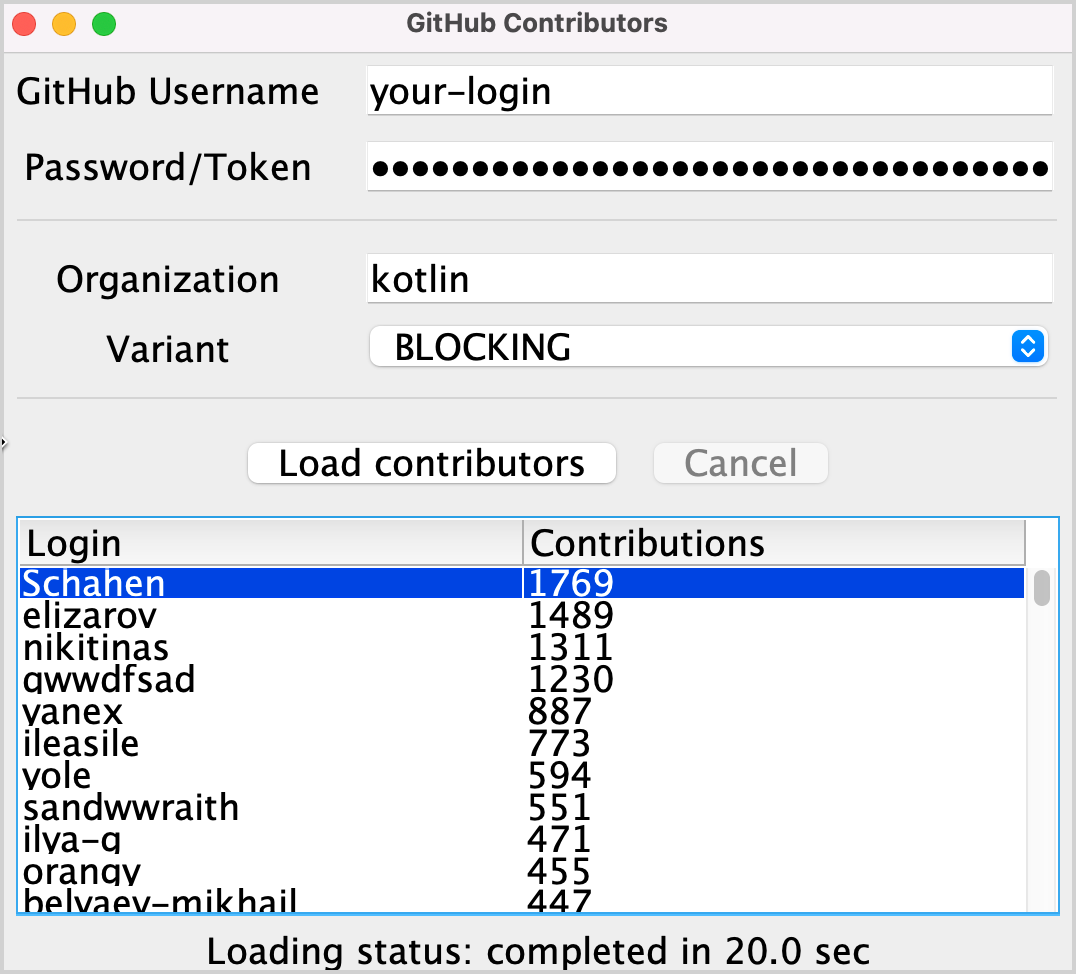
Giải pháp cho bài tập 1
- Để nhóm người dùng theo tên đăng nhập, sử dụng groupBy(), trả về một bản đồ từ một tên đăng nhập đến tất cả các lần xuất hiện của người dùng có tên đăng nhập này trong các kho lưu trữ khác nhau.
- Đối với mỗi mục bản đồ, đếm tổng số đóng góp cho mỗi người dùng và tạo một thể hiện mới của lớp
Usertheo tên và tổng số đóng góp đã cho. - Sắp xếp danh sách kết quả theo thứ tự giảm dần:
fun List<User>.aggregate(): List<User> =
groupBy { it.login }
.map { (login, group) -> User(login, group.sumOf { it.contributions }) }
.sortedByDescending { it.contributions }Một giải pháp thay thế là sử dụng groupingBy() thay vì groupBy().
5. Callbacks
Giải pháp trước đó hoạt động, nhưng nó chặn luồng và do đó đóng băng giao diện người dùng. Một cách tiếp cận truyền thống để tránh điều này là sử dụng callbacks.
Thay vì gọi mã nên được gọi ngay sau khi hoạt động hoàn tất, bạn có thể trích xuất nó vào một callback riêng, thường là một lambda, và chuyển lambda đó cho người gọi để nó sẽ được gọi sau đó.
Để làm cho giao diện người dùng phản ứng, bạn có thể di chuyển toàn bộ tính toán sang một luồng riêng hoặc chuyển sang API Retrofit sử dụng callbacks thay vì cuộc gọi chặn.
5.1 Sử dụng một luồng nền
- Mở
src/tasks/Request2Background.ktvà xem cách nó được triển khai. Trước hết, toàn bộ tính toán được chuyển sang một luồng khác. Hàmthread()khởi động một luồng mới:
thread {
loadContributorsBlocking(service, req)
}Bây giờ khi toàn bộ quá trình tải đã được chuyển sang một luồng riêng, luồng chính không bị ràng buộc và có thể được chiếm bởi các công việc khác:
1.Chữ ký của hàm loadContributorsBackground() thay đổi. Nó nhận một callback updateResults() như là đối số cuối cùng để gọi nó sau khi toàn bộ quá trình tải hoàn thành:
fun loadContributorsBackground(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
)2.Bây giờ khi gọi loadContributorsBackground(), cuộc gọi updateResults() diễn ra trong callback, không phải ngay sau đó như trước:
loadContributorsBackground(service, req) { users ->
SwingUtilities.invokeLater {
updateResults(users, startTime)
}
}
3.Bằng cách gọi SwingUtilities.invokeLater, bạn đảm bảo rằng cuộc gọi updateResults(), cập nhật kết quả, diễn ra trên luồng chính UI (luồng phân phối sự kiện AWT).
Tuy nhiên, nếu bạn cố gắng tải người đóng góp qua tùy chọn BACKGROUND, bạn sẽ thấy danh sách được cập nhật nhưng không có gì thay đổi.
Bài tập 2
Sửa hàm loadContributorsBackground() trong src/tasks/Request2Background.kt để danh sách kết quả được hiển thị trên giao diện người dùng.
Giải pháp cho bài tập 2
Nếu bạn cố gắng tải người đóng góp, bạn có thể thấy trong log rằng người đóng góp đã được tải nhưng kết quả không được hiển thị. Để khắc phục điều này, gọi updateResults() trên danh sách kết quả của người dùng:
thread {
updateResults(loadContributorsBlocking(service, req))
}
Đảm bảo gọi logic được truyền trong callback một cách rõ ràng. Nếu không, không có gì xảy ra.
5.2 Sử dụng API gọi Retrofit
Trong giải pháp trước đó, toàn bộ logic tải được chuyển sang luồng nền, nhưng vẫn không phải là cách tốt nhất sử dụng tài nguyên. Tất cả các yêu cầu tải được thực hiện theo thứ tự và luồng bị chặn trong khi đợi kết quả tải, trong khi nó có thể đã bị chiếm bởi các công việc khác. Cụ thể, luồng có thể bắt đầu tải yêu cầu khác để nhận kết quả toàn bộ sớm hơn.
Xử lý dữ liệu cho mỗi kho lưu trữ sau đó nên được chia thành hai phần: tải và xử lý kết quả nhận được. Phần xử lý thứ hai nên được trích xuất thành một callback.
Việc tải cho mỗi kho lưu trữ sau đó có thể được bắt đầu trước khi nhận kết quả cho kho lưu trữ trước đó (và callback tương ứng được gọi):
API gọi Retrofit có thể giúp đạt được điều này. Hàm Call.enqueue() bắt đầu một yêu cầu HTTP và nhận một callback làm đối số. Trong callback này, bạn cần chỉ định những gì cần thực hiện sau mỗi yêu cầu.
Mở src/tasks/Request3Callbacks.kt và xem cách hàm loadContributorsCallbacks() sử dụng API này được triển khai:
fun loadContributorsCallbacks(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
) {
service.getOrgReposCall(req.org).onResponse { responseRepos -> // #1
logRepos(req, responseRepos)
val repos = responseRepos.bodyList()
val allUsers = mutableListOf<User>()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers -> // #2
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
}
}
}
// TODO: Why doesn't this code work? How to fix that?
updateResults(allUsers.aggregate())
}
* Để thuận tiện, đoạn mã này sử dụng hàm mở rộng onResponse() được khai báo trong cùng một tệp. Nó nhận một lambda làm đối số thay vì biểu diễn đối tượng.
* Logic xử lý các phản hồi được trích xuất thành các callback: các lambda tương ứng bắt đầu từ dòng #1 và #2.
Tuy nhiên, giải pháp đã được cung cấp không hoạt động. Nếu bạn chạy chương trình và tải người đóng góp bằng cách chọn tùy chọn CALLBACKS, bạn sẽ thấy không có gì được hiển thị. Tuy nhiên, các bài kiểm tra trả kết quả ngay lập tức đều thành công.
Hãy suy nghĩ về lý do tại sao mã đã cho không hoạt động như mong đợi và thử sửa hoặc xem các giải pháp dưới đây.
Bài tập 3
Viết lại mã trong tệp src/tasks/Request3Callbacks.kt để danh sách người đóng góp được hiển thị.
Giải pháp thứ 1 bài tập 3
Trong giải pháp hiện tại, nhiều yêu cầu được bắt đầu đồng thời, làm giảm thời gian tải tổng cộng. Tuy nhiên, kết quả không được tải. Điều này xảy ra vì callback updateResults() được gọi ngay sau khi tất cả các yêu cầu tải được bắt đầu, trước khi danh sách allUsers đã được điền đầy dữ liệu.
