
Điều kiện tiên quyết: Học tập củng cố(học tăng cường)
Học tập củng cố ngắn gọn là một mô hình của Quy trình học tập, trong đó tác nhân học tập học, ngoài giờ, để cư xử tối ưu trong một môi trường nhất định bằng cách tương tác liên tục trong môi trường đó. Tác nhân trong quá trình học tập trải qua nhiều tình huống khác nhau trong môi trường mà nó đang ở. Chúng được gọi là trạng thái. Người đại diện khi đang ở trong trạng thái đó có thể chọn từ một loạt các hành động được phép có thể nhận được các phần thưởng (hoặc hình phạt) khác nhau. Nhân viên học tập ngoài giờ học cách tối đa hóa những phần thưởng này để cư xử tối ưu ở bất kỳ trạng thái nhất định nào.
Q-Learning là một hình thức cơ bản của Học tăng cường sử dụng giá trị Q (còn gọi là giá trị hành động) để cải thiện lặp đi lặp lại hành vi của tác nhân học tập.
- Giá trị Q hoặc Giá trị hành động: Giá trị Q được xác định cho các trạng thái và hành động. Q(S,A) là một ước tính về mức độ tốt khi thực hiện hành động A tại trạng thái S. Ước tính Q(S,A) này sẽ được tính toán lặp lại bằng cách sử dụng quy tắc TD- Update mà chúng ta sẽ thấy trong các phần sắp tới.
- Phần thưởng và Tập: Tác nhân trong suốt thời gian tồn tại của nó bắt đầu từ trạng thái bắt đầu, thực hiện một số chuyển đổi từ trạng thái hiện tại sang trạng thái tiếp theo dựa trên lựa chọn hành động và cũng là môi trường mà tác nhân đang tương tác. Ở mỗi bước của quá trình chuyển đổi, tác nhân từ một trạng thái thực hiện một hành động, quan sát phần thưởng từ môi trường, và sau đó chuyển sang trạng thái khác. Nếu tại bất kỳ thời điểm nào đại lý kết thúc ở một trong các trạng thái kết thúc điều đó có nghĩa là không có khả năng chuyển tiếp nữa. Đây được cho là sự hoàn thành của một tập phim.
- Sự khác biệt tạm thời hoặc TD-Cập nhật:
Quy tắc Chênh lệch Thời gian hoặc Quy tắc TD-Cập nhật có thể được biểu diễn như sau:
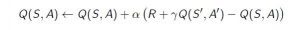
Quy tắc cập nhật này để ước tính giá trị của Q được áp dụng tại mỗi bước của tác nhân tương tác với môi trường. Các thuật ngữ được sử dụng được giải thích bên dưới :
- S : Trạng thái hiện tại của đại lý.
- A : Hành động hiện tại Được chọn theo một số chính sách.
- S’: Trạng thái tiếp theo nơi đại lý kết thúc.
- A’: Hành động tốt nhất tiếp theo sẽ được chọn bằng cách sử dụng ước tính giá trị Q hiện tại, tức là chọn hành động có giá trị Q tối đa ở trạng thái tiếp theo.
- R : Phần thưởng hiện tại được quan sát từ môi trường trong Phản hồi của hành động hiện tại.
- y(> 0 và <= 1): Hệ số chiết khấu cho phần thưởng trong tương lai. Phần thưởng trong tương lai ít giá trị hơn phần thưởng hiện tại nên chúng phải được chiết khấu. Vì giá trị Q là ước tính phần thưởng mong đợi từ một tiểu bang, nên quy tắc chiết khấu cũng được áp dụng ở đây.
- anpla: Độ dài bước được thực hiện để cập nhật ước lượng của Q (S, A).
4. Chọn Hành động cần thực hiện bằng cách sử dụng chính sách-tự do:
chính sách E-greedy là một chính sách rất đơn giản trong việc lựa chọn các hành động bằng cách sử dụng ước tính giá trị Q hiện tại. Nó diễn ra như sau:
- Với xác suất(1-E), hãy chọn hành động có giá trị Q cao nhất.
- Với xác suất(E) chọn bất kỳ hành động nào một cách ngẫu nhiên.
Bây giờ với tất cả lý thuyết cần thiết trong tay, chúng ta hãy lấy một ví dụ. Chúng tôi sẽ sử dụng môi trường phòng tập thể dục của OpenAI để đào tạo mô hình Q-Learning của mình.
