
Nội dung chính
1. Tại sao chúng ta cần một Đường ống(Pipeline) Dữ liệu?
Hãy xem xét một ví dụ về cafedevn tập trung vào nội dung kỹ thuật. Sau đây là các mục tiêu chính:
- Cải thiện nội dung: Hiển thị nội dung mà khách hàng muốn xem trong tương lai. Bằng cách này, nội dung có thể được nâng cao.
- Quản lý ứng dụng hiệu quả: Để theo dõi tất cả các hoạt động trong ứng dụng và lưu trữ dữ liệu trong cơ sở dữ liệu hiện có hơn là lưu trữ dữ liệu trong cơ sở dữ liệu mới.
- Nhanh hơn: Để cải thiện doanh nghiệp nhanh hơn nhưng với giá rẻ hơn.
Để đạt được các mục tiêu trên có thể là một nhiệm vụ khó khăn vì một lượng lớn dữ liệu được lưu trữ ở các định dạng khác nhau, do đó việc phân tích, lưu trữ và xử lý dữ liệu trở nên rất phức tạp. Các công cụ khác nhau được sử dụng để lưu trữ các định dạng dữ liệu khác nhau. Giải pháp khả thi cho tình huống như vậy là sử dụng Data Pipeline. Data Pipeline tích hợp dữ liệu được trải rộng trên các nguồn dữ liệu khác nhau và nó cũng xử lý dữ liệu trên cùng một vị trí.
2. Đường ống dữ liệu(Data Pipeline) là gì?
Đường ống dữ liệu AWS là một dịch vụ web có thể truy cập dữ liệu từ các dịch vụ và phân tích khác nhau, xử lý dữ liệu tại cùng một vị trí, sau đó lưu trữ dữ liệu vào các dịch vụ AWS khác nhau như DynamoDB, Amazon S3, v.v.
Ví dụ: sử dụng đường dẫn dữ liệu, bạn có thể lưu trữ nhật ký máy chủ web của mình vào nhóm Amazon S3 hàng ngày và sau đó chạy cụm EMR trên các nhật ký này để tạo báo cáo hàng tuần.
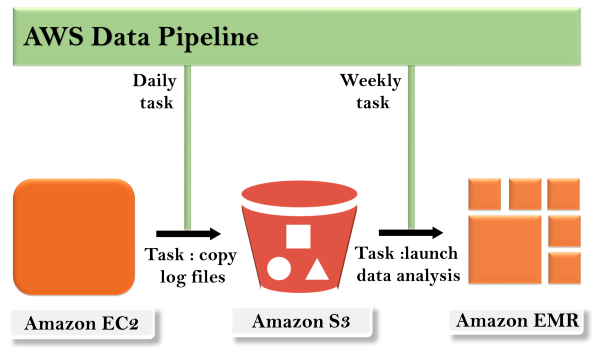
2.1 Khái niệm về đường ống dữ liệu(Data Pipeline) trong AWS
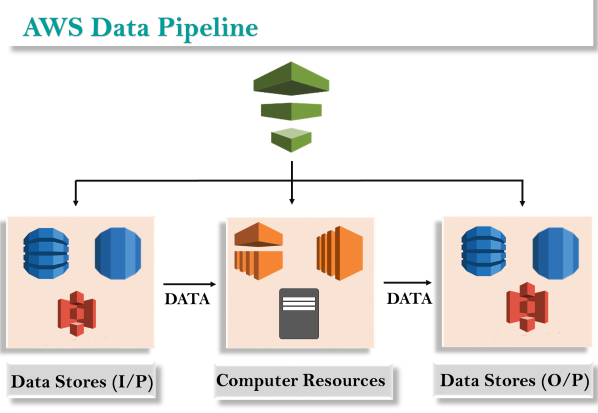
Khái niệm về Đường ống dữ liệu AWS rất đơn giản. Chúng ta có một Đường ống Dữ liệu ở trên cùng. Chúng ta có các cửa hàng đầu vào có thể là Amazon S3, Dynamo DB hoặc Redshift. Dữ liệu từ các kho lưu trữ đầu vào này được gửi đến Đường ống Dữ liệu. Data Pipeline phân tích, xử lý dữ liệu và sau đó kết quả được gửi đến các cửa hàng đầu ra. Các cửa hàng đầu ra này có thể là Amazon Redshift, Amazon S3 hoặc Redshift.