Bạn có thể thử sửa chữa điều này với một thay đổi như sau:
val allUsers = mutableListOf<User>()
for ((index, repo) in repos.withIndex()) { // #1
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (index == repos.lastIndex) { // #2
updateResults(allUsers.aggregate())
}
}
}
* Đầu tiên, bạn lặp qua danh sách các kho lưu trữ với một chỉ số (#1).
* Sau đó, từ mỗi callback, bạn kiểm tra xem đó có phải là lần lặp cuối cùng không (#2).
* Và nếu đúng vậy, kết quả sẽ được cập nhật.
Tuy nhiên, đoạn mã này cũng không đạt được mục tiêu của chúng ta. Hãy thử tìm câu trả lời một cách tự nghiên cứu, hoặc xem giải pháp dưới đây.
Giải pháp thử nghiệm thứ hai cho bài tập 3
Vì các yêu cầu tải được bắt đầu đồng thời, không có đảm bảo rằng kết quả của yêu cầu cuối cùng sẽ đến sau cùng. Kết quả có thể đến theo bất kỳ thứ tự nào.
Do đó, nếu bạn so sánh chỉ số hiện tại với lastIndex như một điều kiện để hoàn thành, bạn rủi ro mất kết quả cho một số kho lưu trữ.
Nếu yêu cầu xử lý kho lưu trữ cuối cùng trả về nhanh hơn một số yêu cầu trước đó (điều này có khả năng xảy ra), tất cả các kết quả cho các yêu cầu mất thời gian sẽ bị mất.
Một cách để sửa chữa điều này là giới thiệu một chỉ số và kiểm tra xem tất cả các kho lưu trữ đã được xử lý chưa:
val allUsers = Collections.synchronizedList(mutableListOf<User>())
val numberOfProcessed = AtomicInteger()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (numberOfProcessed.incrementAndGet() == repos.size) {
updateResults(allUsers.aggregate())
}
}
}
Đoạn mã này sử dụng một phiên bản đồng bộ của danh sách và AtomicInteger() vì, nói chung, không đảm bảo rằng các callback khác nhau xử lý các yêu cầu getRepoContributors() sẽ luôn được gọi từ cùng một luồng.
Giải pháp thử nghiệm thứ ba cho bài tập 3
Một giải pháp tốt hơn là sử dụng lớp CountDownLatch. Nó lưu trữ một bộ đếm được khởi tạo với số lượng kho lưu trữ. Bộ đếm này giảm đi sau khi xử lý mỗi kho lưu trữ. Sau đó, nó đợi cho đến khi đếm lên đến không trước khi cập nhật kết quả:
val countDownLatch = CountDownLatch(repos.size)
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
// processing repository
countDownLatch.countDown()
}
}
countDownLatch.await()
updateResults(allUsers.aggregate())
Kết quả sau đó được cập nhật từ luồng chính. Điều này trực tiếp hơn là ủy quyền logic cho các luồng con.
Sau khi xem xét ba cố gắng giải pháp này, bạn có thể thấy việc viết mã chính xác với callbacks là không trivial và dễ gặp lỗi, đặc biệt khi có nhiều luồng cơ bản và đồng bộ hóa xảy ra.
Là một bài tập bổ sung, bạn có thể triển khai cùng logic bằng cách sử dụng một phương pháp reactive với thư viện RxJava. Tất cả các phụ thuộc và giải pháp cần thiết để sử dụng RxJava có thể được tìm thấy trong một nhánh rx riêng biệt. Bạn cũng có thể hoàn thành hướng dẫn này và triển khai hoặc kiểm tra các phiên bản Rx được đề xuất để so sánh một cách chính xác.
6. Hàm tạm dừng(Suspending functions)
Bạn có thể triển khai cùng logic bằng cách sử dụng các hàm treo. Thay vì trả về Call<list></list, định nghĩa cuộc gọi API như một hàm treo như sau:
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): List<Repo>
}
* getOrgRepos() được định nghĩa là một hàm suspend. Khi bạn sử dụng một hàm treo để thực hiện một yêu cầu, luồng cơ bản không bị chặn. Thêm chi tiết về cách điều này hoạt động sẽ được mô tả trong các phần sau.
* getOrgRepos() trả kết quả trực tiếp thay vì trả về một Call. Nếu kết quả không thành công, một ngoại lệ được ném.
Theo cách khác, Retrofit cho phép trả kết quả được bao bọc trong Response. Trong trường hợp này, cơ thể kết quả được cung cấp và có thể kiểm tra lỗi bằng cách thủ công. Hướng dẫn này sử dụng các phiên bản trả về Response.
Trong src/contributors/GitHubService.kt, thêm các khai báo sau vào giao diện GitHubService:
interface GitHubService {
// getOrgReposCall & getRepoContributorsCall declarations
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): Response<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
suspend fun getRepoContributors(
@Path("owner") owner: String,
@Path("repo") repo: String
): Response<List<User>>
}Bài tập 4
Nhiệm vụ của bạn là thay đổi mã của hàm tải người đóng góp để sử dụng hai hàm treo mới, getOrgRepos() và getRepoContributors(). Hàm mới loadContributorsSuspend() được đánh dấu là suspend để sử dụng API mới.
Hàm treo không thể được gọi ở mọi nơi. Gọi một hàm treo từ loadContributorsBlocking() sẽ gây ra lỗi với thông báo Hàm treo ‘getOrgRepos’ chỉ nên được gọi từ một coroutine hoặc một hàm treo khác.
1. Sao chép mã hiện thực của loadContributorsBlocking() được định nghĩa trong src/tasks/Request1Blocking.kt vào loadContributorsSuspend() được định nghĩa trong src/tasks/Request4Suspend.kt.
2. Sửa mã để sử dụng các hàm treo mới thay vì các hàm trả về Call.
3. Chạy chương trình bằng cách chọn tùy chọn SUSPEND và đảm bảo rằng giao diện người dùng vẫn đáp ứng trong khi các yêu cầu GitHub được thực hiện.
Giải pháp cho bài tập 4
Thay thế .getOrgReposCall(req.org).execute() bằng .getOrgRepos(req.org) và lặp lại việc thay thế tương tự cho yêu cầu “contributors” thứ hai:
suspend fun loadContributorsSuspend(service: GitHubService, req: RequestData): List<User> {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
return repos.flatMap { repo ->
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}.aggregate()
}
* loadContributorsSuspend() nên được định nghĩa là một hàm suspend.
* Bạn không còn cần gọi execute, trước đây là trả về Response, vì bây giờ các hàm API trả Response trực tiếp. Lưu ý rằng chi tiết này là đặc biệt cho thư viện Retrofit. Với các thư viện khác, API sẽ khác nhau, nhưng khái niệm là giống nhau.
7. Coroutines
Mã với các hàm tạm dùng trông giống với phiên bản “blocking”. Sự khác biệt chính so với phiên bản blocking là thay vì chặn luồng, coroutine bị treo:textblock -> suspend
thread -> coroutine
Coroutines thường được gọi là các luồng nhẹ vì bạn có thể chạy mã trên coroutines, tương tự như cách bạn chạy mã trên các luồng. Các hoạt động trước đây làm chặn (và phải tránh) có thể treo coroutine thay vì.
7.1 Bắt đầu một coroutine mới
Nếu bạn nhìn vào cách loadContributorsSuspend() được sử dụng trong src/contributors/Contributors.kt, bạn có thể thấy rằng nó được gọi bên trong launch. launch là một hàm thư viện nhận một lambda làm đối số:
launch {
val users = loadContributorsSuspend(req)
updateResults(users, startTime)
}
Ở đây, launch bắt đầu một tính toán mới chịu trách nhiệm cho việc tải dữ liệu và hiển thị kết quả. Tính toán này có thể bị treo – khi thực hiện yêu cầu mạng, nó sẽ bị treo và giải phóng luồng cơ bản. Khi yêu cầu mạng trả kết quả, tính toán sẽ tiếp tục.
Một tính toán có thể bị treo như vậy được gọi là một coroutine. Vì vậy, trong trường hợp này, launch bắt đầu một coroutine mới chịu trách nhiệm cho việc tải dữ liệu và hiển thị kết quả.
