
Trong ML, gradient descent là một kỹ thuật tối ưu hóa được sử dụng để tính toán các tham số (hệ số và độ chệch) cho các thuật toán như hồi quy tuyến tính, hồi quy logistic, mạng nơ-ron, v.v. Trong kỹ thuật này, chúng ta lặp đi lặp lại nhiều lần qua tập huấn luyện và cập nhật mô hình các tham số phù hợp với gradient của lỗi đối với tập huấn luyện.
Tùy thuộc vào số lượng các ví dụ đào tạo được xem xét trong việc cập nhật các tham số mô hình, chúng tôi có 3 loại mô tả gradient:
- Batch Gradient Descent: Các thông số được cập nhật sau khi tính toán gradient của lỗi liên quan đến toàn bộ tập huấn luyện
- Stochastic Gradient Descent: Các thông số được cập nhật sau khi tính toán gradient của lỗi liên quan đến một ví dụ đào tạo duy nhất
- Độ dốc chuyển màu theo lô nhỏ: Các thông số được cập nhật sau khi tính toán độ dốc của lỗi đối với một tập hợp con của tập huấn luyện
| Batch Gradient Descent Stochastic | Gradient Descent | Mini-Batch Gradient Descent |
| Vì toàn bộ dữ liệu huấn luyện được xem xét trước khi thực hiện một bước theo hướng gradient, do đó, cần rất nhiều thời gian để thực hiện một bản cập nhật duy nhất | Vì chỉ một ví dụ huấn luyện duy nhất được xem xét trước khi thực hiện một bước theo hướng gradient, chúng ta buộc phải lặp lại tập huấn luyện và do đó không thể khai thác tốc độ liên quan đến vectơ hóa mã | Vì một tập hợp con các ví dụ huấn luyện được xem xét, nó có thể cập nhật nhanh các thông số mô hình và cũng có thể khai thác tốc độ liên quan đến vectơ hóa mã. |
| Nó thực hiện cập nhật trơn tru các thông số mô hình | Nó tạo ra các cập nhật thông số rất ồn ào | Tùy thuộc vào kích thước lô, các bản cập nhật có thể được thực hiện ít ồn hơn – kích thước lô lớn hơn ít ồn ào hơn là bản cập nhật |
Do đó, sự giảm dần gradient theo lô nhỏ tạo ra sự thỏa hiệp giữa sự hội tụ nhanh chóng và nhiễu liên quan đến cập nhật gradient, điều này làm cho nó trở thành một thuật toán linh hoạt và mạnh mẽ hơn.
Nội dung chính
1. Độ dốc chuyển tiếp theo lô nhỏ:
Thuật toán
Đặt theta = thông số mô hình và max_iters = số kỷ nguyên.
cho itr = 1, 2, 3,…, max_iters:
cho mini_batch (X_mini, y_mini):
- Chuyển tiếp trên lô X_mini:
- Đưa ra dự đoán về lô nhỏ
- Tính toán lỗi trong dự đoán (J (theta)) với giá trị hiện tại của các tham số
- Thẻ lùi:
- Tính gradient (theta) = đạo hàm riêng của J (theta) w.r.t. theta
- Cập nhật các thông số:
- theta = theta – learning_rate * gradient (theta)
2. Dưới đây là triển khai Python:
Bước # 1: Bước đầu tiên là nhập các phần phụ thuộc, tạo dữ liệu cho hồi quy tuyến tính và trực quan hóa dữ liệu đã tạo. Chúng ta đã tạo ra 8000 ví dụ dữ liệu, mỗi ví dụ có 2 thuộc tính / tính năng. Các ví dụ dữ liệu này được chia thành tập huấn luyện (X_train, y_train) và tập thử nghiệm (X_test, y_test) có 7200 và 800 ví dụ tương ứng.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# importing dependencies
import numpy as np
import matplotlib.pyplot as plt
# creating data
mean = np.array([5.0, 6.0])
cov = np.array([[1.0, 0.95], [0.95, 1.2]])
data = np.random.multivariate_normal(mean, cov, 8000)
# visualising data
plt.scatter(data[:500, 0], data[:500, 1], marker = '.')
plt.show()
# train-test-split
data = np.hstack((np.ones((data.shape[0], 1)), data))
split_factor = 0.90
split = int(split_factor * data.shape[0])
X_train = data[:split, :-1]
y_train = data[:split, -1].reshape((-1, 1))
X_test = data[split:, :-1]
y_test = data[split:, -1].reshape((-1, 1))
print("Number of examples in training set = % d"%(X_train.shape[0]))
print("Number of examples in testing set = % d"%(X_test.shape[0])) Output:

Số lượng ví dụ trong tập huấn luyện = 7200
Số lượng ví dụ trong bộ thử nghiệm = 800
Bước # 2: Tiếp theo, chúng ta viết code để thực hiện hồi quy tuyến tính bằng cách sử dụng gradient descent theo lô nhỏ.
