
Cafedev chia sẻ bài này nhằm giúp ace tìm hiểu tất cả các vấn đề về Machine Learning(ML) và các thuật ngữ được sử dụng trong lĩnh vực ML(Machine Learning).
Nội dung chính
1. Các vấn đề về ML chúng ta cần phải biết
Có nhiều cách khác nhau để phân loại các vấn đề về ML.. Ở đây, chúng ta sẽ thảo luận về những cái dễ hiểu nhất. Và sau đó chúng ta sẽ đi chi tiết về chúng qua series Tự học Machine Learning của Cafedev.
1.1 Dựa trên bản chất của “tín hiệu”(signal) hoặc “phản hồi”(feedback) có sẵn cho hệ thống học
- Học tập có giám sát(Supervised learning): Máy tính được chỉ định với các đầu vào là các mẫu(dữ liệu và một cái tên tương ứng nào đó) và đầu ra mong muốn của chúng, do “giáo viên”(teacher) đưa ra và mục tiêu là học một quy tắc chung ánh xạ từ đầu vào với đầu ra. Quá trình đào tạo tiếp tục cho đến khi mô hình đạt được mức độ chính xác mong muốn trên dữ liệu đào tạo. Một số ví dụ thực tế là:
- Phân loại hình ảnh: Bạn đào tạo máy tính học các hình ảnh / tên. Sau đó, trong tương lai, bạn đưa ra một hình ảnh mới với hy vọng rằng máy tính sẽ nhận ra đối tượng mới đó.
- Dự đoán thị trường / Hồi quy: Bạn huấn luyện máy tính với dữ liệu lịch sử của thị trường và yêu cầu máy tính dự đoán mức giá mới trong tương lai.
- Học không giám sát:(Unsupervised learning) Không có tên nào được cấp cho thuật toán để nó học cả(Dữ liệu đầu vào sẽ không có tên nào cả), để nó tự tìm cấu trúc trong đầu vào của nó. Nó được sử dụng để phân cụm những cái chung trong các nhóm khác nhau. Bản thân việc học không giám sát có thể là một mục tiêu (khám phá các mẫu ẩn trong dữ liệu).
- Phân cụm: Bạn yêu cầu máy tính tách các dữ liệu tương tự nhau thành từng cụm, điều này rất cần thiết trong nghiên cứu và khoa học.
- Hình ảnh hóa kích thước lớn: Sử dụng máy tính để giúp chúng ta trực quan hóa dữ liệu với kích thước lớn.
- Tạo Models: Sau khi một mô hình(Models) nắm bắt được xác suất phân phối của dữ liệu đầu vào của bạn, nó sẽ có thể tạo ra nhiều dữ liệu hơn. Điều này có thể rất hữu ích để làm cho quá trình phân loại của bạn mạnh mẽ hơn.
- Học tập bán giám sát: Các vấn đề trong đó bạn có một lượng lớn dữ liệu đầu vào và chỉ một số dữ liệu được gắn tên, được gọi là các vấn đề học tập bán giám sát. Những vấn đề này nằm giữa cả việc học có giám sát và không giám sát. Ví dụ: kho lưu trữ ảnh chỉ một số hình ảnh được gắn tên, (ví dụ: chó, mèo, người) và phần lớn không được gắn tên.
- Học tập một cách cố định: Một chương trình máy tính tương tác với một môi trường năng động, trong đó nó phải thực hiện một mục tiêu nhất định (chẳng hạn như lái xe hoặc chơi trò chơi với đối thủ). Chương trình được cung cấp phản hồi về phần thưởng và hình phạt khi nó điều hướng các vấn đề của nó.
1.2. Dựa trên cơ sở “đầu ra” mong muốn từ một hệ thống ML
- Phân loại(Classification): Đầu vào được chia thành hai hoặc nhiều lớp và người học phải tạo ra một mô hình gán các đầu vào không nhìn thấy cho một hoặc nhiều (phân loại nhiều tên) của các lớp này. Điều này thường được giải quyết theo cách có giám sát. Lọc thư rác là một ví dụ về phân loại, trong đó đầu vào là thư email (hoặc khác) và các lớp là “thư rác” và “không phải thư rác”.
- Hồi quy(Regression): Cũng là một bài toán học có giám sát, nhưng kết quả đầu ra là liên tục chứ không rời rạc. Ví dụ: dự đoán lịch sử giá cổ phiếu bằng dữ liệu.

- Phân cụm(Clustering): Ở đây, một tập hợp các đầu vào sẽ được chia thành các nhóm. Không giống như trong phân loại, các nhóm không được biết trước, khiến đây thường là một nhiệm vụ không được giám sát.
Như bạn có thể thấy trong ví dụ bên dưới, các điểm tập dữ liệu đã cho đã được chia thành các nhóm có thể nhận dạng được bằng các màu đỏ, xanh lục và xanh lam.
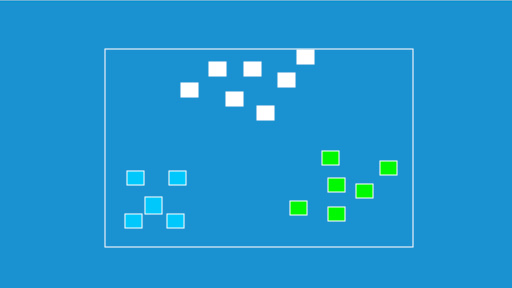
- Ước lượng mật độ: Nhiệm vụ là tìm sự phân bố của các yếu tố đầu vào trong một số không gian.
