
Nội dung chính
1. Giới thiệu về phân cụm
Về cơ bản nó là một loại phương pháp học tập không giám sát. Phương pháp học không giám sát là một phương pháp mà chúng ta lấy tham chiếu từ các tập dữ liệu bao gồm dữ liệu đầu vào mà không có các phản hồi được gắn nhãn. Nói chung, nó được sử dụng như một quy trình để tìm ra cấu trúc có ý nghĩa, các quy trình cơ bản giải thích, các đặc điểm chung và các nhóm vốn có trong một tập hợp các ví dụ.
Phân cụm là nhiệm vụ phân chia tổng thể hoặc các điểm dữ liệu thành một số nhóm sao cho các điểm dữ liệu trong cùng một nhóm giống với các điểm dữ liệu khác trong cùng một nhóm và khác với các điểm dữ liệu trong các nhóm khác. Về cơ bản, nó là một tập hợp các đối tượng trên cơ sở giống nhau và không giống nhau giữa chúng.
Ví dụ – Các điểm dữ liệu trong biểu đồ dưới đây được nhóm lại với nhau có thể được phân loại thành một nhóm duy nhất. Chúng ta có thể phân biệt các cụm, và chúng ta có thể xác định rằng có 3 cụm trong hình dưới đây.
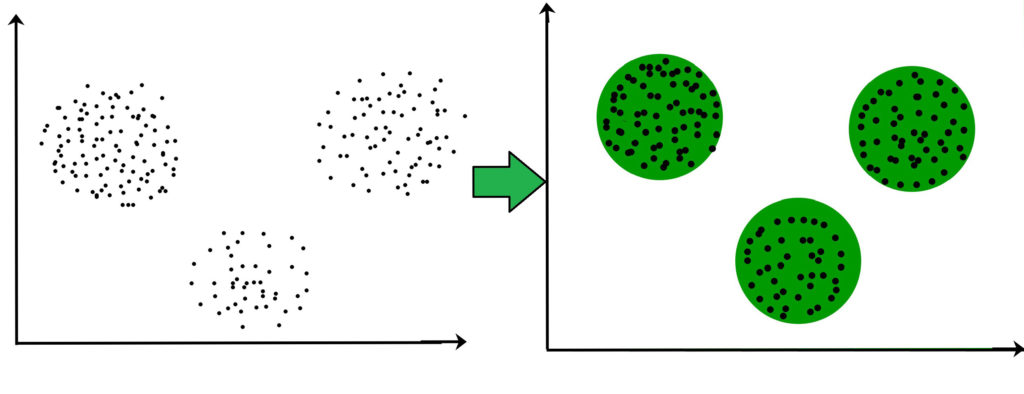
Nó không cần thiết cho các cụm là một hình cầu. Như là :
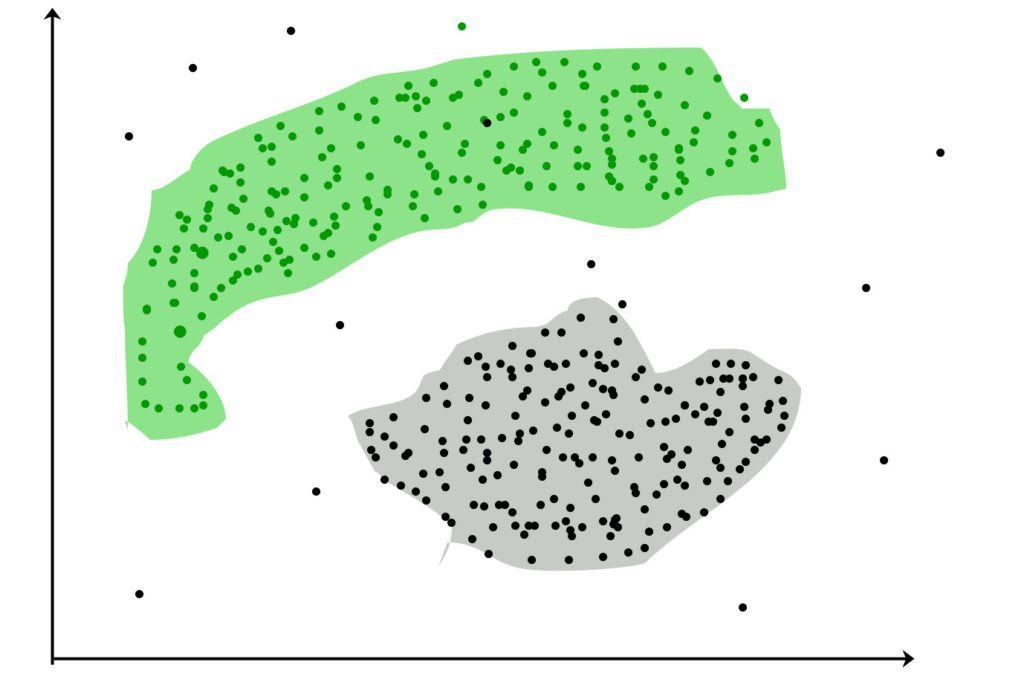
DBSCAN: Phân cụm không gian dựa trên mật độ của các ứng dụng có tiếng ồn
Các điểm dữ liệu này được phân nhóm bằng cách sử dụng khái niệm cơ bản rằng điểm dữ liệu nằm trong giới hạn nhất định từ trung tâm cụm. Các phương pháp và kỹ thuật khoảng cách khác nhau được sử dụng để tính toán các giá trị ngoại lai.