gradientDescent() là hàm trình điều khiển chính và các hàm khác là hàm trợ giúp được sử dụng để đưa ra dự đoán – hypothesis(), độ dốc tính toán – gradient(), lỗi tính toán – cost() và tạo lô nhỏ – create_mini_batches (). Hàm trình điều khiển khởi tạo các tham số, tính toán bộ tham số tốt nhất cho mô hình và trả về các tham số này cùng với danh sách chứa lịch sử lỗi khi các tham số được cập nhật.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# linear regression using "mini-batch" gradient descent
# function to compute hypothesis / predictions
def hypothesis(X, theta):
return np.dot(X, theta)
# function to compute gradient of error function w.r.t. theta
def gradient(X, y, theta):
h = hypothesis(X, theta)
grad = np.dot(X.transpose(), (h - y))
return grad
# function to compute the error for current values of theta
def cost(X, y, theta):
h = hypothesis(X, theta)
J = np.dot((h - y).transpose(), (h - y))
J /= 2
return J[0]
# function to create a list containing mini-batches
def create_mini_batches(X, y, batch_size):
mini_batches = []
data = np.hstack((X, y))
np.random.shuffle(data)
n_minibatches = data.shape[0] // batch_size
i = 0
for i in range(n_minibatches + 1):
mini_batch = data[i * batch_size:(i + 1)*batch_size, :]
X_mini = mini_batch[:, :-1]
Y_mini = mini_batch[:, -1].reshape((-1, 1))
mini_batches.append((X_mini, Y_mini))
if data.shape[0] % batch_size != 0:
mini_batch = data[i * batch_size:data.shape[0]]
X_mini = mini_batch[:, :-1]
Y_mini = mini_batch[:, -1].reshape((-1, 1))
mini_batches.append((X_mini, Y_mini))
return mini_batches
# function to perform mini-batch gradient descent
def gradientDescent(X, y, learning_rate = 0.001, batch_size = 32):
theta = np.zeros((X.shape[1], 1))
error_list = []
max_iters = 3
for itr in range(max_iters):
mini_batches = create_mini_batches(X, y, batch_size)
for mini_batch in mini_batches:
X_mini, y_mini = mini_batch
theta = theta - learning_rate * gradient(X_mini, y_mini, theta)
error_list.append(cost(X_mini, y_mini, theta))
return theta, error_list Gọi hàm gradientDescent() để tính toán các tham số của mô hình (theta) và hình dung sự thay đổi trong hàm lỗi.
theta, error_list = gradientDescent(X_train, y_train)
print("Bias = ", theta[0])
print("Coefficients = ", theta[1:])
# visualising gradient descent
plt.plot(error_list)
plt.xlabel("Number of iterations")
plt.ylabel("Cost")
plt.show() Output:
Bias = [0.81830471]
Coefficients = [[1.04586595]]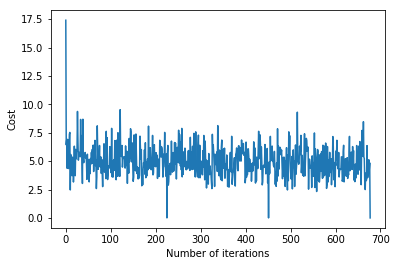
Bước # 3: Cuối cùng, chúng ta đưa ra dự đoán trên bộ thử nghiệm và tính toán sai số tuyệt đối trung bình trong các dự đoán.
# predicting output for X_test
y_pred = hypothesis(X_test, theta)
plt.scatter(X_test[:, 1], y_test[:, ], marker = '.')
plt.plot(X_test[:, 1], y_pred, color = 'orange')
plt.show()
# calculating error in predictions
error = np.sum(np.abs(y_test - y_pred) / y_test.shape[0])
print("Mean absolute error = ", error) Output:
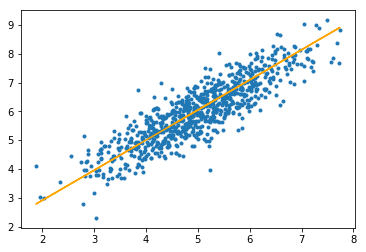
Sai số tuyệt đối trung bình = 0,4366644295854125
Đường màu cam biểu thị hàm giả thuyết cuối cùng: theta [0] + theta [1] * X_test [:, 1] + theta [2] * X_test [:, 2] = 0
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


 cho các thuật toán như hồi quy tuyến tính, hồi quy logistic, mạng nơ-ron, v.v){kind=link}