
Phân loại đa lớp là một vấn đề phổ biến trong ML có giám sát.
Bài toán – Cho một tập dữ liệu gồm m ví dụ huấn luyện, mỗi ví dụ chứa thông tin dưới dạng các tính năng khác nhau và một nhãn. Mỗi nhãn tương ứng với một lớp. Trong phân loại đa lớp, chúng ta có một tập hợp hữu hạn các lớp. Mỗi ví dụ đào tạo cũng có n tính năng.
Ví dụ, trong trường hợp nhận dạng các loại trái cây khác nhau, “Hình dạng”, “Màu sắc”, “Bán kính” có thể là các đặc điểm và “Táo”, “Cam”, “Chuối” có thể là các nhãn loại khác nhau.
Trong phân loại đa lớp, chúng ta đào tạo một bộ phân loại bằng cách sử dụng dữ liệu đào tạo của chúng ta và sử dụng bộ phân loại này để phân loại các ví dụ mới.
Mục tiêu của bài viết này – Cafedev sẽ sử dụng các phương pháp phân loại đa lớp khác nhau như KNN, Cây quyết định, SVM, v.v. Chúng ta sẽ so sánh độ chính xác của chúng trên dữ liệu thử nghiệm. Chúng ta sẽ thực hiện tất cả những điều này với học sci-kit (Python). Để biết thông tin về cách cài đặt và sử dụng sci-kit, hãy truy cập http://scikit-learn.org/stable/
Nội dung chính
1. Tiếp cận
- Tải tập dữ liệu từ nguồn.
- Chia tập dữ liệu thành dữ liệu “đào tạo” và “kiểm tra”.
- Huấn luyện cây quyết định, bộ phân loại SVM và KNN trên dữ liệu huấn luyện.
- Sử dụng các bộ phân loại ở trên để dự đoán các nhãn cho dữ liệu thử nghiệm.
- Đo lường độ chính xác và phân loại trực quan.
2. Bộ phân loại cây quyết định
Bộ phân loại cây quyết định là một cách tiếp cận có hệ thống để phân loại đa lớp. Nó đặt ra một bộ câu hỏi cho tập dữ liệu (liên quan đến các thuộc tính / tính năng của nó). Thuật toán phân loại cây quyết định có thể được trực quan hóa trên cây nhị phân. Trên gốc và mỗi nút bên trong, một câu hỏi được đặt ra và dữ liệu trên nút đó được tiếp tục chia thành các bản ghi riêng biệt có các đặc điểm khác nhau. Các lá của cây đề cập đến các lớp mà tập dữ liệu được phân chia. Trong đoạn code sau, chúng ta đào tạo một bộ phân loại cây quyết định trong scikit-learning.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a DescisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
dtree_model = DecisionTreeClassifier(max_depth = 2).fit(X_train, y_train)
dtree_predictions = dtree_model.predict(X_test)
# creating a confusion matrix
cm = confusion_matrix(y_test, dtree_predictions) 3. Bộ phân loại SVM (hỗ trợ Bộ Máy vectơ)
SVM (Bộ Máy vectơ) là một phương pháp phân loại hiệu quả khi vectơ đặc trưng có chiều cao. Trong sci-kit learning, chúng ta có thể chỉ định hàm nhân (ở đây, tuyến tính). Để biết thêm về các hàm nhân và SVM, hãy tham khảo – Hàm nhân | sci-kit learning và SVM.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a linear SVM classifier
from sklearn.svm import SVC
svm_model_linear = SVC(kernel = 'linear', C = 1).fit(X_train, y_train)
svm_predictions = svm_model_linear.predict(X_test)
# model accuracy for X_test
accuracy = svm_model_linear.score(X_test, y_test)
# creating a confusion matrix
cm = confusion_matrix(y_test, svm_predictions) Bộ phân loại KNN (k-láng giềng gần nhất) – KNN hoặc k-láng giềng gần nhất là thuật toán phân loại đơn giản nhất. Thuật toán phân loại này không phụ thuộc vào cấu trúc của dữ liệu. Bất cứ khi nào một ví dụ mới gặp phải, k lân cận gần nhất của nó từ dữ liệu huấn luyện sẽ được kiểm tra. Khoảng cách giữa hai ví dụ có thể là khoảng cách euclide giữa các vectơ đặc trưng của chúng. Lớp đa số trong số k láng giềng gần nhất được coi là lớp cho ví dụ gặp phải.
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a KNN classifier
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 7).fit(X_train, y_train)
# accuracy on X_test
accuracy = knn.score(X_test, y_test)
print accuracy
# creating a confusion matrix
knn_predictions = knn.predict(X_test)
cm = confusion_matrix(y_test, knn_predictions) 4. Bộ phân loại Naive Bayes(KNN)
Phương pháp phân loại Naive Bayes dựa trên định lý Bayes. Nó được gọi là ‘Naive’ vì nó giả định sự độc lập giữa mọi cặp đối tượng trong dữ liệu. Gọi (x1, x2,…, xn) là một vector đặc trưng và y là lớp nhãn tương ứng với vector đặc trưng này.
Áp dụng định lý Bayes,
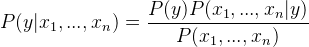
Vì x1, x2,…, xn độc lập với nhau,
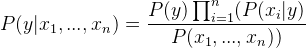
Chèn tỷ lệ tương ứng bằng cách loại bỏ P (x1,…, xn) (vì nó là hằng số).
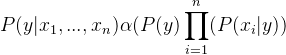
Do đó, lớp nhãn được quyết định bởi,
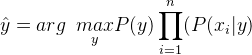
P (y) là tần suất tương đối của lớp nhãn y trong tập dữ liệu huấn luyện.
Trong trường hợp bộ phân loại Gaussian Naive Bayes, P (xi | y) được tính như sau:
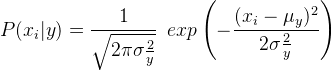
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# importing necessary libraries
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a Naive Bayes classifier
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB().fit(X_train, y_train)
gnb_predictions = gnb.predict(X_test)
# accuracy on X_test
accuracy = gnb.score(X_test, y_test)
print accuracy
# creating a confusion matrix
cm = confusion_matrix(y_test, gnb_predictions) Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}