Coroutines chạy trên đầu các luồng và có thể bị treo. Khi một coroutine bị treo, tính toán tương ứng bị tạm dừng, loại bỏ khỏi luồng và lưu trữ trong bộ nhớ. Trong khi đó, luồng có thể tự do để được chiếm bởi các nhiệm vụ khác: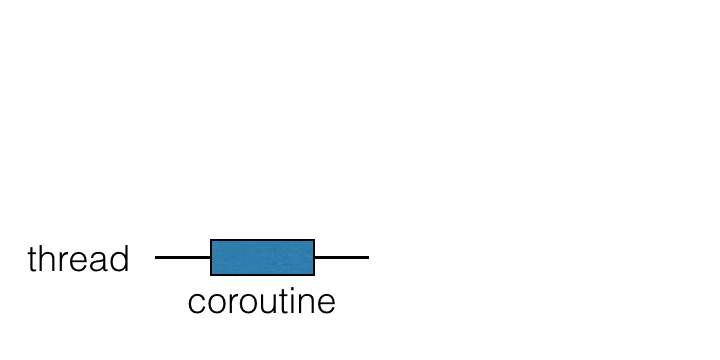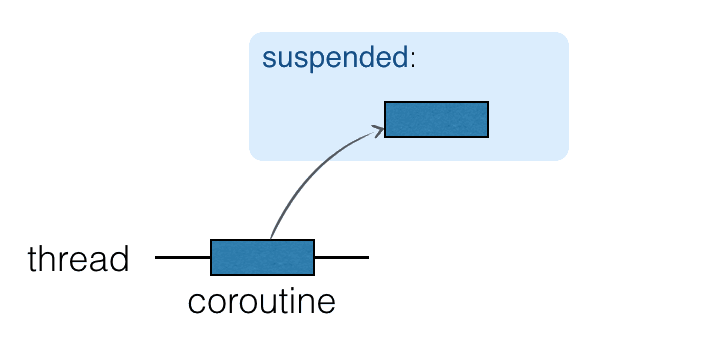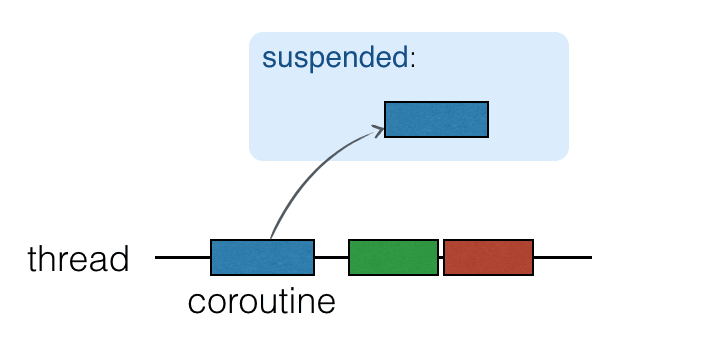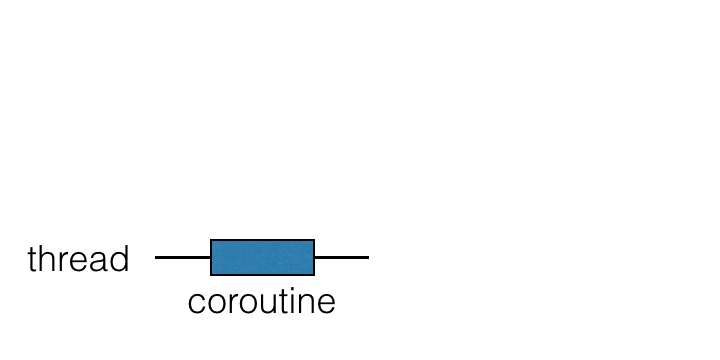
Khi tính toán sẵn sàng để tiếp tục, nó được trả lại cho một luồng (không nhất thiết là cùng một luồng).
Trong ví dụ loadContributorsSuspend(), mỗi yêu cầu “contributors” bây giờ đợi kết quả bằng cách sử dụng cơ chế treo. Đầu tiên, yêu cầu mới được gửi. Sau đó, trong khi đợi phản hồi, toàn bộ coroutine “load contributors” được bắt đầu bởi hàm launch bị treo.
Coroutine chỉ tiếp tục sau khi nhận được phản hồi tương ứng: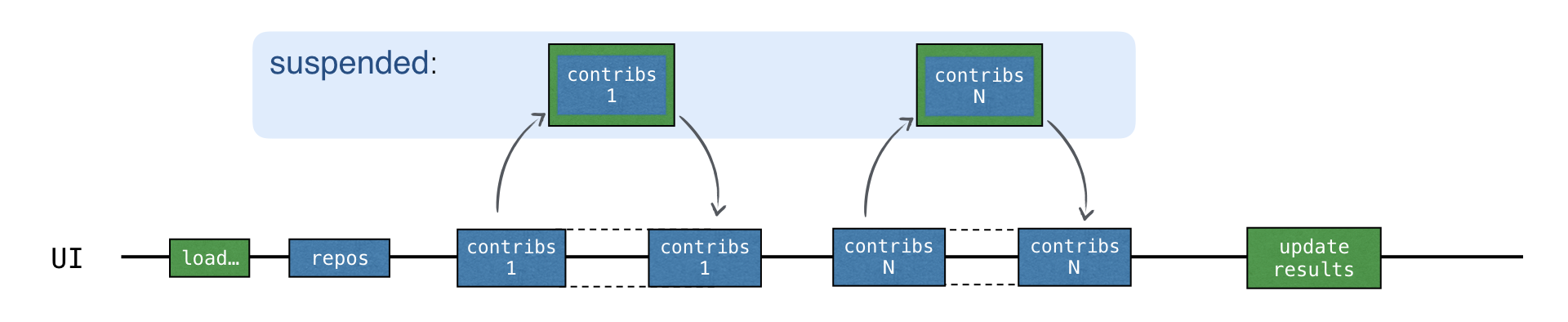
Trong khi phản hồi đang chờ để được nhận, luồng có thể tự do để được chiếm bởi các nhiệm vụ khác. Giao diện người dùng vẫn phản hồi, mặc dù tất cả các yêu cầu đang diễn ra trên luồng chính UI:
1. Chạy chương trình bằng cách sử dụng tùy chọn SUSPEND. Bản ghi xác nhận rằng tất cả các yêu cầu được gửi đến luồng chính UI:
2538 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos
2729 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - ts2kt: loaded 11 contributors
3029 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-koans: loaded 45 contributors
...
11252 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-coroutines-workshop: loaded 1 contributors
2. Bản ghi có thể cho bạn thấy coroutine nào mã tương ứng đang chạy. Để kích hoạt nó, mở Run | Edit configurations
và thêm tùy chọn VM -Dkotlinx.coroutines.debug: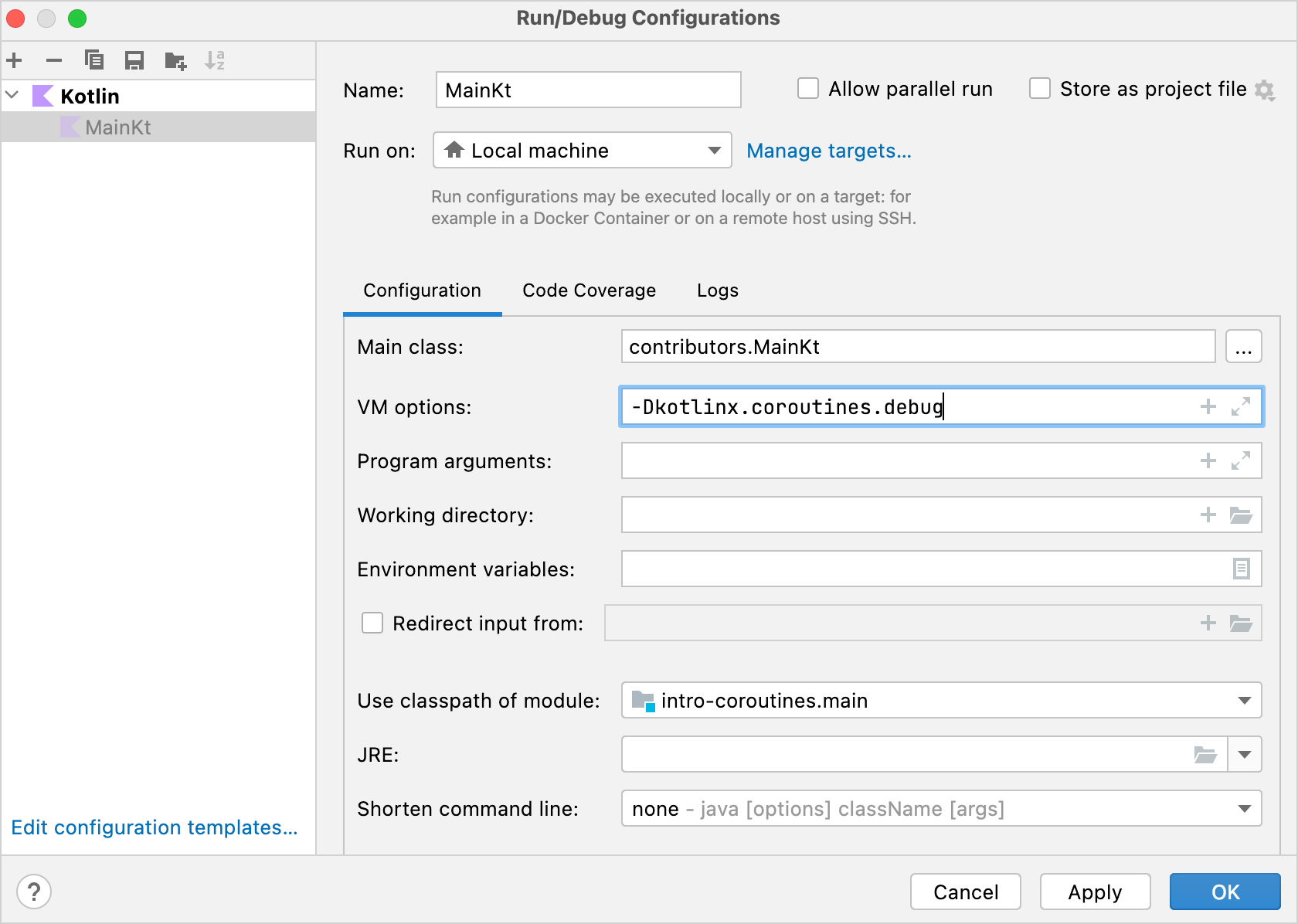
Tên của coroutine sẽ được đính kèm vào tên luồng trong khi main() đang chạy với tùy chọn này. Bạn cũng có thể sửa đổi mẫu để chạy tất cả các tệp Kotlin và bật tùy chọn này mặc định.
Bây giờ, toàn bộ mã chạy trên một coroutine, coroutine “load contributors” được đề cập ở trên, được ký hiệu là @coroutine#1. Trong khi chờ kết quả, bạn không nên sử dụng lại luồng để gửi các yêu cầu khác vì mã được viết theo thứ tự. Yêu cầu mới chỉ được gửi khi kết quả trước đó được nhận.
Hàm tạm dừng không chặn luồng cho “chờ đợi”. Tuy nhiên, điều này chưa mang lại sự song song.
8. Song song(Concurrency)
Coroutine Kotlin tốn ít tài nguyên hơn so với luồng. Mỗi khi bạn muốn bắt đầu một tính toán mới theo cách không đồng bộ, bạn có thể tạo một coroutine mới thay vì.