2.2 Ưu điểm của Đường ống dữ liệu AWS
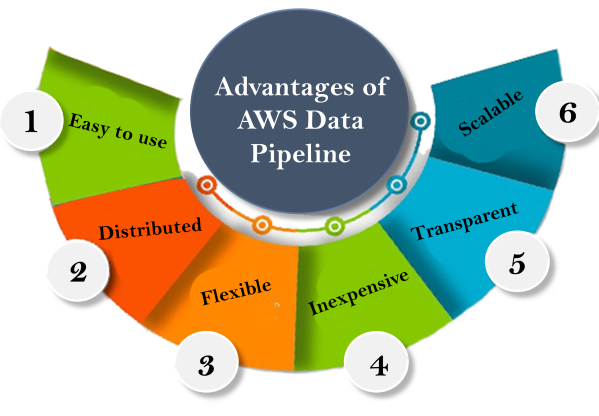
- Dễ sử dụng(Easy to use)
Đường ống dữ liệu AWS rất đơn giản để tạo vì AWS cung cấp bảng điều khiển kéo và thả, tức là bạn không phải viết logic nghiệp vụ để tạo đường ống dữ liệu. - Phân tán(Distributed)
Nó được xây dựng trên cơ sở hạ tầng Phân tán và đáng tin cậy. Nếu bất kỳ lỗi nào xảy ra trong hoạt động khi tạo Đường ống dữ liệu, thì dịch vụ Đường ống dữ liệu AWS sẽ thử lại hoạt động. - Linh hoạt(Flexible)
Đường ống dữ liệu linh hoạt cũng hỗ trợ nhiều tính năng khác nhau như lập lịch, theo dõi phụ thuộc và xử lý lỗi. Data Pipeline có thể thực hiện các hành động khác nhau như chạy các công việc Amazon EMR, thực thi Truy vấn SQL dựa trên cơ sở dữ liệu hoặc thực thi các ứng dụng tùy chỉnh đang chạy trên các phiên bản EC2. - Không tốn kém(Inexpensive)
AWS dữ liệu đường ống là rất tốn kém để sử dụng, và nó được xây dựng với tốc độ hàng tháng thấp. - Scalabl
Bằng cách sử dụng Data Pipeline, bạn có thể gửi công việc đến một hoặc nhiều máy nối tiếp cũng như song song. - Rỏ ràng (Transparent)
Đường ống dữ liệu AWS minh bạch cung cấp toàn quyền kiểm soát các tài nguyên tính toán như phiên bản EC2 hoặc báo cáo EMR.
3. Các thành phần của Đường ống dữ liệu AWS
Sau đây là các thành phần chính của Đường ống dữ liệu AWS:
- Định nghĩa đường ống
Nó chỉ định cách logic nghiệp vụ sẽ giao tiếp với Đường ống dữ liệu. Nó chứa các thông tin khác nhau:- Các nút dữ liệu(Data Nodes)
Nó chỉ định tên, vị trí và định dạng của các nguồn dữ liệu như Amazon S3, Dynamo DB, v.v. - Hoạt động Hoạt(Activities)
động là các hành động thực hiện các Truy vấn SQL trên cơ sở dữ liệu, chuyển đổi dữ liệu từ nguồn dữ liệu này sang nguồn dữ liệu khác. - Lịch trình(Schedules)
Lập kế hoạch được thực hiện trên các Hoạt động. - Điều kiện tiên quyết(Preconditions)
Điều kiện tiên quyết phải được thỏa mãn trước khi lên lịch cho các hoạt động. Ví dụ: bạn muốn di chuyển dữ liệu từ Amazon S3, thì điều kiện tiên quyết là kiểm tra xem dữ liệu có sẵn trong Amazon S3 hay không. Nếu điều kiện tiên quyết được thỏa mãn, thì hoạt động sẽ được thực hiện. - Tài nguyên(Resources)
Bạn có tài nguyên tính toán như Amazon EC2 hoặc cụm EMR. - Hành động
Nó cập nhật trạng thái về đường ống của bạn, chẳng hạn như bằng cách gửi email cho bạn hoặc kích hoạt báo động.
