
Giới thiệu về phân cụm được thảo luận trong bài viết này, khuyên bạn là nên hiểu trước.
Các thuật toán phân cụm có nhiều loại. Tổng quan sau đây sẽ chỉ liệt kê các ví dụ nổi bật nhất về thuật toán phân cụm, vì có thể có hơn 100 thuật toán phân cụm đã được công bố. Không phải tất cả đều cung cấp mô hình cho các cụm của chúng và do đó không thể dễ dàng phân loại được.
Nội dung chính
1. Phương pháp dựa trên phân phối
Đó là một mô hình phân cụm, trong đó chúng ta sẽ điều chỉnh dữ liệu về xác suất nó có thể thuộc cùng một phân phối như thế nào. Nhóm được thực hiện có thể là bình thường hoặc gaussian. Phân phối Gaussian nổi bật hơn khi chúng ta có số lượng bản phân phối cố định và tất cả dữ liệu sắp tới được trang bị vào đó để việc phân phối dữ liệu có thể được tối đa hóa. Điều này dẫn đến việc phân nhóm được thể hiện trong hình: –
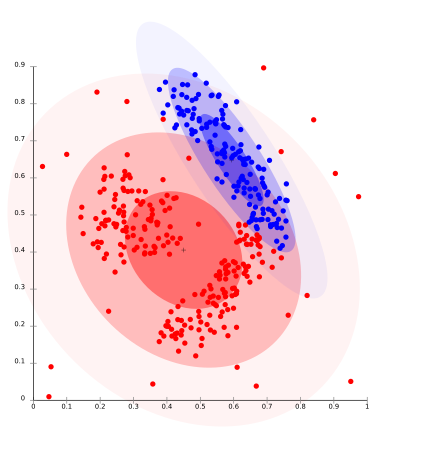
Mô hình này hoạt động tốt trên dữ liệu tổng hợp và các cụm có kích thước đa dạng. Nhưng mô hình này có thể có vấn đề nếu các ràng buộc không được sử dụng để hạn chế độ phức tạp của mô hình. Hơn nữa, phân cụm dựa trên phân phối tạo ra các cụm giả định các mô hình toán học được xác định chính xác bên dưới dữ liệu, một giả định khá mạnh đối với một số phân phối dữ liệu.
Đối với thuật toán tối đa hóa kỳ vọng sử dụng phân phối chuẩn đa biến là một trong những ví dụ phổ biến của thuật toán này.
2. Các phương pháp dựa trên Centroid
Về cơ bản, đây là một trong những thuật toán phân cụm lặp đi lặp lại, trong đó các cụm được hình thành bởi sự gần gũi của các điểm dữ liệu với trung tâm của các cụm. Tại đây, trung tâm cụm, tức là centroid được hình thành sao cho khoảng cách của các điểm dữ liệu với trung tâm là nhỏ nhất. Bài toán này về cơ bản là một trong bài toán NP-Khó và do đó các giải pháp thường được tính gần đúng qua một số thử nghiệm.
Đối với thuật toán Ex- K – mean là một trong những ví dụ phổ biến của thuật toán này.
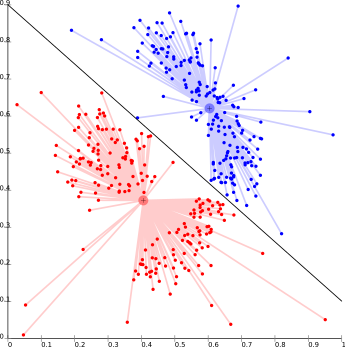
Vấn đề lớn nhất với thuật toán này là chúng ta cần xác định K trước. Nó cũng có vấn đề trong phân phối dựa trên mật độ phân cụm.
3. Các phương pháp dựa trên kết nối
Ý tưởng cốt lõi của mô hình dựa trên kết nối tương tự như mô hình dựa trên Centroid, về cơ bản là xác định các cụm dựa trên sự gần gũi của các điểm dữ liệu. Ở đây chúng tôi làm việc trên quan điểm rằng các điểm dữ liệu gần hơn có hành vi tương tự so với các điểm dữ liệu xa hơn.
