
Điều kiện tiên quyết: Kỹ thuật Q-Learning.
Học tăng cường là một loại mô hình ML trong đó thuật toán học được đào tạo không dựa trên dữ liệu đặt trước mà dựa trên hệ thống phản hồi. Các thuật toán này được coi là tương lai của ML vì chúng loại bỏ chi phí thu thập và làm sạch dữ liệu.
Trong bài viết này, cafedev sẽ trình bày cách triển khai thuật toán Học tăng cường cơ bản được gọi là kỹ thuật Q-Learning. Trong phần trình diễn này, chúng ta cố gắng dạy một bot đi đến đích bằng kỹ thuật Q-Learning.
Bước 1: Nhập các thư viện bắt buộc
import numpy as np
import pylab as pl
import networkx as nx Bước 2: Xác định và hình dung biểu đồ
edges = [(0, 1), (1, 5), (5, 6), (5, 4), (1, 2),
(1, 3), (9, 10), (2, 4), (0, 6), (6, 7),
(8, 9), (7, 8), (1, 7), (3, 9)]
goal = 10
G = nx.Graph()
G.add_edges_from(edges)
pos = nx.spring_layout(G)
nx.draw_networkx_nodes(G, pos)
nx.draw_networkx_edges(G, pos)
nx.draw_networkx_labels(G, pos)
pl.show() 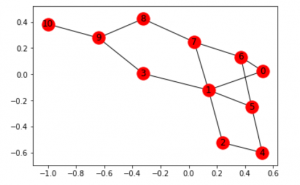
Lưu ý: Biểu đồ trên có thể không giống khi tái tạo mã vì thư viện networkx trong python tạo ra một biểu đồ ngẫu nhiên từ các cạnh đã cho.
Bước 3: Xác định phần thưởng mà hệ thống dành cho bot
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
MATRIX_SIZE = 11
M = np.matrix(np.ones(shape =(MATRIX_SIZE, MATRIX_SIZE)))
M *= -1
for point in edges:
print(point)
if point[1] == goal:
M[point] = 100
else:
M[point] = 0
if point[0] == goal:
M[point[::-1]] = 100
else:
M[point[::-1]]= 0
# reverse of point
M[goal, goal]= 100
print(M)
# add goal point round trip 
Bước 4: Xác định một số chức năng tiện ích sẽ được sử dụng trong khóa đào tạo
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
Q = np.matrix(np.zeros([MATRIX_SIZE, MATRIX_SIZE]))
gamma = 0.75
# learning parameter
initial_state = 1
# Determines the available actions for a given state
def available_actions(state):
current_state_row = M[state, ]
available_action = np.where(current_state_row >= 0)[1]
return available_action
available_action = available_actions(initial_state)
# Chooses one of the available actions at random
def sample_next_action(available_actions_range):
next_action = int(np.random.choice(available_action, 1))
return next_action
action = sample_next_action(available_action)
def update(current_state, action, gamma):
max_index = np.where(Q[action, ] == np.max(Q[action, ]))[1]
if max_index.shape[0] > 1:
max_index = int(np.random.choice(max_index, size = 1))
else:
max_index = int(max_index)
max_value = Q[action, max_index]
Q[current_state, action] = M[current_state, action] + gamma * max_value
if (np.max(Q) > 0):
return(np.sum(Q / np.max(Q)*100))
else:
return (0)
# Updates the Q-Matrix according to the path chosen
update(initial_state, action, gamma) Bước 5: Đào tạo và đánh giá bot bằng Q-Matrix
scores = []
for i in range(1000):
current_state = np.random.randint(0, int(Q.shape[0]))
available_action = available_actions(current_state)
action = sample_next_action(available_action)
score = update(current_state, action, gamma)
scores.append(score)
# print("Trained Q matrix:")
# print(Q / np.max(Q)*100)
# You can uncomment the above two lines to view the trained Q matrix
# Testing
current_state = 0
steps = [current_state]
while current_state != 10:
next_step_index = np.where(Q[current_state, ] == np.max(Q[current_state, ]))[1]
if next_step_index.shape[0] > 1:
next_step_index = int(np.random.choice(next_step_index, size = 1))
else:
next_step_index = int(next_step_index)
steps.append(next_step_index)
current_state = next_step_index
print("Most efficient path:")
print(steps)
pl.plot(scores)
pl.xlabel('No of iterations')
pl.ylabel('Reward gained')
pl.show()Most efficient path: [0,1,3,9,10]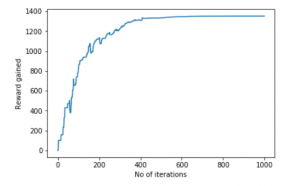
Bây giờ, hãy đưa bot này đến một môi trường thực tế hơn. Chúng ta hãy tưởng tượng rằng bot là một thám tử và đang cố gắng tìm ra vị trí của một cái vợt ma túy lớn. Anh ta đương nhiên kết luận rằng những người bán ma túy sẽ không bán sản phẩm của họ ở một địa điểm mà cảnh sát biết là thường xuyên lui tới và các địa điểm bán thuốc nằm gần vị trí của người bán ma túy. Ngoài ra, người bán để lại dấu vết sản phẩm của họ ở nơi họ bán và điều này có thể giúp thám tử tìm ra vị trí cần thiết. Chúng tôi muốn đào tạo bot của mình để tìm vị trí bằng cách sử dụng các Đầu mối môi trường này.
