
K-mean là một trong những thuật toán phân cụm phổ biến nhất, chủ yếu là do hiệu suất thời gian tốt của nó. Với kích thước ngày càng tăng của các tập dữ liệu được phân tích, thời gian tính toán của K-means tăng lên do hạn chế của nó là cần toàn bộ tập dữ liệu trong bộ nhớ chính. Vì lý do này, một số phương pháp đã được đề xuất để giảm chi phí thời gian và không gian của thuật toán. Một cách tiếp cận khác là thuật toán K-mean lô nhỏ.
Ý tưởng chính của thuật toán Mini Batch K-mean là sử dụng các lô dữ liệu nhỏ ngẫu nhiên có kích thước cố định để chúng có thể được lưu trữ trong bộ nhớ. Mỗi lần lặp, một mẫu ngẫu nhiên mới từ tập dữ liệu được thu thập và được sử dụng để cập nhật các cụm và điều này được lặp lại cho đến khi hội tụ. Mỗi lô nhỏ cập nhật các cụm bằng cách sử dụng kết hợp lồi của các giá trị của nguyên mẫu và dữ liệu, áp dụng tốc độ học giảm theo số lần lặp. Tỷ lệ học tập này là nghịch đảo của số lượng dữ liệu được gán cho một cụm trong quá trình. Khi số lần lặp tăng lên, ảnh hưởng của dữ liệu mới sẽ giảm, do đó, sự hội tụ có thể được phát hiện khi không có thay đổi nào trong các cụm xảy ra trong một số lần lặp liên tiếp.
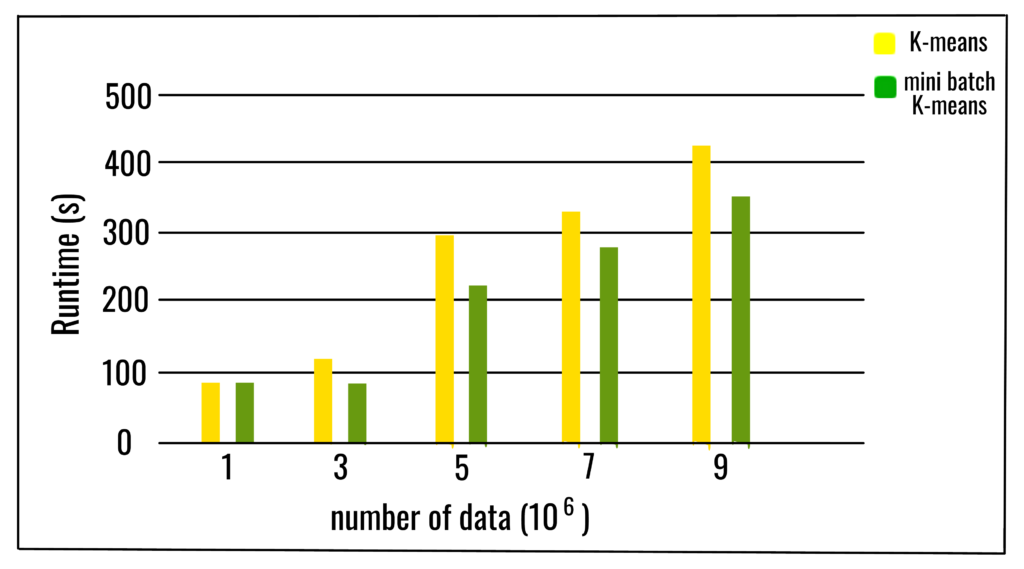
Các kết quả thực nghiệm cho thấy rằng nó có thể tiết kiệm đáng kể thời gian tính toán với chi phí làm giảm chất lượng cụm, nhưng chưa có nghiên cứu sâu rộng về thuật toán để đo lường các đặc tính của bộ dữ liệu, chẳng hạn như số lượng cụm hoặc kích thước của nó, ảnh hưởng đến chất lượng phân vùng.