- Các nút dữ liệu(Data Nodes)
- Đường ống(Pipeline)
Nó bao gồm ba mục quan trọng:- Các thành phần đường ống(Pipeline components)
Chúng ta đã thảo luận về các thành phần đường ống. Về cơ bản, đó là cách bạn giao tiếp Đường ống dữ liệu của mình với các dịch vụ AWS. - Phiên bản(Instances)
Khi tất cả các thành phần của đường ống được biên dịch trong một đường ống, thì nó sẽ tạo ra một thể hiện có thể hành động được chứa thông tin của một nhiệm vụ cụ thể. - Nỗ lực(Attempts)
Chúng tôi biết rằng Data Pipeline cho phép bạn thử lại các thao tác không thành công. Đây không là gì ngoài những nỗ lực.
- Các thành phần đường ống(Pipeline components)
- Task Runner(Task Runner)
Task Runner là một ứng dụng thăm dò các nhiệm vụ từ Data Pipeline và thực hiện các nhiệm vụ.
4. Kiến trúc của Task Runner
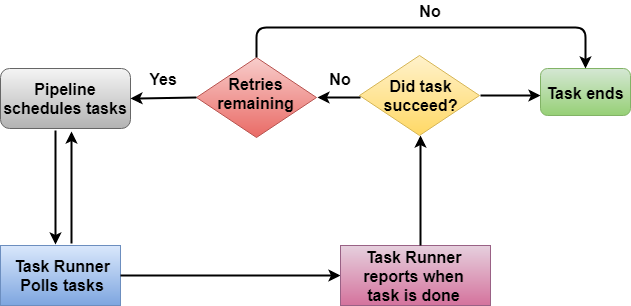
Trong kiến trúc trên, Task Runner thăm dò các nhiệm vụ từ Data Pipeline. Task Runner báo cáo tiến trình của nó ngay sau khi nhiệm vụ được hoàn thành. Sau khi báo cáo, điều kiện được kiểm tra xem nhiệm vụ đã thành công hay chưa. Nếu một tác vụ được thực hiện thành công, thì tác vụ đó sẽ kết thúc và nếu không, các lần thử lại được kiểm tra. Nếu các lần thử lại vẫn còn, thì toàn bộ quá trình lại tiếp tục; nếu không, nhiệm vụ bị kết thúc đột ngột.
5. Tạo đường ống dữ liệu
- Đăng nhập vào Bảng điều khiển quản lý AWS.
- Đầu tiên, chúng ta sẽ tạo bảng Dynamo DB và hai nhóm S3.
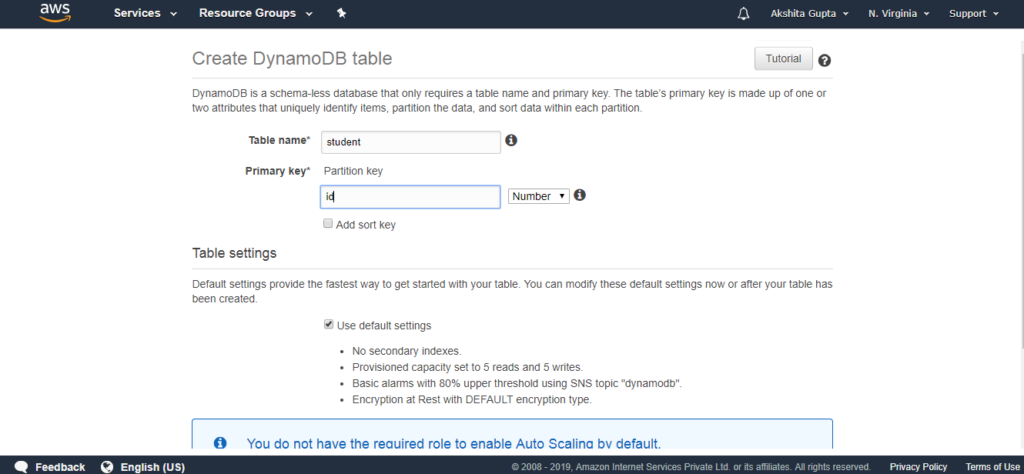
- Bây giờ, chúng ta sẽ tạo bảng Dynamo DB. Bấm vào bảng tạo(create table).