Để bắt đầu một coroutine mới, sử dụng một trong những coroutine builder chính: launch, async, hoặc runBlocking. Các thư viện khác nhau có thể định nghĩa thêm các coroutine builder.
async bắt đầu một coroutine mới và trả về một đối tượng Deferred. Deferred đại diện cho một khái niệm được biết đến với các tên khác như Future hoặc Promise. Nó lưu trữ một tính toán, nhưng nó hoãn lại thời điểm bạn nhận được kết quả cuối cùng; nó hứa hẹn kết quả đến một tương lai nào đó.
Sự khác biệt chính giữa async và launch là launch được sử dụng để bắt đầu một tính toán mà không cần trả về một kết quả cụ thể. launch trả về một Job đại diện cho coroutine. Có thể đợi cho đến khi nó hoàn thành bằng cách gọi Job.join().
Deferred là một kiểu chung mở rộng từ Job. Một cuộc gọi async có thể trả về một Deferred hoặc Deferred, tùy thuộc vào điều gì lambda trả về (biểu thức cuối cùng trong lambda là kết quả).
Để lấy kết quả của một coroutine, bạn có thể gọi await() trên đối tượng Deferred. Trong khi chờ đợi kết quả, coroutine mà await() được gọi từ đó sẽ bị tạm dừng:
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferred: Deferred<Int> = async {
loadData()
}
println("waiting...")
println(deferred.await())
}
suspend fun loadData(): Int {
println("loading...")
delay(1000L)
println("loaded!")
return 42
}runBlocking được sử dụng như một cầu nối giữa các hàm thông thường và hàm treo, hoặc giữa thế giới chặn và thế giới không chặn. Nó hoạt động như một bộ chuyển đổi để bắt đầu coroutine chính cấp độ cao nhất. Nó được thiết kế chủ yếu để sử dụng trong các hàm main() và các bài kiểm tra
Xem video này để hiểu rõ hơn về coroutines.
Nếu có một danh sách các đối tượng Deferred, bạn có thể gọi awaitAll() để đợi kết quả của tất cả chúng:
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferreds: List<Deferred<Int>> = (1..3).map {
async {
delay(1000L * it)
println("Loading $it")
it
}
}
val sum = deferreds.awaitAll().sum()
println("$sum")
}
Khi mỗi yêu cầu “contributors” được bắt đầu trong một coroutine mới, tất cả các yêu cầu đều được bắt đầu không đồng bộ. Một yêu cầu mới có thể được gửi trước khi kết quả của yêu cầu trước đó được nhận: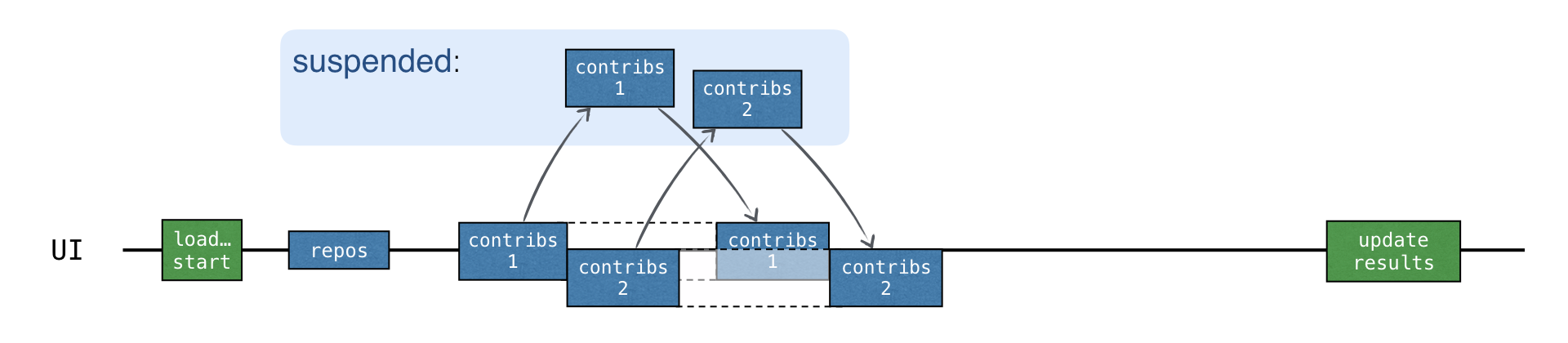
Thời gian tải tổng cộng xấp xỉ giống như trong phiên bản CALLBACKS, nhưng không cần bất kỳ callback nào. Hơn nữa, async làm rõ ràng phần nào chạy song song trong mã.
Bài tập 5
Trong tệp Request5Concurrent.kt, thực hiện một hàm loadContributorsConcurrent() bằng cách sử dụng hàm loadContributorsSuspend() trước đó.
Gợi ý cho bài tập 5
Bạn chỉ có thể bắt đầu một coroutine mới trong phạm vi của một coroutine. Sao chép nội dung từ loadContributorsSuspend() vào cuộc gọi coroutineScope để bạn có thể gọi các hàm async ở đó:
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
// ...
}
Dựa vào giải pháp sau đây:
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
// load contributors for each repo
}
}
deferreds.awaitAll() // List<List<User>>Giải pháp cho bài tập 5
Bọc mỗi yêu cầu contributors bằng async để tạo ra nhiều coroutines như có số lượng repositories. async trả về Deferred<list></list. Điều này không phải là một vấn đề vì việc tạo mới coroutines không tốn nhiều tài nguyên, vì vậy bạn có thể tạo ra bao nhiêu coroutines cần thiết.
1. Bạn không còn có thể sử dụng flatMap vì kết quả của map hiện tại là một danh sách các đối tượng Deferred, không phải là một danh sách các danh sách. awaitAll() trả về List<list></list, vì vậy gọi flatten().aggregate() để lấy kết quả:
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}
}
deferreds.awaitAll().flatten().aggregate()
}2. Chạy mã và kiểm tra log. Tất cả các coroutines vẫn chạy trên luồng giao diện người dùng chính vì đa luồng vẫn chưa được sử dụng, nhưng bạn đã có thể thấy được lợi ích của việc chạy coroutines một cách song song.
3. Để thay đổi mã này để chạy coroutines “contributors” trên các luồng khác nhau từ bộ xử lý luồng chung, hãy chỉ định Dispatchers.Default làm đối số ngữ cảnh cho hàm async:
async(Dispatchers.Default) { }
* CoroutineDispatcher xác định luồng hoặc các luồng mà coroutine tương ứng nên chạy trên. Nếu bạn không chỉ định nó như một đối số, async sẽ sử dụng bộ xử lý từ phạm vi bên ngoài. Dispatchers.Default đại diện cho một bể luồng chia sẻ trên JVM. Bể luồng này cung cấp một cách để thực hiện song song. Nó bao gồm nhiều luồng bằng số lượng lõi CPU có sẵn, nhưng nó vẫn có hai luồng nếu chỉ có một lõi.
4. Sửa mã trong hàm loadContributorsConcurrent() để bắt đầu coroutines mới trên các luồng khác nhau từ bể luồng chung. Ngoài ra, thêm log thêm trước khi gửi yêu cầu:
async(Dispatchers.Default) {
log("starting loading for ${repo.name}")
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}
5. Chạy chương trình một lần nữa. Trong log, bạn có thể thấy mỗi coroutine có thể được bắt đầu trên một luồng từ bể luồng và tiếp tục trên một luồng khác:
1946 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
1946 [DefaultDispatcher-worker-3 @coroutine#5] INFO Contributors - starting loading for dokka
1946 [DefaultDispatcher-worker-1 @coroutine#3] INFO Contributors - starting loading for ts2kt
...
2178 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors
2569 [DefaultDispatcher-worker-1 @coroutine#5] INFO Contributors - dokka: loaded 36 contributors
2821 [DefaultDispatcher-worker-2 @coroutine#3] INFO Contributors - ts2kt: loaded 11 contributors
Ví dụ, trong đoạn log này, coroutine#4 được bắt đầu trên luồng worker-2 và tiếp tục trên luồng worker-1.
Trong src/contributors/Contributors.kt, kiểm tra triển khai của tùy chọn CONCURRENT:
1. Để chạy coroutine chỉ trên luồng giao diện người dùng chính, chỉ định Dispatchers.Main làm đối số:
launch(Dispatchers.Main) {
updateResults()
}- Nếu luồng chính bận khi bạn bắt đầu một coroutine mới trên nó, coroutine sẽ trở thành bị đình chỉ và được xếp lịch để thực hiện trên luồng này. Coroutine chỉ tiếp tục khi luồng trở nên rảnh.
- Điều này được xem là thực hành tốt để sử dụng dispatcher từ phạm vi bên ngoài thay vì chỉ định một cách rõ ràng ở mỗi điểm cuối. Nếu bạn định nghĩa
loadContributorsConcurrent()mà không truyềnDispatchers.Defaultlàm đối số, bạn có thể gọi hàm này trong bất kỳ ngữ cảnh nào: với dispatcherDefault, với luồng giao diện người dùng chính hoặc với dispatcher tùy chỉnh. - Như bạn sẽ thấy sau, khi gọi
loadContributorsConcurrent()từ các bài kiểm tra, bạn có thể gọi nó trong ngữ cảnh vớiTestDispatcher, giúp đơn giản hóa quá trình kiểm thử. Điều này khiến giải pháp này linh hoạt hơn nhiều.
2. Để chỉ định dispatcher ở phía người gọi, thực hiện thay đổi sau đây cho dự án trong khi đểloadContributorsConcurrentbắt đầu các coroutine trong ngữ cảnh được kế thừa:
launch(Dispatchers.Default) {
val users = loadContributorsConcurrent(service, req)
withContext(Dispatchers.Main) {
updateResults(users, startTime)
}
}updateResults()nên được gọi trên luồng giao diện người dùng chính, vì vậy bạn gọi nó với ngữ cảnhDispatchers.Main.withContext()gọi mã đã cho với ngữ cảnh coroutine được chỉ định, bị đình chỉ cho đến khi hoàn thành và trả lại kết quả. Một cách thay thế nhưng dài dòng hơn để diễn đạt điều này sẽ là bắt đầu một coroutine mới và một cách rõ ràng đợi (bằng cách đình chỉ) cho đến khi nó hoàn thành:launch(context) { ... }.join().