Nó không phải là một phân vùng duy nhất của tập dữ liệu, thay vào đó nó cung cấp một hệ thống phân cấp mở rộng của các cụm hợp nhất với nhau ở những khoảng cách nhất định. Ở đây việc lựa chọn hàm khoảng cách là chủ quan. Các mô hình này rất dễ diễn giải nhưng nó thiếu khả năng mở rộng.
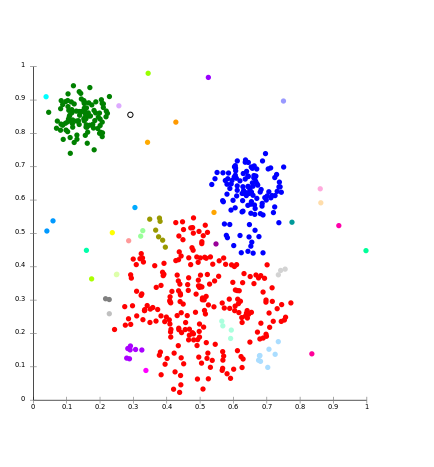
Đối với thuật toán phân cấp Ex và các biến thể của nó.
4. Mô hình mật độ
Trong mô hình phân cụm này sẽ có việc tìm kiếm không gian dữ liệu cho các vùng có mật độ điểm dữ liệu khác nhau trong không gian dữ liệu. Nó cô lập các vùng mật độ khác nhau dựa trên các mật độ khác nhau hiện diện trong không gian dữ liệu.
Đối với Ex- DBSCAN và OPTICS.
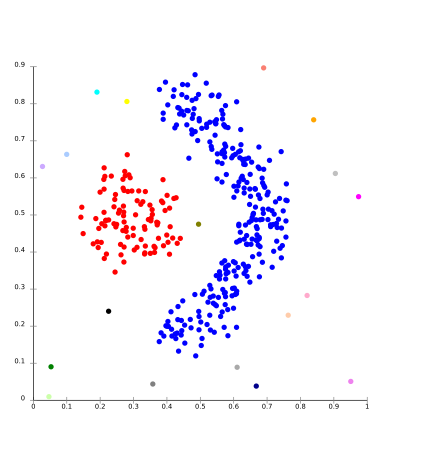
5. Cụm không gian con
Phân cụm không gian con là một vấn đề học tập không có giám sát nhằm mục đích nhóm các điểm dữ liệu thành nhiều cụm sao cho điểm dữ liệu tại một cụm duy nhất nằm xấp xỉ trên không gian con tuyến tính chiều thấp. Phân cụm không gian con là một phần mở rộng của lựa chọn đối tượng cũng giống như phân cụm không gian con lựa chọn đối tượng yêu cầu phương pháp tìm kiếm và tiêu chí đánh giá nhưng ngoài ra phân cụm không gian con giới hạn phạm vi tiêu chí đánh giá. Thuật toán phân cụm không gian con bản địa hóa tìm kiếm thứ nguyên có liên quan và cho phép chúng tìm cụm tồn tại trong nhiều không gian con chồng chéo. Phân cụm không gian con ban đầu có mục đích giải quyết vấn đề thị giác máy tính rất cụ thể có cấu trúc không gian con liên hợp trong dữ liệu nhưng nó ngày càng thu hút sự chú ý trong cộng đồng thống kê và học máy. Mọi người sử dụng công cụ này trong mạng xã hội, giới thiệu phim và tập dữ liệu sinh học. Phân cụm không gian con làm tăng mối quan tâm về quyền riêng tư của dữ liệu vì nhiều ứng dụng như vậy liên quan đến việc xử lý thông tin nhạy cảm. Các điểm dữ liệu được cho là không mạch lạc vì nó chỉ bảo vệ sự riêng tư khác biệt của bất kỳ tính năng nào của người dùng chứ không phải toàn bộ hồ sơ người dùng của cơ sở dữ liệu.
Có hai nhánh phân cụm không gian con dựa trên chiến lược tìm kiếm của chúng.
Các thuật toán từ trên xuống tìm một nhóm ban đầu trong tập hợp đầy đủ thứ nguyên và đánh giá không gian con của mỗi cụm.
Phương pháp tiếp cận từ dưới lên tìm vùng dày đặc trong không gian chiều thấp sau đó kết hợp để tạo thành các cụm.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}