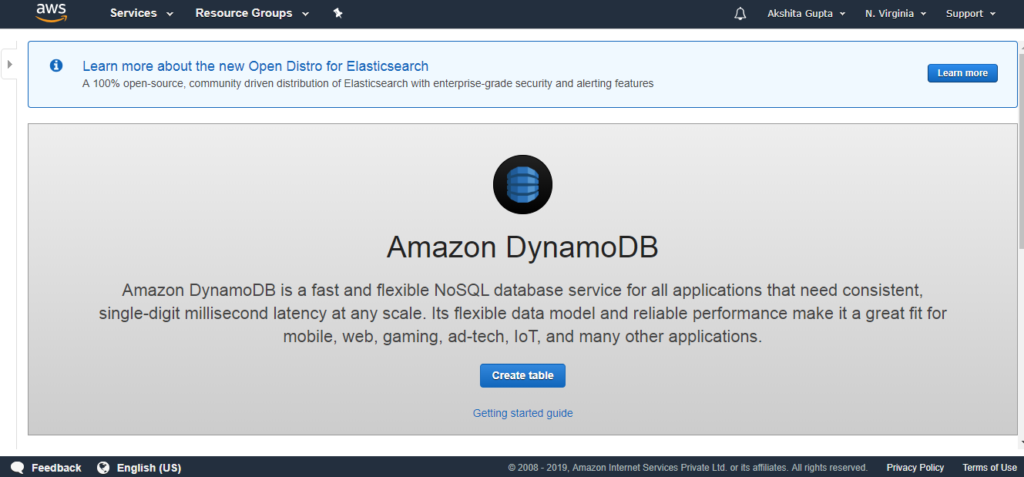
- Điền các chi tiết sau như tên bảng, Khóa chính để tạo bảng mới.
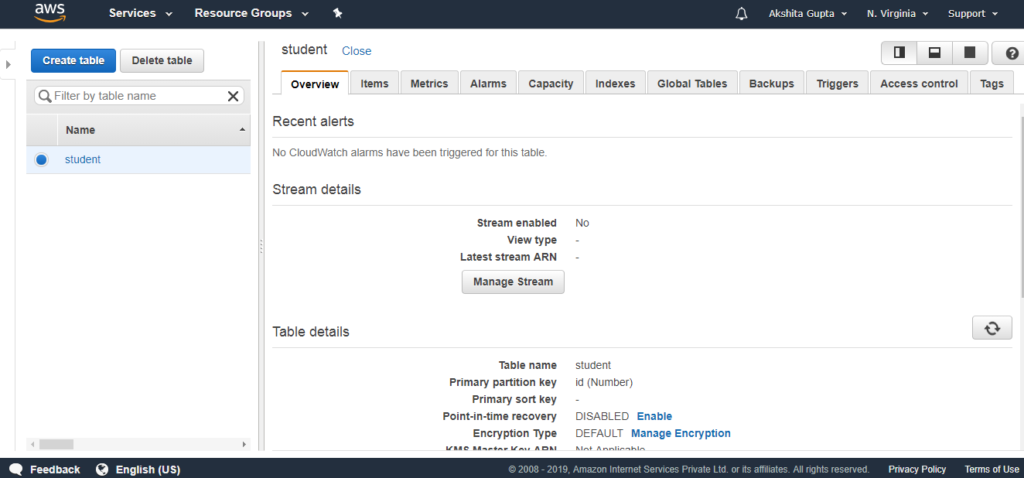
- Màn hình bên dưới cho thấy bảng “student“ đã được tạo.
- Nhấp vào các items và sau đó nhấp vào tạo một mục(create an item).
- Chúng tôi thêm ba mục, tức là, id, Tên và Giới tính.
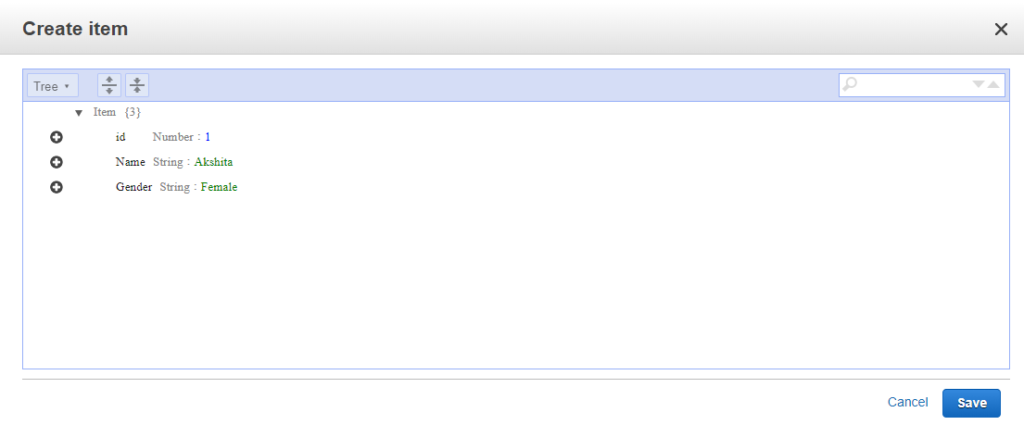
- Màn hình dưới đây cho thấy dữ liệu được chèn vào bảng DynamoDB.