3. Chạy mã và đảm bảo rằng các coroutine được thực hiện trên các luồng từ bể luồng.
9.Cấu trúc Coroutine
- Coroutine scope chịu trách nhiệm về cấu trúc và mối quan hệ cha-con giữa các coroutine khác nhau. Thông thường, coroutine mới cần được bắt đầu trong một phạm vi.
- Coroutine context lưu trữ thông tin kỹ thuật bổ sung được sử dụng để chạy một coroutine cụ thể, như tên tùy chỉnh của coroutine, hoặc dispatcher chỉ định luồng mà coroutine nên được lên lịch.
Khilaunch,async, hoặcrunBlockingđược sử dụng để bắt đầu một coroutine mới, chúng tự động tạo ra phạm vi tương ứng. Tất cả các hàm này đều nhận một lambda với một receiver làm đối số, vàCoroutineScopelà kiểu receiver ngầm định:
launch { /* this: CoroutineScope */ }- Coroutine mới chỉ có thể được bắt đầu trong một phạm vi.
launchvàasyncđược khai báo như là các extension củaCoroutineScope, vì vậy luôn phải truyền một receiver ngầm định hoặc rõ ràng khi bạn gọi chúng.- Coroutine bắt đầu bởi
runBlockinglà ngoại lệ duy nhất vìrunBlockingđược định nghĩa là một hàm top-level. Nhưng vì nó chặn luồng hiện tại, nó được dùng chủ yếu trong các hàmmain()và các bài kiểm tra như một hàm cầu nối.
Coroutine mới trongrunBlocking,launch, hoặcasynctự động bắt đầu trong phạm vi:
import kotlinx.coroutines.*
fun main() = runBlocking { /* this: CoroutineScope */
launch { /* ... */ }
// the same as:
this.launch { /* ... */ }
}Khi bạn gọi launch bên trong runBlocking, nó được gọi như là một extension của receiver ngầm định có kiểu CoroutineScope. Theo cách tương tự, bạn có thể viết rõ ràng this.launch.
Coroutine lồng (bắt đầu bởi launch trong ví dụ này) có thể được xem xét như một con của coroutine bên ngoại (bắt đầu bởi runBlocking). Mối quan hệ “cha-con” này hoạt động qua các phạm vi; coroutine con được bắt đầu từ phạm vi tương ứng với coroutine cha.
Có thể tạo một phạm vi mới mà không cần bắt đầu một coroutine mới, bằng cách sử dụng hàm coroutineScope. Để bắt đầu coroutine mới một cách có tổ chức bên trong một hàm suspend mà không có quyền truy cập vào phạm vi bên ngoại, bạn có thể tạo một phạm vi coroutine mới mà tự động trở thành con của phạm vi bên ngoại mà hàm suspend này được gọi từ đó. loadContributorsConcurrent() là một ví dụ tốt.
Bạn cũng có thể bắt đầu một coroutine mới từ phạm vi toàn cầu bằng cách sử dụng GlobalScope.async hoặc GlobalScope.launch. Điều này sẽ tạo ra một coroutine cấp cao “độc lập”.
Cơ chế đằng sau cấu trúc của coroutines được gọi là structured concurrency. Nó cung cấp các lợi ích sau so với phạm vi toàn cầu:
- Phạm vi thông thường chịu trách nhiệm cho các coroutine con, có tuổi thọ được gắn liền với tuổi thọ của phạm vi đó.
- Phạm vi có thể tự động hủy bỏ các coroutine con nếu có điều gì đó không ổn hoặc người dùng thay đổi ý định và quyết định thu hồi hoạt động.
- Phạm vi tự động đợi hoàn thành của tất cả các coroutine con. Do đó, nếu phạm vi tương ứng với một coroutine, coroutine cha không hoàn thành cho đến khi tất cả các coroutine được khởi chạy trong phạm vi của nó hoàn thành.
Khi sử dụng GlobalScope.async, không có cấu trúc nào kết nối nhiều coroutine với một phạm vi nhỏ hơn. Coroutines bắt đầu từ phạm vi toàn cầu đều độc lập – tuổi thọ của chúng chỉ giới hạn bởi tuổi thọ của toàn bộ ứng dụng. Có thể lưu trữ một tham chiếu đến coroutine bắt đầu từ phạm vi toàn cầu và đợi cho đến khi nó hoàn thành hoặc hủy nó một cách rõ ràng, nhưng điều này không xảy ra tự động như trong structured concurrency.
9.1 Hủy tải danh sách người đóng góp
Tạo hai phiên bản của hàm tải danh sách người đóng góp. So sánh cách hai phiên bản hoạt động khi bạn cố gắng hủy bỏ coroutine cha. Phiên bản đầu tiên sẽ sử dụng coroutineScope để bắt đầu tất cả các coroutine con, trong khi phiên bản thứ hai sẽ sử dụng GlobalScope.
1. Trong Request5Concurrent.kt, thêm độ trễ 3 giây vào hàm loadContributorsConcurrent():
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
// ...
async {
log("starting loading for ${repo.name}")
delay(3000)
// load repo contributors
}
// ...
}
Độ trễ ảnh hưởng đến tất cả các coroutine gửi yêu cầu, để có đủ thời gian hủy tải sau khi coroutine được bắt đầu nhưng trước khi yêu cầu được gửi đi.
2. Tạo phiên bản thứ hai của hàm tải: sao chép triển khai của loadContributorsConcurrent() sang loadContributorsNotCancellable() trong Request5NotCancellable.kt và sau đó loại bỏ việc tạo một coroutineScope mới. 3. Các cuộc gọi async hiện không thể giải quyết, vì vậy bắt đầu chúng bằng cách sử dụng GlobalScope.async:
suspend fun loadContributorsNotCancellable(
service: GitHubService,
req: RequestData
): List<User> { // #1
// ...
GlobalScope.async { // #2
log("starting loading for ${repo.name}")
// load repo contributors
}
// ...
return deferreds.awaitAll().flatten().aggregate() // #3
}
* Hàm bây giờ trả kết quả trực tiếp, không phải là biểu thức cuối cùng trong lambda (dòng #1 và #3).
* Tất cả coroutine “contributors” đều được bắt đầu trong GlobalScope, không phải là con của phạm vi coroutine (dòng #2).
4. Chạy chương trình và chọn tùy chọn CONCURRENT để tải người đóng góp. 5. Đợi cho đến khi tất cả các coroutine “contributors” được bắt đầu, sau đó nhấp vào
Cancel. Log không hiển thị kết quả mới, điều này có nghĩa là tất cả các yêu cầu thực sự đã bị hủy bỏ:
2896 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 40 repos
2901 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
...
2909 [DefaultDispatcher-worker-5 @coroutine#36] INFO Contributors - starting loading for mpp-example
/* click on 'cancel' */
/* no requests are sent *//
6. Lặp lại bước 5, nhưng lần này chọn tùy chọn NOT_CANCELLABLE:
2570 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos
2579 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
...
2586 [DefaultDispatcher-worker-6 @coroutine#36] INFO Contributors - starting loading for mpp-example
/* click on 'cancel' */
/* but all the requests are still sent: */
6402 [DefaultDispatcher-worker-5 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors
...
9555 [DefaultDispatcher-worker-8 @coroutine#36] INFO Contributors - mpp-example: loaded 8 contributors
Trong trường hợp này, không có coroutine nào bị hủy bỏ, và tất cả các yêu cầu vẫn được gửi đi.
7. Kiểm tra cách hủy bỏ được kích hoạt trong chương trình “contributors”. Khi nút Cancel được nhấp vào, coroutine “loading” chính được hủy bỏ một cách rõ ràng và các coroutine con sẽ tự động bị hủy bỏ:
interface Contributors {
fun loadContributors() {
// ...
when (getSelectedVariant()) {
CONCURRENT -> {
launch {
val users = loadContributorsConcurrent(service, req)
updateResults(users, startTime)
}.setUpCancellation() // #1
}
}
}
private fun Job.setUpCancellation() {
val loadingJob = this // #2
// cancel the loading job if the 'cancel' button was clicked:
val listener = ActionListener {
loadingJob.cancel() // #3
updateLoadingStatus(CANCELED)
}
// add a listener to the 'cancel' button:
addCancelListener(listener)
// update the status and remove the listener
// after the loading job is completed
}
}Hàm launch trả về một thể hiện của Job. Job lưu trữ một tham chiếu đến “coroutine tải”, chịu trách nhiệm tải tất cả dữ liệu và cập nhật kết quả. Bạn có thể gọi hàm mở rộng setUpCancellation() trên đó (dòng #1), truyền một thể hiện của Job làm bộ nhận.
Một cách khác bạn có thể thể hiện điều này là viết một cách rõ ràng:
val job = launch { }
job.setUpCancellation()* Để dễ đọc, bạn có thể tham chiếu đến bộ nhận của hàm setUpCancellation() bằng biến loadingJob mới (dòng #2).
* Sau đó, bạn có thể thêm một trình nghe cho nút Cancel để khi nó được nhấp vào, loadingJob sẽ bị hủy bỏ (dòng #3).
Với structured concurrency, bạn chỉ cần hủy bỏ coroutine cha và điều này tự động truyền hủy bỏ đến tất cả các coroutine con.
9.2 Sử dụng ngữ cảnh của phạm vi bên ngoài
Khi bạn bắt đầu coroutine mới bên trong phạm vi đã cho, nó dễ dàng hơn để đảm bảo rằng tất cả chúng chạy với cùng một ngữ cảnh. Cũng dễ dàng hơn để thay thế ngữ cảnh nếu cần.