2. Tại sao Phân cụm?
Phân cụm rất quan trọng vì nó xác định nhóm nội tại giữa các dữ liệu không được gắn nhãn hiện có. Không có tiêu chí cho một phân cụm tốt. Nó phụ thuộc vào người dùng, tiêu chí họ có thể sử dụng để đáp ứng nhu cầu của họ là gì. Ví dụ: chúng tôi có thể quan tâm đến việc tìm kiếm đại diện cho các nhóm đồng nhất (giảm dữ liệu), trong việc tìm “các cụm tự nhiên” và mô tả các thuộc tính chưa biết của chúng (kiểu dữ liệu “tự nhiên”), trong việc tìm kiếm các nhóm hữu ích và phù hợp (các lớp dữ liệu “hữu ích”) hoặc trong việc tìm kiếm các đối tượng dữ liệu bất thường (phát hiện ngoại lệ). Thuật toán này phải đưa ra một số giả định tạo nên sự giống nhau của các điểm và mỗi giả định tạo ra các cụm khác nhau và có giá trị như nhau.
3. Các phương pháp phân cụm:
- Phương pháp dựa trên mật độ: Các phương pháp này coi các cụm là vùng dày đặc có một số điểm giống và khác với vùng có mật độ thấp hơn của không gian. Các phương pháp này có độ chính xác tốt và khả năng hợp nhất hai cụm. Ví dụ DBSCAN (Phân cụm không gian dựa trên mật độ của các ứng dụng có tiếng ồn), OPTICS (Điểm thứ tự để xác định cấu trúc phân cụm), v.v.
- Phương pháp dựa trên phân cấp: Các cụm được hình thành trong phương pháp này tạo thành cấu trúc kiểu cây dựa trên phân cấp. Cụm mới được hình thành bằng cách sử dụng cụm đã hình thành trước đó. Nó được chia thành hai loại
- Tổng hợp (cách tiếp cận từ dưới lên)
- Chia nhỏ (cách tiếp cận từ trên xuống)
ví dụ CURE (Phân cụm sử dụng các đại diện), BIRCH (Phân cụm giảm lặp lại cân bằng và sử dụng phân cấp), v.v.
- Phương pháp phân vùng: Các phương pháp này phân vùng các đối tượng thành k cụm và mỗi phân vùng tạo thành một cụm. Phương pháp này được sử dụng để tối ưu hóa chức năng tương tự tiêu chí khách quan chẳng hạn như khi khoảng cách là một tham số chính, ví dụ K-mean, CLARANS (Phân cụm các ứng dụng lớn dựa trên Tìm kiếm ngẫu nhiên), v.v.
- Phương pháp dựa trên lưới: Trong phương pháp này, không gian dữ liệu được xây dựng thành một số lượng hữu hạn các ô tạo thành một cấu trúc giống như lưới. Tất cả hoạt động phân cụm được thực hiện trên các lưới này đều nhanh chóng và không phụ thuộc vào số lượng đối tượng dữ liệu, ví dụ STING (Lưới thông tin thống kê), cụm sóng, CLIQUE (Phân cụm trong nhiệm vụ), v.v.
4. Thuật toán phân cụm:
- Thuật toán phân cụm K-mean – Đây là thuật toán học không giám sát đơn giản nhất để giải quyết vấn đề phân cụm. Thuật toán K-mean phân vùng n quan sát thành k cụm trong đó mỗi quan sát thuộc về cụm với giá trị trung bình gần nhất đóng vai trò là nguyên mẫu của cụm.
5. Các ứng dụng của Clustering trong các lĩnh vực khác nhau
- Tiếp thị: Nó có thể được sử dụng để xác định đặc điểm và khám phá các phân khúc khách hàng cho mục đích tiếp thị.
- Sinh học: Nó có thể được sử dụng để phân loại giữa các loài thực vật và động vật khác nhau.
- Thư viện: Nó được sử dụng để phân nhóm các cuốn sách khác nhau trên cơ sở các chủ đề và thông tin.
- Bảo hiểm: Nó được sử dụng để ghi nhận khách hàng, các chính sách của họ và xác định các gian lận.
- Quy hoạch thành phố: Nó được sử dụng để lập các nhóm nhà và nghiên cứu giá trị của chúng dựa trên vị trí địa lý và các yếu tố khác hiện có.
- Nghiên cứu động đất: Bằng cách tìm hiểu các khu vực bị ảnh hưởng bởi động đất, chúng tôi có thể xác định các khu vực nguy hiểm.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}