Lệnh Cài đặt phòng tập gym
pip install gymTrước khi bắt đầu với ví dụ, bạn sẽ cần một số mã trợ giúp để hình dung hoạt động của các thuật toán. Sẽ có hai tệp trợ giúp cần được tải xuống trong thư mục làm việc. Người ta có thể tìm thấy các tập tin ở đây.
Tải tại đây
Bước # 1: Nhập thư viện bắt buộc.
import gym
import itertools
import matplotlib
import matplotlib.style
import numpy as np
import pandas as pd
import sys
from collections import defaultdict
from windy_gridworld import WindyGridworldEnv
import plotting
matplotlib.style.use('ggplot')Bước # 2: Tạo môi trường phòng tập.
env = WindyGridworldEnv() Bước # 3: Thực hiện chính sách -treedy.
def createEpsilonGreedyPolicy(Q, epsilon, num_actions):
"""
Creates an epsilon-greedy policy based
on a given Q-function and epsilon.
Returns a function that takes the state
as an input and returns the probabilities
for each action in the form of a numpy array
of length of the action space(set of possible actions).
"""
def policyFunction(state):
Action_probabilities = np.ones(num_actions,
dtype = float) * epsilon / num_actions
best_action = np.argmax(Q[state])
Action_probabilities[best_action] += (1.0 - epsilon)
return Action_probabilities
return policyFunction Bước # 4: Xây dựng Mô hình Q-Learning.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
def qLearning(env, num_episodes, discount_factor = 1.0,
alpha = 0.6, epsilon = 0.1):
"""
Q-Learning algorithm: Off-policy TD control.
Finds the optimal greedy policy while improving
following an epsilon-greedy policy"""
# Action value function
# A nested dictionary that maps
# state -> (action -> action-value).
Q = defaultdict(lambda: np.zeros(env.action_space.n))
# Keeps track of useful statistics
stats = plotting.EpisodeStats(