Thuật toán lấy các lô nhỏ được chọn ngẫu nhiên của tập dữ liệu cho mỗi lần lặp. Mỗi dữ liệu trong lô được gán cho các cụm, tùy thuộc vào vị trí trước đó của các trung tâm cụm. Sau đó, nó cập nhật vị trí của các trung tâm cụm dựa trên các điểm mới từ lô. Bản cập nhật này là bản cập nhật gradient descent, nhanh hơn đáng kể so với bản cập nhật Batch K-Means thông thường.
Dưới đây là thuật toán cho Mini Batch K-mean
Cho tập dữ liệu D = {d1, d2, d3, ..... dn},
Không. số lần lặp t,
kích thước lô b,
Không. của các cụm k.
k cụm C = {c1, c2, c3, ...... ck}
khởi tạo k trung tâm cụm O = {o1, o2, ....... ok}
# _initialize từng cụm
Ci = Φ (1 = <i = <k)
# _initialize không. dữ liệu trong mỗi cụm
Nci = 0 (1 = <i = <k)
for j = 1 to t do:
# M là tập dữ liệu lô và xm
# là mẫu được chọn ngẫu nhiên từ D
M = {xm | 1 = <m = <b}
# bắt trung tâm cụm cho mỗi
# mẫu trong tập dữ liệu hàng loạt
cho m = 1 đến b làm:
oi (xm) = sum (xm) / | c | i (xm ε M và xm ε ci)
kết thúc
# cập nhật trung tâm cụm với từng bộ lô
cho m = 1 đến b làm:
# lấy trung tâm cụm cho xm
oi = oi (xm)
# cập nhật số lượng dữ liệu cho mỗi trung tâm cụm
Nci = Nci + 1
# tính toán tỷ lệ học tập cho mỗi trung tâm cụm
lr = 1 / Nci
# thực hiện bước gradient để cập nhật trung tâm cụm
oi = (1-lr) oi + lr * xm
kết thúc
kết thúcTriển khai Python của thuật toán trên bằng thư viện scikit-learning:
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
from sklearn.cluster import MiniBatchKMeans, KMeans
from sklearn.metrics.pairwise import pairwise_distances_argmin
from sklearn.datasets.samples_generator import make_blobs
# Load data in X
batch_size = 45
centers = [[1, 1], [-2, -1], [1, -2], [1, 9]]
n_clusters = len(centers)
X, labels_true = make_blobs(n_samples = 3000,
centers = centers,
cluster_std = 0.9)
# perform the mini batch K-means
mbk = MiniBatchKMeans(init ='k-means++', n_clusters = 4,
batch_size = batch_size, n_init = 10,
max_no_improvement = 10, verbose = 0)
mbk.fit(X)
mbk_means_cluster_centers = np.sort(mbk.cluster_centers_, axis = 0)
mbk_means_labels = pairwise_distances_argmin(X, mbk_means_cluster_centers)
# print the labels of each data
print(mbk_means_labels) K-mean lô mini nhanh hơn nhưng cho kết quả hơi khác so với K-mean lô bình thường.
Ở đây chúng ta phân cụm một tập hợp dữ liệu, đầu tiên với K-means và sau đó với K-mean lô nhỏ, và vẽ biểu đồ kết quả. Chúng tôi cũng sẽ vẽ biểu đồ các điểm được gắn nhãn khác nhau giữa hai thuật toán.
Khi các cụm số và số lượng dữ liệu tăng lên, việc tiết kiệm tương đối trong thời gian tính toán cũng tăng lên. Việc tiết kiệm thời gian tính toán chỉ đáng chú ý hơn khi số lượng cụm rất lớn. Ảnh hưởng của kích thước lô trong thời gian tính toán cũng rõ ràng hơn khi số lượng cụm lớn hơn. Có thể kết luận rằng, việc tăng số lượng cụm, làm giảm độ tương tự của giải pháp K-mean lô mini với giải pháp K-means. Mặc dù sự thỏa thuận giữa các phân vùng giảm khi số lượng các cụm tăng lên, nhưng hàm mục tiêu không suy giảm theo cùng một tốc độ. Có nghĩa là các phân vùng cuối cùng khác nhau, nhưng chất lượng gần hơn.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}