
Nội dung chính
1. Học cho máy là gì?
Một máy được cho là đang học hỏi từ các Trải nghiệm trong quá khứ (nguồn cấp dữ liệu trong) đối với một số loại Nhiệm vụ, nếu Hiệu suất trong một Nhiệm vụ nhất định được cải thiện với Trải nghiệm. Ví dụ: giả sử rằng một máy phải dự đoán liệu khách hàng có mua một sản phẩm cụ thể có cho biết “Chống vi-rút” trong năm nay hay không. Máy sẽ làm điều đó bằng cách xem xét kiến thức trước đây / kinh nghiệm trong quá khứ, tức là dữ liệu của các sản phẩm mà khách hàng đã mua hàng năm và nếu anh ta mua Antivirus hàng năm, thì khả năng cao là khách hàng sẽ mua một phần mềm diệt virus. năm nay cũng vậy. Đây là cách học máy hoạt động ở cấp độ khái niệm cơ bản.
2. Học tập có giám sát:
Học tập có giám sát là khi mô hình được đào tạo trên một tập dữ liệu được gắn nhãn. Tập dữ liệu được gắn nhãn là tập dữ liệu có cả tham số đầu vào và đầu ra. Trong kiểu học tập này, cả tập dữ liệu đào tạo và xác nhận đều được gắn nhãn như thể hiện trong các hình bên dưới.
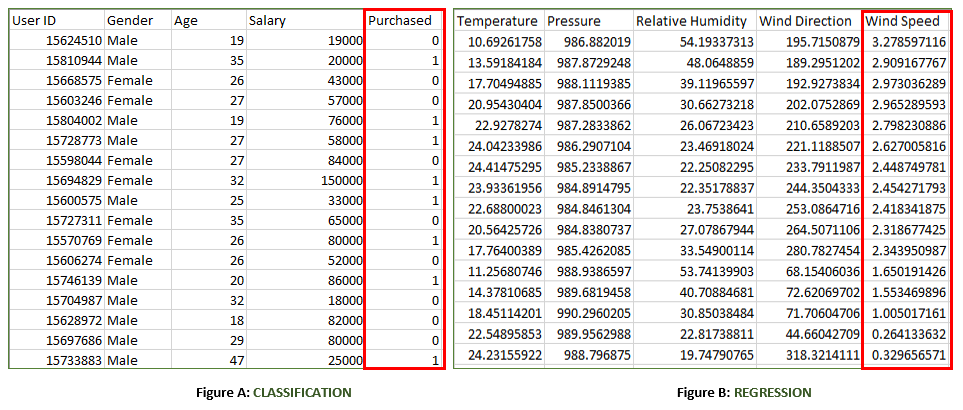
Cả hai số liệu trên đều có tập dữ liệu được gắn nhãn:
- Hình A: Đây là một tập dữ liệu về một cửa hàng mua sắm, hữu ích trong việc dự đoán liệu khách hàng có mua một sản phẩm cụ thể đang được xem xét hay không dựa trên giới tính, độ tuổi và mức lương của họ.
- Đầu vào: Giới tính, Tuổi, Mức lương
- Đầu ra: Đã mua tức là 0 hoặc 1; 1 có nghĩa là có khách hàng sẽ mua và 0 có nghĩa là khách hàng sẽ không mua.
- Hình B: Đây là một tập dữ liệu Khí tượng phục vụ mục đích dự đoán tốc độ gió dựa trên các thông số khác nhau.
- Đầu vào: Điểm sương, Nhiệt độ, Áp suất, Độ ẩm tương đối, Hướng gió
- Đầu ra: Tốc độ gió
3. Đào tạo hệ thống
Trong khi đào tạo mô hình, dữ liệu thường được chia theo tỷ lệ 80:20, tức là 80% là dữ liệu đào tạo và phần còn lại là dữ liệu thử nghiệm. Trong dữ liệu đào tạo, chúng ta cung cấp đầu vào cũng như đầu ra cho 80% dữ liệu. Mô hình chỉ học từ dữ liệu đào tạo. Chúng ta sử dụng các thuật toán ML khác nhau (mà chúng ta sẽ thảo luận chi tiết trong các bài viết tiếp theo) để xây dựng mô hình của chúng ta. Bằng cách học, nó có nghĩa là mô hình sẽ xây dựng một số logic của riêng nó.
Khi mô hình đã sẵn sàng thì việc kiểm tra là tốt. Tại thời điểm thử nghiệm, đầu vào được lấy từ 20% dữ liệu còn lại mà mô hình chưa từng thấy trước đây, mô hình sẽ dự đoán một số giá trị và chúng ta sẽ so sánh nó với đầu ra thực tế và tính toán độ chính xác.
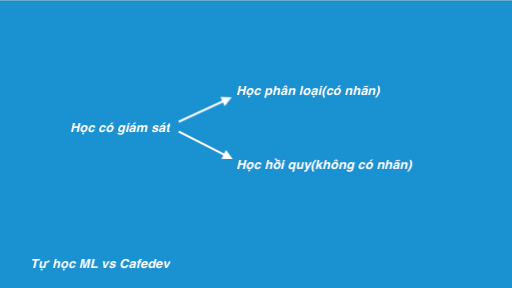
4. Các hình thức học tập có giám sát:
- Phân loại: Đây là một tác vụ Học tập có Giám sát trong đó đầu ra có các nhãn xác định (giá trị rời rạc). Ví dụ trong Hình A ở trên, Đầu ra – Đã mua có các nhãn xác định, tức là 0 hoặc 1; 1 có nghĩa là khách hàng sẽ mua và 0 có nghĩa là khách hàng đó sẽ không mua. Mục tiêu ở đây là dự đoán các giá trị rời rạc thuộc một lớp cụ thể và đánh giá trên cơ sở độ chính xác.
Nó có thể là phân loại nhị phân hoặc đa lớp. Trong phân loại nhị phân, mô hình dự đoán là 0 hoặc 1; có hoặc không nhưng trong trường hợp phân loại nhiều lớp, mô hình dự đoán nhiều hơn một lớp.
Ví dụ: Gmail phân loại thư trong nhiều lớp như xã hội, quảng cáo, cập nhật, diễn đàn.
2. Hồi quy: Đây là một nhiệm vụ Học tập có Giám sát trong đó đầu ra có giá trị liên tục.
Ví dụ trong Hình B ở trên, Đầu ra – Tốc độ gió không có bất kỳ giá trị rời rạc nào nhưng liên tục trong một phạm vi cụ thể. Mục tiêu ở đây là dự đoán một giá trị càng gần với giá trị đầu ra thực tế càng tốt mà mô hình của chúng ta có thể và sau đó đánh giá được thực hiện bằng cách tính toán giá trị lỗi. Sai số càng nhỏ thì độ chính xác của mô hình hồi quy của chúng ta càng lớn.
Ví dụ về thuật toán học có giám sát:
- Hồi quy tuyến tính
- Láng giềng gần nhất
- Guassian Naive Bayes
- Cây quyết định
- Máy vectơ hỗ trợ (SVM)
- Rừng ngẫu nhiên
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


 đối với một số loại Nhiệm vụ, nếu Hiệu suất trong một Nhiệm vụ nhất định được cải thiện với Trải nghiệm){kind=link}