
Khái niệm
Xử lý dữ liệu là một nhiệm vụ chuyển đổi dữ liệu từ một biểu mẫu nhất định sang một biểu mẫu mong muốn và hữu dụng hơn nhiều, tức là làm cho nó có ý nghĩa và nhiều thông tin hơn. Sử dụng các thuật toán ML, mô hình toán học và kiến thức thống kê, toàn bộ quy trình này có thể được tự động hóa. Đầu ra của quá trình hoàn chỉnh này có thể ở bất kỳ dạng mong muốn nào như đồ thị, video, biểu đồ, bảng, hình ảnh và nhiều hơn nữa, tùy thuộc vào nhiệm vụ chúng ta đang thực hiện và yêu cầu của máy. Điều này có vẻ đơn giản nhưng đối với các tổ chức thực sự lớn như Twitter, Facebook, các cơ quan hành chính như Paliament, UNESCO và các tổ chức ngành y tế, toàn bộ quá trình này cần phải được thực hiện một cách có cấu trúc. Vì vậy, các bước thực hiện như sau:
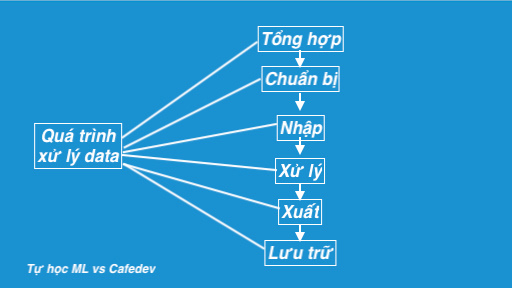
- Bộ sưu tập:
Bước quan trọng nhất khi bắt đầu với ML là có dữ liệu có chất lượng tốt và độ chính xác. Dữ liệu có thể được thu thập từ bất kỳ nguồn đã xác thực nào như kho dữ liệu. kết quả tốt nhất. Theo cách tương tự, dữ liệu chính xác và chất lượng cao sẽ giúp quá trình học tập của mô hình dễ dàng và tốt hơn và tại thời điểm thử nghiệm, mô hình sẽ mang lại kết quả hiện đại.
Một lượng lớn vốn, thời gian và nguồn lực được tiêu tốn trong việc thu thập dữ liệu. Các tổ chức hoặc nhà nghiên cứu phải quyết định loại dữ liệu nào họ cần để thực hiện nhiệm vụ hoặc nghiên cứu của họ.
Ví dụ: Làm việc trên Bộ nhận dạng biểu cảm khuôn mặt, cần một số lượng lớn hình ảnh có nhiều biểu cảm của con người. Dữ liệu tốt đảm bảo rằng kết quả của mô hình là hợp lệ và có thể được tin cậy.
- Sự chuẩn bị :
Dữ liệu được thu thập có thể ở dạng thô không thể được cung cấp trực tiếp vào máy. Vì vậy, đây là một quá trình thu thập các tập dữ liệu từ các nguồn khác nhau, phân tích các tập dữ liệu này và sau đó xây dựng một tập dữ liệu mới để xử lý và khám phá thêm. Việc chuẩn bị này có thể được thực hiện bằng tay hoặc từ phương pháp tự động. Dữ liệu cũng có thể được chuẩn bị dưới dạng số, điều này cũng sẽ giúp mô hình học nhanh hơn.
Ví dụ: Một hình ảnh có thể được chuyển đổi thành một ma trận có N X N kích thước, giá trị của mỗi ô sẽ cho biết pixel hình ảnh.
- Đầu vào :
Bây giờ dữ liệu đã chuẩn bị có thể ở dạng mà máy không thể đọc được, vì vậy để chuyển đổi dữ liệu này sang dạng đọc được, cần một số thuật toán chuyển đổi. Để tác vụ này được thực thi, cần tính toán và độ chính xác cao. Ví dụ: Dữ liệu có thể được thu thập thông qua các nguồn như dữ liệu MNIST Digit (hình ảnh), bình luận trên twitter, tệp âm thanh, video clip.
- Chế biến – Xử lý :
Đây là giai đoạn mà các thuật toán và kỹ thuật ML được yêu cầu để thực hiện các hướng dẫn được cung cấp trên một khối lượng lớn dữ liệu với độ chính xác và tính toán tối ưu.
- Đầu ra:
Trong giai đoạn này, kết quả được máy mua sắm theo cách có ý nghĩa mà người dùng có thể dễ dàng suy ra. Đầu ra có thể ở dạng báo cáo, đồ thị, video, v.v.
- Lưu trữ :
Đây là bước cuối cùng, trong đó đầu ra thu được và dữ liệu mô hình dữ liệu và tất cả các thông tin hữu ích được lưu lại để sử dụng trong tương lai.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}