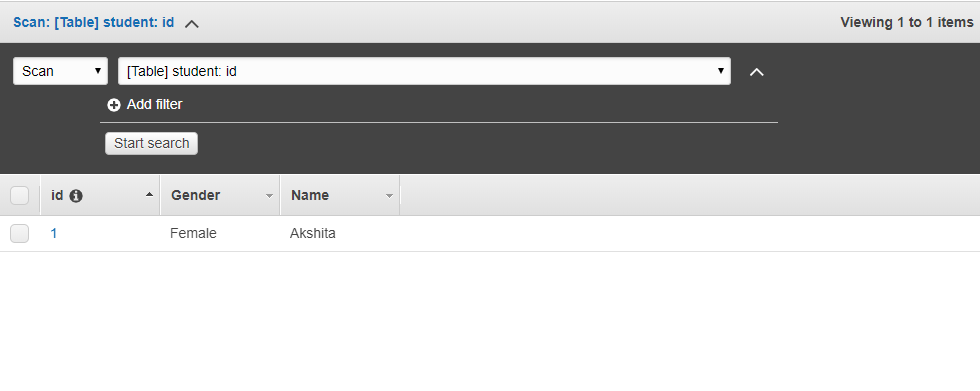
- Bây giờ chúng ta tạo hai nhóm S3. Đầu tiên sẽ lưu trữ dữ liệu mà chúng tôi đang xuất từ DynamoDB và thứ hai sẽ lưu trữ các bản ghi.
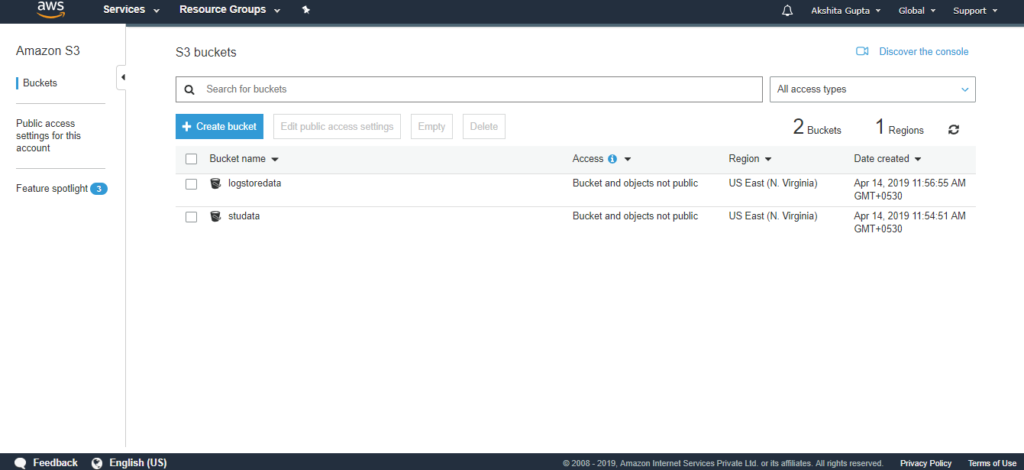
Chúng ta đã tạo hai nhóm, tức là logstoredata và studata. Nhóm logstoredata lưu trữ các bản ghi trong khi nhóm studata lưu trữ dữ liệu mà chúng ta đang xuất từ DynamoDB.
- Bây giờ chúng ta tạo Đường ống Dữ liệu. Di chuyển đến dịch vụ dữ liệu đường ống và sau đó nhấn vào Bắt đầu sử dụng(Get started) nút

- Điền vào các chi tiết sau để tạo một đường ống, sau đó nhấp vào Chỉnh sửa trên Kiến trúc sư nếu bạn muốn thay đổi bất kỳ thành phần nào trong một đường ống.