episode_lengths = np.zeros(num_episodes),
episode_rewards = np.zeros(num_episodes))
# Create an epsilon greedy policy function
# appropriately for environment action space
policy = createEpsilonGreedyPolicy(Q, epsilon, env.action_space.n)
# For every episode
for ith_episode in range(num_episodes):
# Reset the environment and pick the first action
state = env.reset()
for t in itertools.count():
# get probabilities of all actions from current state
action_probabilities = policy(state)
# choose action according to
# the probability distribution
action = np.random.choice(np.arange(
len(action_probabilities)),
p = action_probabilities)
# take action and get reward, transit to next state
next_state, reward, done, _ = env.step(action)
# Update statistics
stats.episode_rewards[ith_episode] += reward
stats.episode_lengths[ith_episode] = t
# TD Update
best_next_action = np.argmax(Q[next_state])
td_target = reward + discount_factor * Q[next_state][best_next_action]
td_delta = td_target - Q[state][action]
Q[state][action] += alpha * td_delta
# done is True if episode terminated
if done:
break
state = next_state
return Q, stats Bước # 5: Huấn luyện mô hình.
Q, stats = qLearning(env, 1000) Bước # 6: Lập bảng thống kê quan trọng.
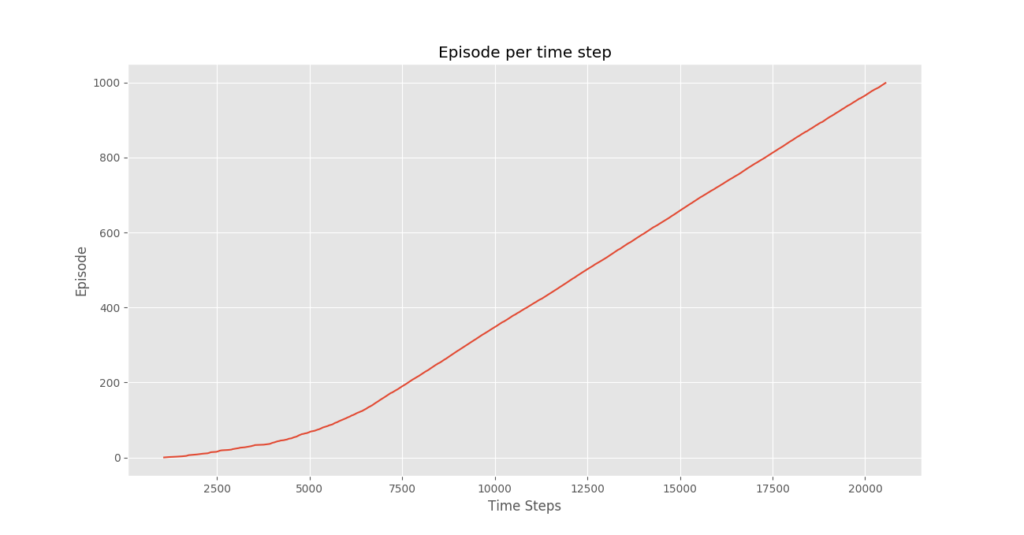
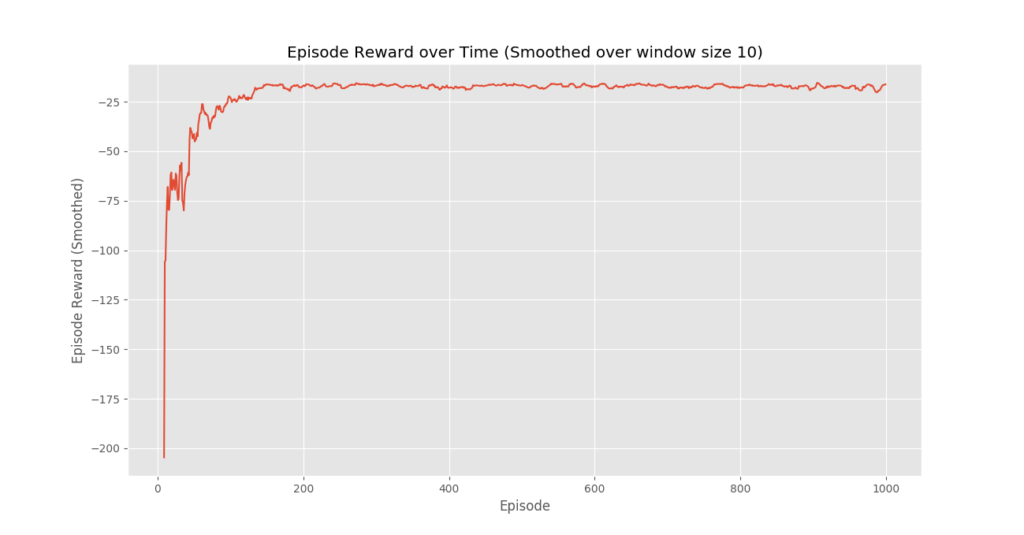
plotting.plot_episode_stats(stats) 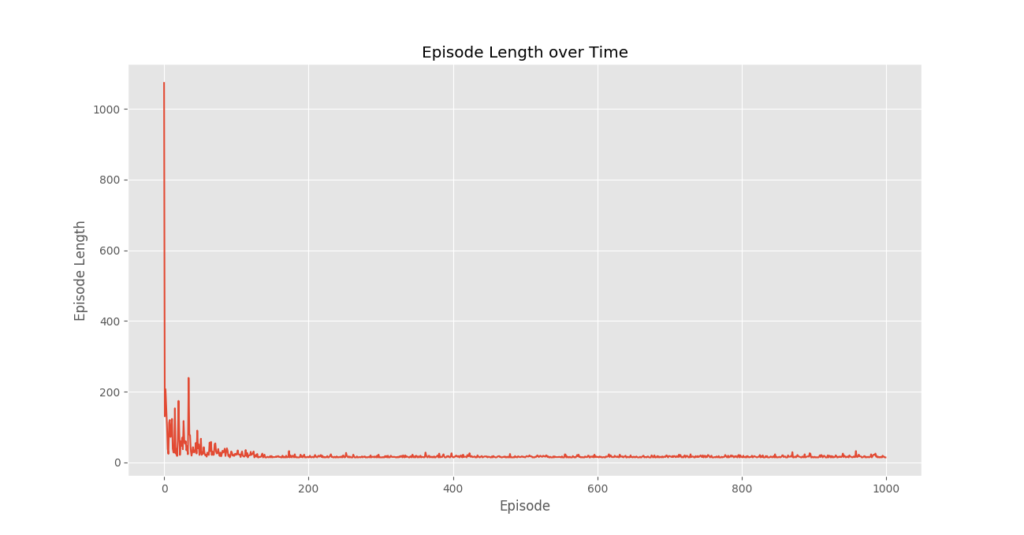
Phần kết luận:
Chúng ta thấy rằng trong cốt truyện Phần thưởng tập theo thời gian rằng phần thưởng của tập tăng dần theo thời gian và cuối cùng đạt mức phần thưởng cao cho mỗi giá trị tập, điều này cho thấy rằng nhân viên đã học cách tối đa hóa tổng phần thưởng kiếm được trong một tập bằng cách cư xử tối ưu ở mọi tiểu bang.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}