Bây giờ là lúc để tìm hiểu cách sử dụng dispatcher từ ngữ cảnh bên ngoài hoạt động. Phạm vi mới được tạo ra bởi coroutineScope hoặc bởi các builders coroutine luôn kế thừa ngữ cảnh từ phạm vi bên ngoài. Trong trường hợp này, phạm vi bên ngoài là phạm vi mà hàm suspend loadContributorsConcurrent() được gọi từ:
launch(Dispatchers.Default) { // outer scope
val users = loadContributorsConcurrent(service, req)
// ...
}
Tất cả các coroutine lồng nhau được bắt đầu tự động với ngữ cảnh được kế thừa. Dispatcher là một phần của ngữ cảnh này. Đó là lý do tại sao tất cả các coroutine bắt đầu bằng async đều được khởi chạy với ngữ cảnh của dispatcher mặc định:
suspend fun loadContributorsConcurrent(
service: GitHubService, req: RequestData
): List<User> = coroutineScope {
// this scope inherits the context from the outer scope
// ...
async { // nested coroutine started with the inherited context
// ...
}
// ...
}
Với structured concurrency, bạn có thể chỉ định các phần chính của ngữ cảnh (như dispatcher) một lần, khi tạo coroutine cấp cao. Tất cả các coroutine lồng nhau sau đó kế thừa ngữ cảnh và chỉ sửa đổi nếu cần thiết.
Khi bạn viết mã sử dụng coroutine cho ứng dụng UI, ví dụ như ứng dụng Android, đó là một thực hành phổ biến để sử dụng CoroutineDispatchers.Main theo mặc định cho coroutine cấp cao và sau đó rõ ràng chỉ định một dispatcher khác khi bạn cần chạy mã trên một luồng khác.
10. Hiển thị tiến trình
Mặc dù thông tin cho một số kho lưu trữ được tải khá nhanh chóng, người dùng chỉ thấy danh sách kết quả sau khi tất cả dữ liệu đã được tải. Cho đến khi đó, biểu tượng tải chạy hiển thị tiến trình, nhưng không có thông tin về trạng thái hiện tại hoặc những người đóng góp đã được tải.
Bạn có thể hiển thị các kết quả trung gian sớm hơn và hiển thị tất cả các người đóng góp sau khi tải dữ liệu cho mỗi kho lưu trữ:
Để triển khai chức năng này, trong src/tasks/Request6Progress.kt, bạn cần chuyển logic cập nhật UI như một callback, để nó được gọi ở mỗi trạng thái trung gian:
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
// loading the data
// calling `updateResults()` on intermediate states
}
Tại điểm gọi trong Contributors.kt, callback được chuyển để cập nhật kết quả từ luồng Main cho tùy chọn PROGRESS:
launch(Dispatchers.Default) {
loadContributorsProgress(service, req) { users, completed ->
withContext(Dispatchers.Main) {
updateResults(users, startTime, completed)
}
}
}
* Tham số updateResults() được khai báo là suspend trong loadContributorsProgress(). Cần gọi withContext, một hàm suspend bên trong đối số lambda tương ứng.
* Callback updateResults() nhận một tham số Boolean bổ sung làm đối số chỉ định liệu quá trình tải đã hoàn tất và kết quả có phải là cuối cùng không.
Bài 6
Trong tệp Request6Progress.kt, triển khai hàm loadContributorsProgress() hiển thị tiến trình trung gian. Dựa trên hàm loadContributorsSuspend() từ Request4Suspend.kt.
* Sử dụng một phiên bản đơn giản mà không có đồng thời; bạn sẽ thêm nó sau trong phần tiếp theo.
* Danh sách trung gian của người đóng góp nên được hiển thị ở trạng thái “tổng hợp”, không chỉ là danh sách người dùng được tải cho mỗi kho lưu trữ.
* Tổng số đóng góp cho mỗi người dùng nên được tăng khi dữ liệu cho mỗi kho lưu trữ mới được tải.
Giải pháp cho bài 6
Để lưu trữ danh sách trung gian của người đóng góp đã được tải trong trạng thái “tổng hợp”, định nghĩa biến allUsers để lưu trữ danh sách người dùng, sau đó cập nhật nó sau khi người đóng góp cho mỗi kho lưu trữ mới được tải:
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
var allUsers = emptyList<User>()
for ((index, repo) in repos.withIndex()) {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, index == repos.lastIndex)
}
}Liên tục so với đồng thời
Hàm gọi lại updateResults() được gọi sau mỗi yêu cầu hoàn tất: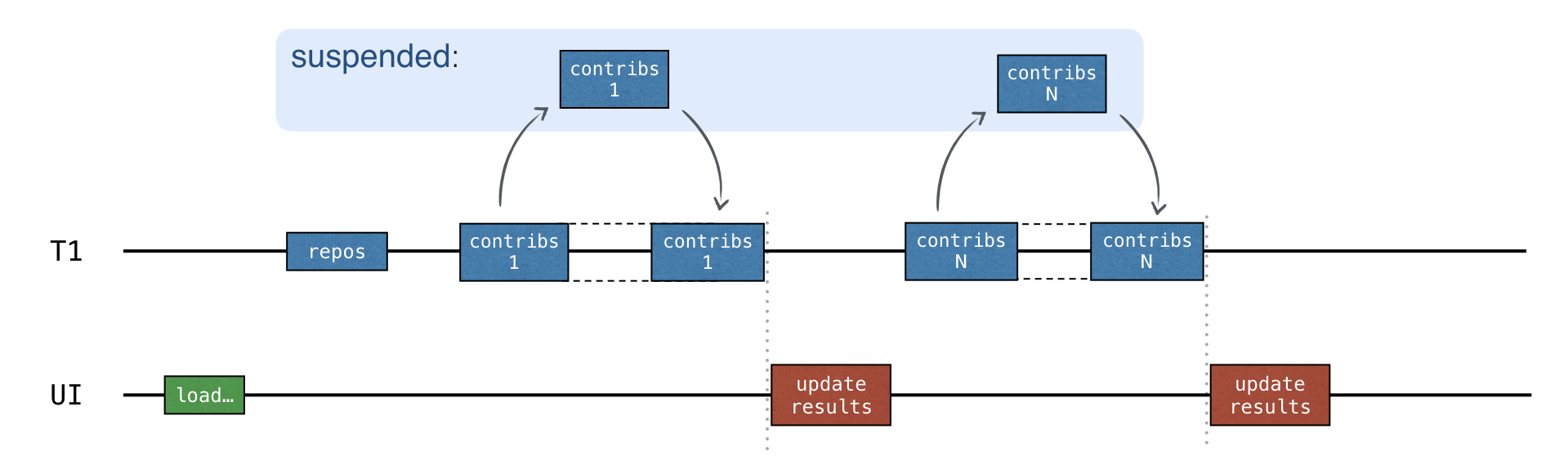
Đoạn mã này không bao gồm đồng thời. Nó tuần tự, nên bạn không cần đồng bộ hóa.
Tùy chọn tốt nhất là gửi yêu cầu đồng thời và cập nhật kết quả trung gian sau khi nhận phản hồi cho mỗi kho lưu trữ: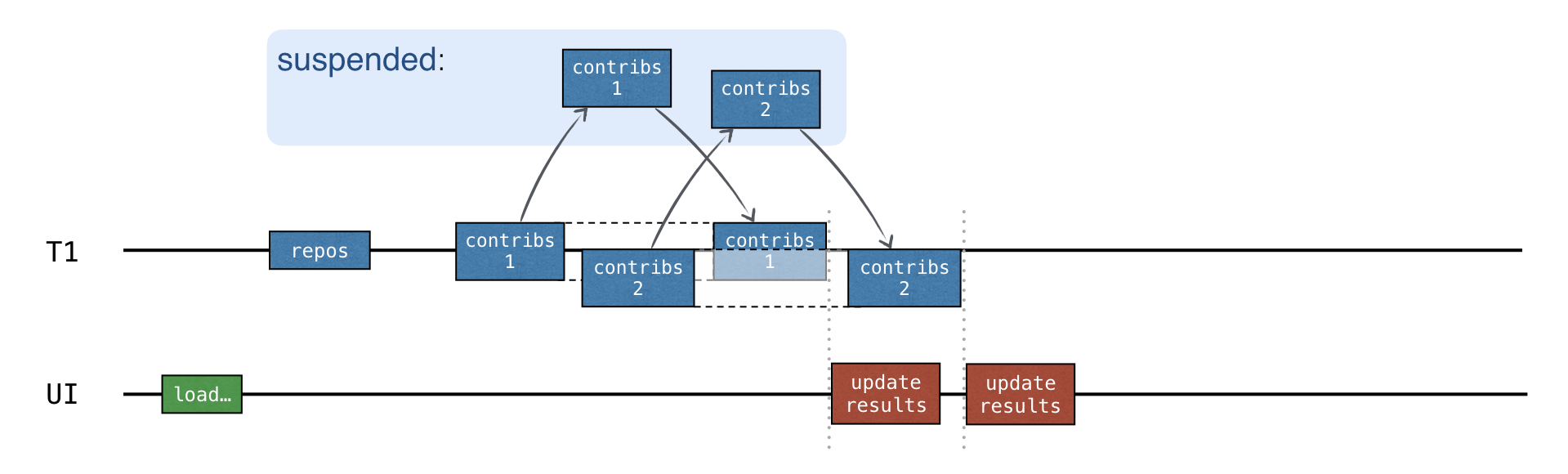
Để thêm đồng thời, sử dụng channels.
11. Channels
Việc viết mã với một trạng thái có thể chia sẻ và có thể thay đổi khá khó khăn và dễ gây lỗi (như trong giải pháp sử dụng callbacks). Một cách đơn giản hơn là chia sẻ thông tin thông qua giao tiếp thay vì sử dụng một trạng thái có thể chia sẻ. Coroutines có thể giao tiếp với nhau thông qua channels.