- Giảm kích thước: Nó đơn giản hóa đầu vào bằng cách ánh xạ chúng vào một không gian có chiều thấp hơn. Mô hình hóa chủ đề là một vấn đề liên quan, trong đó một chương trình được cung cấp một danh sách các tài liệu tiếng người và có nhiệm vụ tìm ra tài liệu nào bao gồm các chủ đề tương tự.
Trên cơ sở các nhiệm vụ / vấn đề( tasks/problems) của ML, chúng tôi có một số thuật toán được sử dụng để thực hiện các nhiệm vụ này. Một số thuật toán ML thường được sử dụng là Hồi quy tuyến tính, Hồi quy logistic, Cây quyết định, SVM (Máy vectơ hỗ trợ), Naive Bayes, KNN (K láng giềng gần nhất), K-Means, Random Forest, v.v.
Lưu ý: Tất cả các thuật toán này sẽ được đề cập trong các bài viết sắp tới.
2. Các thuật ngữ của Học máy
- Mô hình(Model)
Mô hình là một biểu diễn cụ thể được học từ dữ liệu bằng cách áp dụng một số thuật toán ML. Một mô hình còn được gọi là giả thuyết.
- Đặc điểm, đặc tính(Feature)
Đặc điểm là một thuộc tính có thể đo lường riêng dữ liệu của chúng ta. Một tập hợp các đối tượng địa lý có thể được mô tả một cách thuận tiện bằng một thuộc tính vectơ. Các thuộc tính vectơ được đưa vào làm đầu vào cho mô hình. Ví dụ, để dự đoán một loại trái cây, có thể có các thuộc tính như màu sắc, mùi, vị, v.v.
Lưu ý: Chọn các thuộc tính thông tin, phân biệt và độc lập là một bước quan trọng để các thuật toán hiệu quả. Chúng ta thường sử dụng một trình trích xuất thuộc tính để trích xuất các thuộc tính liên quan từ dữ liệu thô.
- Mục tiêu (Nhãn)(Target – Label)
Biến hoặc nhãn mục tiêu là giá trị được mô hình của chúng ta dự đoán. Đối với ví dụ về trái cây được thảo luận trong phần đặc tính, nhãn(label) với mỗi bộ đầu vào sẽ là tên của trái cây như táo, cam, chuối, v.v.
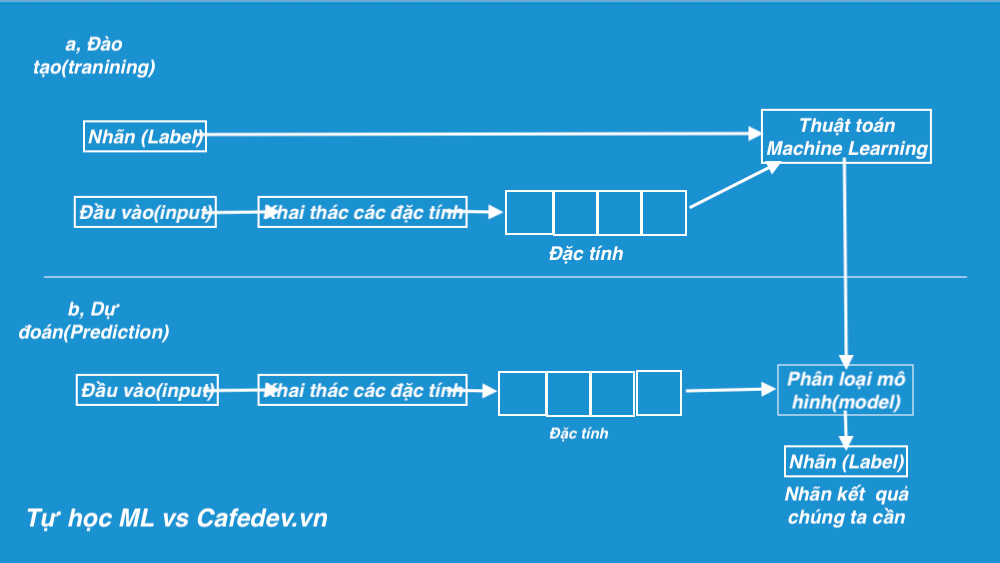
- Đào tạo(Training)
Ý tưởng là cung cấp một tập hợp đầu vào (đặc tính) và đầu ra dự kiến (nhãn), vì vậy sau khi đào tạo, chúng ta sẽ có một mô hình (giả thuyết) sau đó sẽ ánh xạ dữ liệu mới đến một trong các danh mục được đào tạo.
- Sự dự đoán(Prediction)
Khi mô hình của chúng ta đã sẵn sàng, nó có thể được cung cấp một tập hợp các đầu vào mà nó sẽ cung cấp đầu ra dự đoán (nhãn).
Hình bên dưới rõ ràng các khái niệm trên:
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


 và các thuật ngữ được sử dụng trong lĩnh vực ML(Machine Learning).){kind=link}