
Học tăng cường là một nhánh của ML, còn được gọi là Học trực tuyến. Nó được sử dụng để quyết định hành động cần thực hiện tại t + 1 dựa trên dữ liệu cho đến thời điểm t. Khái niệm này được sử dụng trong các ứng dụng Trí tuệ nhân tạo như đi bộ. Một ví dụ phổ biến của việc học tăng cường là cờ vua. Ở đây, nhân viên quyết định một loạt các nước đi tùy thuộc vào trạng thái của bàn cờ (môi trường), và phần thưởng có thể được xác định là thắng hoặc thua khi kết thúc trò chơi.
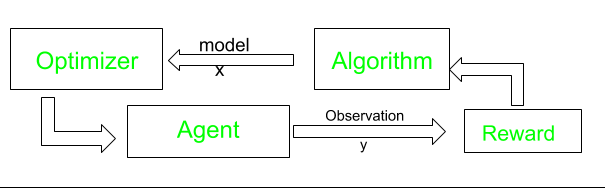
Lấy mẫu Thompson (Lấy mẫu sau hoặc Đối sánh xác suất) là một thuật toán để lựa chọn các hành động giải quyết tình trạng tiến thoái lưỡng nan về thăm dò-khai thác trong bài toán cướp nhiều nhánh. Các hành động được thực hiện nhiều lần và được gọi là thăm dò. Nó sử dụng thông tin đào tạo để đánh giá các hành động được thực hiện thay vì hướng dẫn bằng cách đưa ra các hành động đúng. Đây là điều tạo ra nhu cầu thăm dò tích cực, tìm kiếm thử-và-sai rõ ràng để có hành vi tốt. Dựa trên kết quả của những hành động đó, phần thưởng (1) hoặc hình phạt (0) được trao cho hành động đó đối với máy. Các hành động khác được thực hiện để tối đa hóa phần thưởng có thể cải thiện hiệu suất trong tương lai. Giả sử một người máy phải chọn một số lon và cho vào một hộp đựng. Mỗi lần đặt lon vào thùng chứa, nó sẽ ghi nhớ các bước tiếp theo và tự rèn luyện để thực hiện nhiệm vụ với tốc độ và độ chính xác tốt hơn (phần thưởng). Nếu Robot không thể bỏ lon vào thùng chứa, Robot sẽ không ghi nhớ quy trình đó (do đó tốc độ và hiệu suất sẽ không được cải thiện) và sẽ bị coi là một hình phạt.
Thompson Sampling có một ưu điểm là xu hướng giảm tìm kiếm khi chúng ta nhận được ngày càng nhiều thông tin, điều này bắt chước sự đánh đổi mong muốn trong vấn đề, nơi chúng ta muốn có càng nhiều thông tin càng tốt với ít lượt tìm kiếm hơn. Do đó, Thuật toán này có xu hướng “định hướng tìm kiếm” hơn khi chúng ta có ít dữ liệu hơn và ít “định hướng tìm kiếm” hơn khi chúng ta có nhiều dữ liệu.
Nội dung chính
Vấn đề về băng cướp đa vũ trang
Multi-nhánh Bandit đồng nghĩa với một máy đánh bạc có nhiều nhánh. Mỗi lựa chọn hành động giống như một trò chơi của một trong những đòn bẩy của máy đánh bạc và phần thưởng là phần thưởng cho việc trúng giải độc đắc. Thông qua các lựa chọn hành động lặp đi lặp lại, bạn có thể tối đa hóa số tiền thắng của mình bằng cách tập trung hành động vào các đòn bẩy tốt nhất. Mỗi máy cung cấp một phần thưởng khác nhau từ phân phối xác suất so với phần thưởng trung bình cụ thể cho máy. Nếu không biết những xác suất này, con bạc phải tối đa hóa tổng phần thưởng kiếm được thông qua một chuỗi các động tác kéo. Nếu bạn duy trì ước tính của các giá trị hành động, thì tại bất kỳ bước nào cũng có ít nhất một hành động có giá trị ước tính lớn nhất. Chúng tôi gọi đây là một hành động tham lam. Tương tự với vấn đề này có thể được hiển thị quảng cáo bất cứ khi nào người dùng truy cập một trang web. Arms là quảng cáo được hiển thị cho người dùng mỗi khi họ kết nối với một trang web. Mỗi lần người dùng kết nối với trang sẽ tạo ra xung quanh. Tại mỗi vòng, chúng tôi chọn một quảng cáo để hiển thị cho người dùng. Tại mỗi vòng n, quảng cáo tôi tặng thưởng ri (n) ε {0, 1}: ri (n) = 1 nếu người dùng nhấp vào quảng cáo i, 0 nếu người dùng không nhấp vào. Mục tiêu của thuật toán sẽ là tối đa hóa phần thưởng. Một sự tương tự khác là một bác sĩ lựa chọn giữa các phương pháp điều trị thử nghiệm cho một loạt bệnh nhân nặng. Mỗi lựa chọn hành động là một lựa chọn điều trị và mỗi phần thưởng là sự sống còn hoặc hạnh phúc của bệnh nhân.
Thuật toán

Một số ứng dụng thực tế
- Hệ thống đề xuất dựa trên mục Netflix: Hình ảnh liên quan đến phim / chương trình được hiển thị cho người dùng theo cách họ có nhiều khả năng xem hơn.
- Đấu thầu và trao đổi chứng khoán: Dự đoán Cổ phiếu dựa trên dữ liệu hiện tại của các giải thưởng cổ phiếu.
- Điều khiển đèn giao thông: Dự đoán độ trễ của tín hiệu.
- Tự động hóa trong các ngành: Bots và Máy móc để vận chuyển và phân phối các mặt hàng mà không cần sự can thiệp của con người.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}