Channels là nguyên tắc giao tiếp cho phép dữ liệu được truyền giữa các coroutine. Một coroutine có thể gửi một số thông tin đến một channel, trong khi coroutine khác có thể nhận thông tin đó từ nó:
Một coroutine gửi (sản xuất) thông tin thường được gọi là producer, và một coroutine nhận (tiêu thụ) thông tin được gọi là consumer. Một hoặc nhiều coroutine có thể gửi thông tin đến cùng một channel, và một hoặc nhiều coroutine có thể nhận dữ liệu từ nó: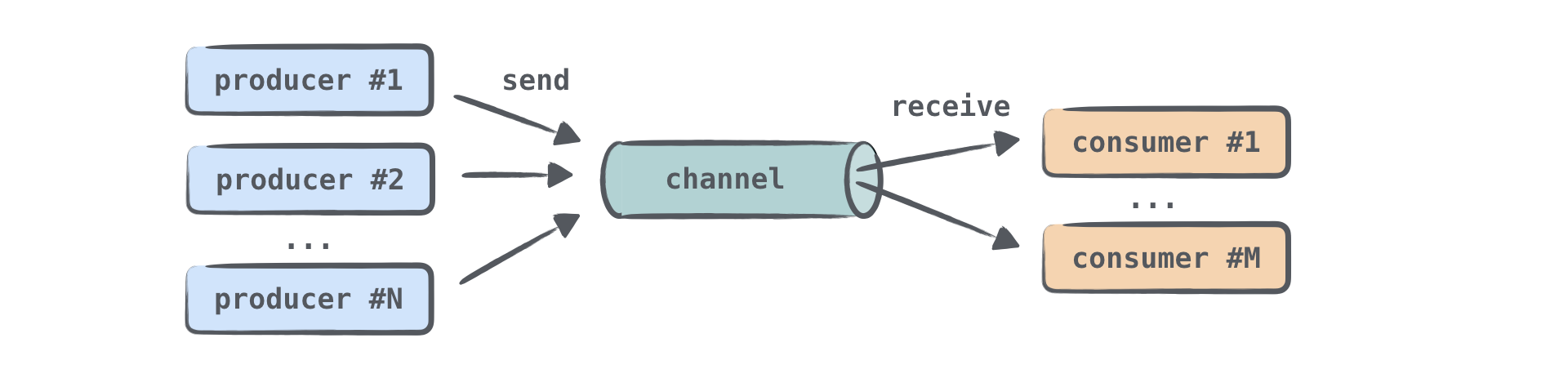
Khi nhiều coroutine nhận thông tin từ cùng một channel, mỗi phần tử chỉ được xử lý một lần bởi một trong những consumer. Một khi một phần tử được xử lý, nó ngay lập tức được loại bỏ khỏi channel.
Bạn có thể nghĩ về một channel như là một bộ sưu tập các phần tử, hoặc chính xác hơn, một hàng đợi, trong đó các phần tử được thêm vào một đầu và được nhận từ đầu kia. Tuy nhiên, có một điểm quan trọng khác biệt: khác với các bộ sưu tập, kể cả trong các phiên bản được đồng bộ hóa của chúng, một channel có thể tạm ngừng các thao tác send() và receive(). Điều này xảy ra khi channel trống hoặc đầy. Channel có thể đầy nếu kích thước của channel có một giới hạn trên.
Channel được đại diện bởi ba giao diện khác nhau: SendChannel, ReceiveChannel và Channel, với giao diện cuối cùng mở rộng hai giao diện đầu tiên. Thông thường, bạn tạo một channel và đưa nó cho producers dưới dạng một thể hiện của SendChannel để chỉ có họ mới có thể gửi thông tin đến channel. Bạn đưa một channel cho consumers dưới dạng một thể hiện của ReceiveChannel để chỉ có họ mới có thể nhận từ nó. Cả hai phương thức send và receive được khai báo là suspend:
interface SendChannel<in E> {
suspend fun send(element: E)
fun close(): Boolean
}
interface ReceiveChannel<out E> {
suspend fun receive(): E
}
interface Channel<E> : SendChannel<E>, ReceiveChannel<E>
Producer có thể đóng một channel để chỉ ra rằng không còn phần tử nào đang đến.
Thư viện định nghĩa nhiều loại channel khác nhau. Chúng khác nhau ở chỗ có bao nhiêu phần tử chúng có thể lưu trữ nội tại và liệu cuộc gọi send() có thể bị tạm ngừng hay không. Đối với tất cả các loại channel, cuộc gọi receive() hoạt động tương tự: nó nhận một phần tử nếu channel không trống; ngược lại, nó bị tạm ngừng.
Kênh không giới hạn
Kênh không giới hạn là kênh tương tự gần nhất với hàng đợi: nhà sản xuất có thể gửi các phần tử đến kênh này và kênh này sẽ tiếp tục phát triển vô thời hạn. Cuộc gọi send() sẽ không bao giờ bị treo. Nếu chương trình hết bộ nhớ, bạn sẽ nhận được Ngoại lệ OutOfMemoryException. Sự khác biệt giữa kênh không giới hạn và hàng đợi là khi người tiêu dùng cố gắng nhận từ một kênh trống, kênh đó sẽ bị treo cho đến khi một số phần tử mới được gửi.
Kênh đệm
Kích thước của kênh đệm bị hạn chế bởi số lượng được chỉ định. Nhà sản xuất có thể gửi các phần tử tới kênh này cho đến khi đạt đến giới hạn kích thước. Tất cả các yếu tố được lưu trữ nội bộ. Khi kênh đã đầy, lệnh gọi `send` tiếp theo trên kênh đó sẽ bị tạm dừng cho đến khi có thêm dung lượng trống.
Kênh hẹn hò
Kênh “Rendezvous” là kênh không có vùng đệm, giống như kênh được đệm có kích thước bằng 0. Một trong các hàm (gửi() hoặc nhận()) luôn bị treo cho đến khi hàm kia được gọi. Nếu hàm send() được gọi và không có cuộc gọi nhận nào bị tạm dừng để xử lý phần tử thì send() sẽ bị treo. Tương tự, nếu hàm nhận được gọi và kênh trống hoặc nói cách khác, không có lệnh gọi send() nào bị treo để gửi phần tử thì lệnh gọi get() sẽ bị tạm dừng. Tên “điểm hẹn” (“một cuộc họp vào thời gian và địa điểm đã thỏa thuận”) đề cập đến thực tế là send() và get() phải “gặp nhau đúng giờ”.
Kênh tổng hợp
Phần tử mới được gửi đến kênh được kết hợp sẽ ghi đè lên phần tử đã gửi trước đó, do đó người nhận sẽ luôn chỉ nhận được phần tử mới nhất. Cuộc gọi send() không bao giờ bị treo.
Khi bạn tạo một channel, hãy chỉ định loại hoặc kích thước bộ đệm (nếu bạn cần một channel có bộ đệm):
val rendezvousChannel = Channel<String>()
val bufferedChannel = Channel<String>(10)
val conflatedChannel = Channel<String>(CONFLATED)
val unlimitedChannel = Channel<String>(UNLIMITED)
Mặc định, một channel “Rendezvous” được tạo ra.
Trong bài tập tiếp theo, bạn sẽ tạo ra một channel “Rendezvous”, hai coroutine nhà sản xuất và một coroutine nhà tiêu dùng:
import kotlinx.coroutines.channels.Channel
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
val channel = Channel<String>()
launch {
channel.send("A1")
channel.send("A2")
log("A done")
}
launch {
channel.send("B1")
log("B done")
}
launch {
repeat(3) {
val x = channel.receive()
log(x)
}
}
}
fun log(message: Any?) {
println("[${Thread.currentThread().name}] $message")
}Xem video này để hiểu rõ hơn về channels.
Bài 7
Trong src/tasks/Request7Channels.kt, triển khai hàm loadContributorsChannels() yêu cầu tất cả các người đóng góp trên GitHub đồng thời và hiển thị tiến trình trung gian cùng một lúc.
Sử dụng các hàm trước đó, loadContributorsConcurrent() từ Request5Concurrent.kt và loadContributorsProgress() từ Request6Progress.kt.
Mẹo cho bài 7
Các coroutine khác nhau đồng thời nhận danh sách người đóng góp cho các kho lưu trữ khác nhau có thể gửi tất cả các kết quả nhận được đến cùng một channel:
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = TODO()
// ...
channel.send(users)
}
}Sau đó, các phần tử từ channel này có thể được nhận một cách tuần tự và được xử lý:
repeat(repos.size) {
val users = channel.receive()
// ...
}
Vì cuộc gọi receive() là tuần tự, không cần đồng bộ hóa bổ sung.
Giải pháp cho bài 7
Như với hàm loadContributorsProgress(), bạn có thể tạo một biến allUsers để lưu trữ trạng thái trung gian của danh sách “tất cả người đóng góp”. Mỗi danh sách mới nhận được từ channel được thêm vào danh sách của tất cả người dùng. Bạn tổng hợp kết quả và cập nhật trạng thái bằng cách sử dụng callback updateResults:
suspend fun loadContributorsChannels(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
channel.send(users)
}
}
var allUsers = emptyList<User>()
repeat(repos.size) {
val users = channel.receive()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, it == repos.lastIndex)
}
}
* Kết quả cho các kho lưu trữ khác nhau được thêm vào channel ngay khi chúng sẵn sàng. Ban đầu, khi tất cả các yêu cầu được gửi đi và không có dữ liệu nào được nhận, cuộc gọi receive() bị tạm ngừng. Trong trường hợp này, toàn bộ coroutine “tải người đóng góp” bị tạm ngừng.
* Sau đó, khi danh sách người dùng được gửi đến channel, coroutine “tải người đóng góp” tiếp tục, cuộc gọi receive() trả về danh sách này, và kết quả được cập nhật ngay lập tức.
