
Bài viết này trình bày một minh họa về phân cụm K-mean trên một dữ liệu ngẫu nhiên mẫu sử dụng thư viện cv mở.
Điều kiện tiên quyết: Numpy, OpenCV, matplot-lib
Đầu tiên chúng ta hãy trực quan hóa dữ liệu thử nghiệm với Nhiều tính năng bằng công cụ matplot-lib.
# importing required tools
import numpy as np
from matplotlib import pyplot as plt
# creating two test data
X = np.random.randint(10,35,(25,2))
Y = np.random.randint(55,70,(25,2))
Z = np.vstack((X,Y))
Z = Z.reshape((50,2))
# convert to np.float32
Z = np.float32(Z)
plt.xlabel('Test Data')
plt.ylabel('Z samples')
plt.hist(Z,256,[0,256])
plt.show() Ở đây ‘Z’ là một mảng có kích thước 100 và các giá trị nằm trong khoảng từ 0 đến 255. Bây giờ, hãy định hình lại ‘z’ thành một vectơ cột. Nó sẽ hữu ích hơn khi có nhiều hơn một tính năng. Sau đó thay đổi dữ liệu thành kiểu np.float32.
Đầu ra:
Bây giờ, hãy áp dụng thuật toán phân cụm k-Means vào ví dụ tương tự như trong dữ liệu thử nghiệm ở trên và xem hành vi của nó.
1. Các bước liên quan:
1) Đầu tiên chúng ta cần thiết lập một dữ liệu thử nghiệm.
2) Xác định tiêu chí và áp dụng kmeans ().
3) Bây giờ tách dữ liệu.
4) Cuối cùng Vẽ sơ đồ dữ liệu.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
import numpy as np
import cv2
from matplotlib import pyplot as plt
X = np.random.randint(10,45,(25,2))
Y = np.random.randint(55,70,(25,2))
Z = np.vstack((X,Y))
# convert to np.float32
Z = np.float32(Z)
# define criteria and apply kmeans()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center = cv2.kmeans(Z,2,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
# Now separate the data
A = Z[label.ravel()==0]
B = Z[label.ravel()==1]
# Plot the data
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'y', marker = 's')
plt.xlabel('Test Data'),plt.ylabel('Z samples')
plt.show()Output
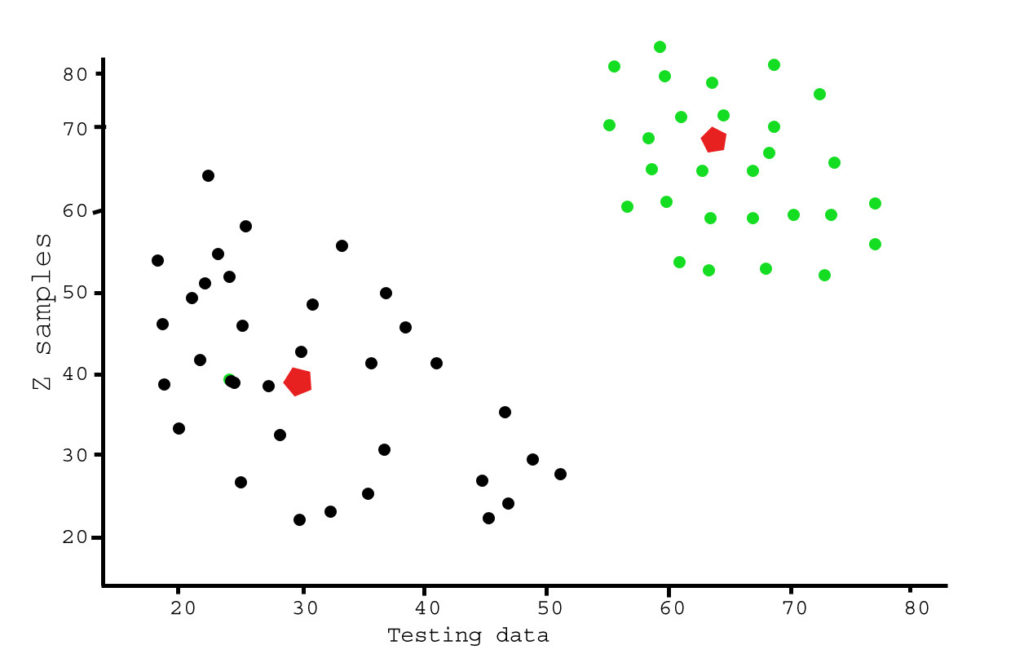
Ví dụ này nhằm minh họa nơi k-mean sẽ tạo ra các cụm có thể có trực quan.
Các ứng dụng:
1) Xác định Dữ liệu Ung thư.
2) Dự đoán Kết quả Học tập của Học sinh.
3) Dự đoán Hoạt động Ma túy.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}