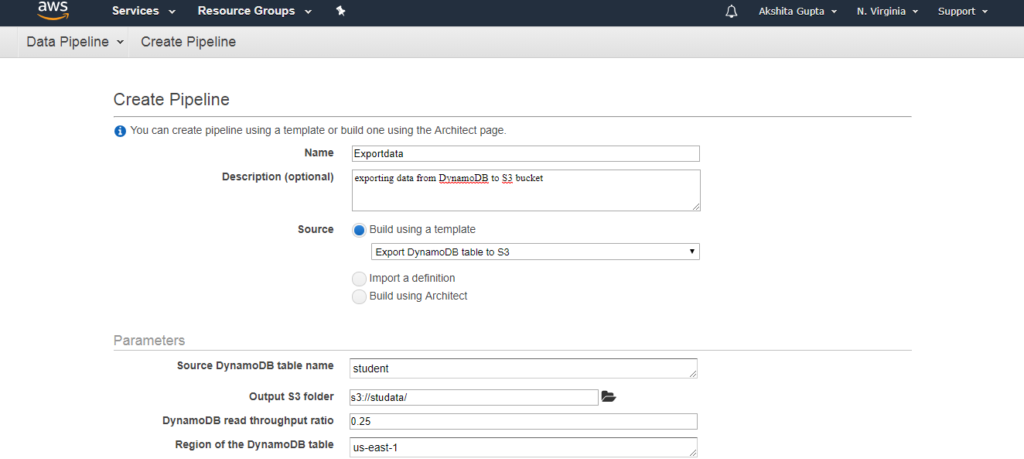
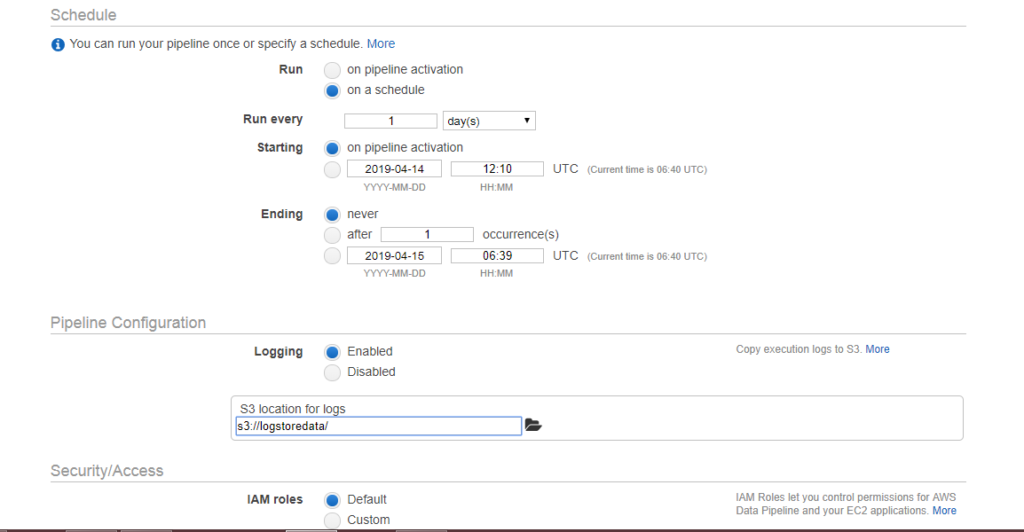
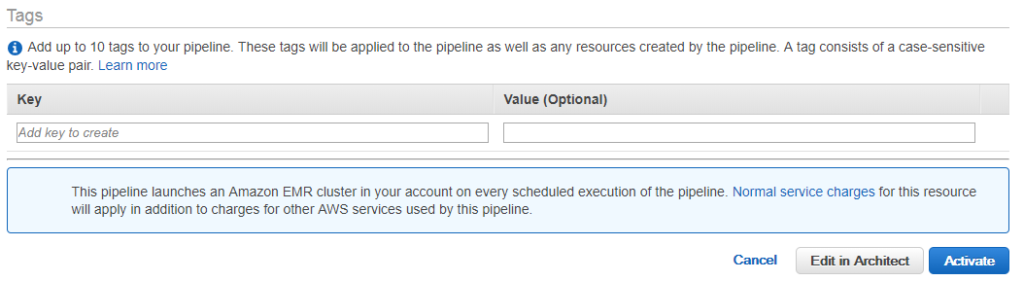
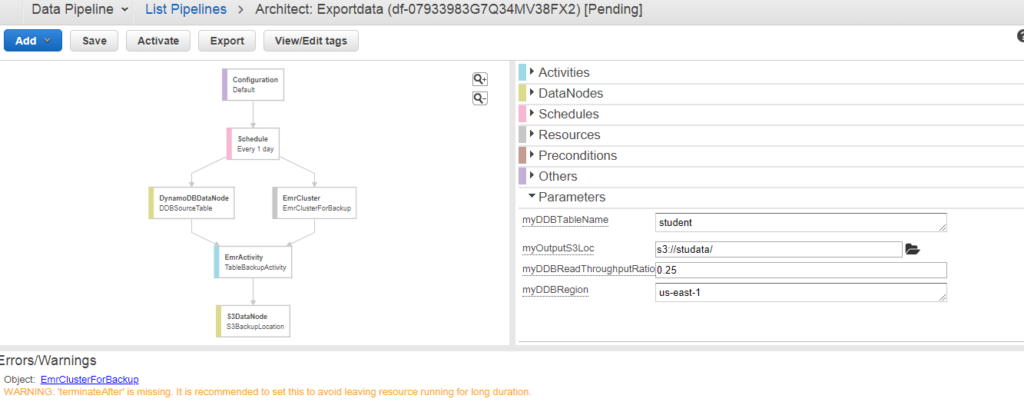
- Màn hình bên dưới xuất hiện khi nhấp vào Chỉnh sửa trong Kiến trúc(Edit in Architect). Chúng ta có thể thấy rằng cảnh báo xảy ra, tức là, TerminaAfter bị thiếu. Để loại bỏ cảnh báo này, bạn cần thêm trường mới của TerminaAfter trong Tài nguyên. Sau khi thêm trường, hãy nhấp vào nút Kích hoạt.
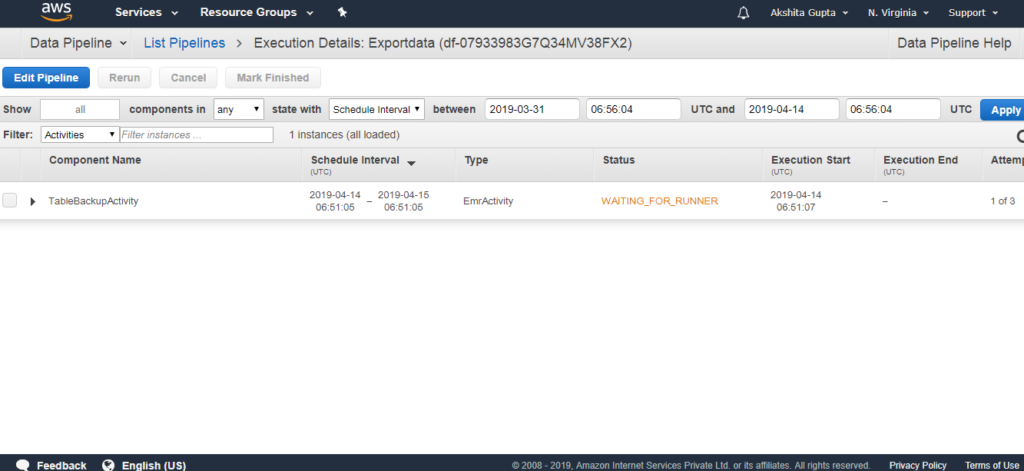
- Ban đầu, trạng thái WAITING_FOR_DEPENDENCIES xuất hiện. Khi làm mới, trạng thái là WAITING_FOR_RUNNER. Ngay sau khi trạng thái Đang chạy xuất hiện, bạn có thể kiểm tra thùng S3 của mình, dữ liệu sẽ được lưu trữ ở đó.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Tài liệu từ cafedev:
- Full series tự học Amazon Web Services(AWS)từ cơ bản tới nâng cao tại đây nha.
- Ebook về AWS tại đây.
- Các nguồn kiến thức MIỄN PHÍ VÔ GIÁ từ cafedev tại đây
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}