Bạn có thể chạy chương trình ngay bây giờ và chọn tùy chọn CHANNELS để tải người đóng góp và xem kết quả.
Mặc dù cả coroutine và channels đều không hoàn toàn loại bỏ sự phức tạp đến từ đồng thời, nhưng chúng giúp cuộc sống dễ dàng hơn khi bạn cần hiểu rõ về những gì đang xảy ra.
12. Kiểm thử coroutines
Hãy kiểm thử tất cả các giải pháp để kiểm tra xem giải pháp với coroutines đồng thời có nhanh hơn so với giải pháp với các hàm suspend, và kiểm tra xem giải pháp với channels có nhanh hơn so với giải pháp đơn giản “tiến trình”.
Trong bài tập tiếp theo, bạn sẽ so sánh thời gian chạy tổng cộng của các giải pháp. Bạn sẽ giả mạo một dịch vụ GitHub và khiến dịch vụ này trả kết quả sau khoảng thời gian đợi nhất định:
repos request - returns an answer within 1000 ms delay
repo-1 - 1000 ms delay
repo-2 - 1200 ms delay
repo-3 - 800 ms delayGiải pháp tuần tự với các hàm suspend nên mất khoảng 4000 ms (4000 = 1000 + (1000 + 1200 + 800)). Giải pháp đồng thời nên mất khoảng 2200 ms (2200 = 1000 + max(1000, 1200, 800)).
Đối với các giải pháp hiển thị tiến trình, bạn cũng có thể kiểm tra các kết quả trung gian với timestamp.
Dữ liệu kiểm thử tương ứng được định nghĩa trong test/contributors/testData.kt, và các tệp Request4SuspendKtTest, Request7ChannelsKtTest, và các tệp khác chứa các bài kiểm thử trực tiếp sử dụng cuộc gọi dịch vụ giả mạo.
Tuy nhiên, có hai vấn đề ở đây:
* Những bài kiểm thử này mất quá nhiều thời gian để chạy. Mỗi bài kiểm thử mất khoảng 2 đến 4 giây, và bạn cần phải chờ kết quả mỗi lần. Điều này không hiệu quả lắm.
* Bạn không thể phụ thuộc vào thời gian cụ thể mà giải pháp chạy vì vẫn mất thêm thời gian để chuẩn bị và chạy mã. Bạn có thể thêm một hằng số, nhưng thời gian sẽ khác nhau từ máy này sang máy khác. Độ trễ của dịch vụ giả mạo nên cao hơn hằng số này để bạn có thể nhìn thấy sự khác biệt. Nếu hằng số là 0,5 giây, thì làm cho độ trễ là 0,1 giây sẽ không đủ.
Một cách tốt hơn là sử dụng các framework đặc biệt để kiểm thử thời gian trong khi chạy cùng mã một số lần (làm tăng thời gian chạy tổng cộng thêm nữa), nhưng đó là phức tạp để học và thiết lập.
Để giải quyết những vấn đề này và đảm bảo rằng các giải pháp với độ trễ kiểm thử cung cấp hoạt động như mong đợi, một giải pháp nhanh hơn giải pháp khác, hãy sử dụng thời gian ảo với một dispatcher kiểm thử đặc biệt. Dispatcher này theo dõi thời gian ảo đã trôi qua từ lúc bắt đầu và chạy tất cả mọi thứ ngay lập tức trong thời gian thực. Khi bạn chạy coroutines trên dispatcher này, delay sẽ trả về ngay lập tức và tiến triển thời gian ảo.
Các bài kiểm thử sử dụng cơ chế này chạy nhanh, nhưng bạn vẫn có thể kiểm tra xem điều gì xảy ra tại các khoảnh khắc khác nhau trong thời gian ảo. Thời gian chạy tổng cộng giảm đáng kể:

Để sử dụng thời gian ảo, thay thế cuộc gọi runBlocking bằng runTest. runTest nhận một lambda mở rộng đối với TestScope làm đối số. Khi bạn gọi delay trong một hàm suspend bên trong phạm vi đặc biệt này, delay sẽ tăng thời gian ảo thay vì tạm ngừng thời gian thực:
@Test
fun testDelayInSuspend() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
foo()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 6 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun foo() {
delay(1000) // auto-advances without delay
println("foo") // executes eagerly when foo() is called
}
Bạn có thể kiểm tra thời gian ảo hiện tại bằng thuộc tính currentTime của TestScope.
Thời gian chạy thực tế trong ví dụ này chỉ là vài mili giây, trong khi thời gian ảo bằng đối số trì hoãn, là 1000 mili giây.
Để có hiệu ứng đầy đủ của “trì hoãn” ảo trong các coroutine con, bắt đầu tất cả các coroutine con với TestDispatcher. Nếu không, nó sẽ không hoạt động. Dispatcher này được tự động kế thừa từ TestScope khác, trừ khi bạn cung cấp một dispatcher khác:
@Test
fun testDelayInLaunch() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
bar()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 11 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun bar() = coroutineScope {
launch {
delay(1000) // auto-advances without delay
println("bar") // executes eagerly when bar() is called
}
}
Nếu launch được gọi với ngữ cảnh của Dispatchers.Default trong ví dụ trên, bài kiểm thử sẽ thất bại. Bạn sẽ nhận được một ngoại lệ nói rằng công việc vẫn chưa hoàn thành.
Bạn chỉ có thể kiểm thử hàm loadContributorsConcurrent() theo cách này nếu nó bắt đầu các coroutine con với ngữ cảnh được kế thừa, mà không sửa đổi nó bằng dispatcher Dispatchers.Default.
Bạn có thể chỉ định các yếu tố ngữ cảnh như dispatcher khi gọi một hàm thay vì khi định nghĩa nó, điều này cho phép tính linh hoạt và kiểm thử dễ dàng hơn.
API kiểm thử hỗ trợ thời gian ảo là Experimental và có thể thay đổi trong tương lai.
Theo mặc định, trình biên dịch sẽ hiển thị cảnh báo nếu bạn sử dụng API kiểm thử thử nghiệm. Để tắt các cảnh báo này, hãy đánh dấu hàm kiểm thử hoặc toàn bộ lớp chứa các kiểm thử bằng @OptIn(ExperimentalCoroutinesApi::class). Thêm đối số trình biên dịch để thông báo rằng bạn đang sử dụng API thử nghiệm:
compileTestKotlin {
kotlinOptions {
freeCompilerArgs += "-Xuse-experimental=kotlin.Experimental"
}
}
Trong dự án tương ứng với bài hướng dẫn này, đối số trình biên dịch đã được thêm vào tập lệnh Gradle.
Bài tập 8
Tái cấu trúc các bài kiểm thử sau trong tests/tasks/ để sử dụng thời gian ảo thay vì thời gian thực:
* Request4SuspendKtTest.kt
* Request5ConcurrentKtTest.kt
* Request6ProgressKtTest.kt
* Request7ChannelsKtTest.kt
So sánh tổng thời gian chạy trước và sau khi áp dụng sự tái cấu trúc của bạn.
Gợi ý cho bài tập 8
- Thay thế cuộc gọi
runBlockingbằngrunTest, và thay thếSystem.currentTimeMillis()bằngcurrentTime:
@Test
fun test() = runTest {
val startTime = currentTime
// action
val totalTime = currentTime - startTime
// testing result
}2. Bỏ chú thích các khẳng định kiểm tra thời gian ảo chính xác.3. Đừng quên thêm @UseExperimental(ExperimentalCoroutinesApi::class).
Giải pháp cho bài tập 8
Dưới đây là giải pháp cho các trường hợp với coroutines đồng thời và channels:
fun testConcurrent() = runTest {
val startTime = currentTime
val result = loadContributorsConcurrent(MockGithubService, testRequestData)
Assert.assertEquals("Wrong result for 'loadContributorsConcurrent'", expectedConcurrentResults.users, result)
val totalTime = currentTime - startTime
Assert.assertEquals(
"The calls run concurrently, so the total virtual time should be 2200 ms: " +
"1000 for repos request plus max(1000, 1200, 800) = 1200 for concurrent contributors requests)",
expectedConcurrentResults.timeFromStart, totalTime
)
}
Trước tiên, kiểm tra xem kết quả có sẵn chính xác vào thời gian ảo dự kiến, sau đó kiểm tra kết quả chính nó:
fun testChannels() = runTest {
val startTime = currentTime
var index = 0
loadContributorsChannels(MockGithubService, testRequestData) { users, _ ->
val expected = concurrentProgressResults[index++]
val time = currentTime - startTime
Assert.assertEquals(
"Expected intermediate results after ${expected.timeFromStart} ms:",
expected.timeFromStart, time
)
Assert.assertEquals("Wrong intermediate results after $time:", expected.users, users)
}
}
Kết quả trung gian đầu tiên cho phiên bản cuối cùng với channels trở nên có sẵn sớm hơn so với phiên bản progress, và bạn có thể thấy sự khác biệt trong các bài kiểm thử sử dụng thời gian ảo.
Các bài kiểm thử cho các nhiệm vụ “suspend” và “progress” còn lại rất tương tự – bạn có thể tìm thấy chúng trong nhánh solutions của dự án.
Cafedev hy vọng rằng bài hướng dẫn “Kotlin với Coroutines và channels” đã mang đến cho bạn những thông tin hữu ích và giá trị. Chúng tôi luôn tận hưởng việc chia sẻ kiến thức và khám phá cùng cộng đồng. Nếu bạn có bất kỳ thắc mắc hoặc ý kiến đóng góp, hãy đừng ngần ngại chia sẻ trên Cafedev. Chúng tôi mong đợi nhận được phản hồi tích cực từ bạn và sẽ tiếp tục mang đến nhiều nội dung hữu ích khác trên nền tảng này. Cảm ơn bạn đã đồng hành cùng Cafedev!“
Các nguồn kiến thức MIỄN PHÍ VÔ GIÁ từ cafedev tại đây
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của Cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}