Bước 6: Xác định và hình dung biểu đồ mới với các manh mối về môi trường
# Defining the locations of the police and the drug traces
police = [2, 4, 5]
drug_traces = [3, 8, 9]
G = nx.Graph()
G.add_edges_from(edges)
mapping = {0:'0 - Detective', 1:'1', 2:'2 - Police', 3:'3 - Drug traces',
4:'4 - Police', 5:'5 - Police', 6:'6', 7:'7', 8:'Drug traces',
9:'9 - Drug traces', 10:'10 - Drug racket location'}
H = nx.relabel_nodes(G, mapping)
pos = nx.spring_layout(H)
nx.draw_networkx_nodes(H, pos, node_size =[200, 200, 200, 200, 200, 200, 200, 200])
nx.draw_networkx_edges(H, pos)
nx.draw_networkx_labels(H, pos)
pl.show() 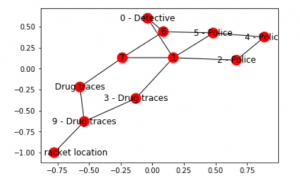
Lưu ý: Biểu đồ trên có thể trông hơi khác so với biểu đồ trước nhưng trên thực tế, chúng là những biểu đồ giống nhau. Điều này là do vị trí ngẫu nhiên của các nút bởi thư viện networkx.
Bước 7: Xác định một số chức năng tiện ích cho quá trình đào tạo
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
Q = np.matrix(np.zeros([MATRIX_SIZE, MATRIX_SIZE]))
env_police = np.matrix(np.zeros([MATRIX_SIZE, MATRIX_SIZE]))
env_drugs = np.matrix(np.zeros([MATRIX_SIZE, MATRIX_SIZE]))
initial_state = 1
# Same as above
def available_actions(state):
current_state_row = M[state, ]
av_action = np.where(current_state_row >= 0)[1]
return av_action
# Same as above
def sample_next_action(available_actions_range):
next_action = int(np.random.choice(available_action, 1))
return next_action
# Exploring the environment
def collect_environmental_data(action):
found = []
if action in police:
found.append('p')
if action in drug_traces:
found.append('d')
return (found)
available_action = available_actions(initial_state)
action = sample_next_action(available_action)
def update(current_state, action, gamma):
max_index = np.where(Q[action, ] == np.max(Q[action, ]))[1]
if max_index.shape[0] > 1:
max_index = int(np.random.choice(max_index, size = 1))
else:
max_index = int(max_index)
max_value = Q[action, max_index]
Q[current_state, action] = M[current_state, action] + gamma * max_value
environment = collect_environmental_data(action)
if 'p' in environment:
env_police[current_state, action] += 1
if 'd' in environment:
env_drugs[current_state, action] += 1
if (np.max(Q) > 0):
return(np.sum(Q / np.max(Q)*100))
else:
return (0)
# Same as above
update(initial_state, action, gamma)
def available_actions_with_env_help(state):
current_state_row = M[state, ]
av_action = np.where(current_state_row >= 0)[1]
# if there are multiple routes, dis-favor anything negative
env_pos_row = env_matrix_snap[state, av_action]
if (np.sum(env_pos_row < 0)):
# can we remove the negative directions from av_act?
temp_av_action = av_action[np.array(env_pos_row)[0]>= 0]
if len(temp_av_action) > 0:
av_action = temp_av_action
return av_action
# Determines the available actions according to the environmentBước 8: Hình dung ma trận môi trường
scores = []
for i in range(1000):
current_state = np.random.randint(0, int(Q.shape[0]))
available_action = available_actions(current_state)
action = sample_next_action(available_action)
score = update(current_state, action, gamma)
# print environmental matrices
print('Police Found')
print(env_police)
print('')
print('Drug traces Found')
print(env_drugs) 

Bước 9: Đào tạo và đánh giá mô hình
scores = []
for i in range(1000):
current_state = np.random.randint(0, int(Q.shape[0]))
available_action = available_actions_with_env_help(current_state)
action = sample_next_action(available_action)
score = update(current_state, action, gamma)
scores.append(score)
pl.plot(scores)
pl.xlabel('Number of iterations')
pl.ylabel('Reward gained')
pl.show() 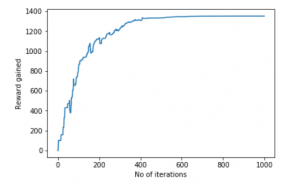
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}