
Cây quyết định là một công cụ ra quyết định sử dụng cấu trúc cây giống như lưu đồ hoặc là một mô hình về các quyết định và tất cả các kết quả có thể có của chúng, bao gồm cả kết quả, chi phí đầu vào và tiện ích.
Thuật toán cây quyết định thuộc loại thuật toán học có giám sát. Nó hoạt động cho cả các biến đầu ra liên tục cũng như phân loại.
Các nhánh / cạnh đại diện cho kết quả của nút và các nút có:
Điều kiện [Mã quyết định]
Kết quả [Nút kết thúc]
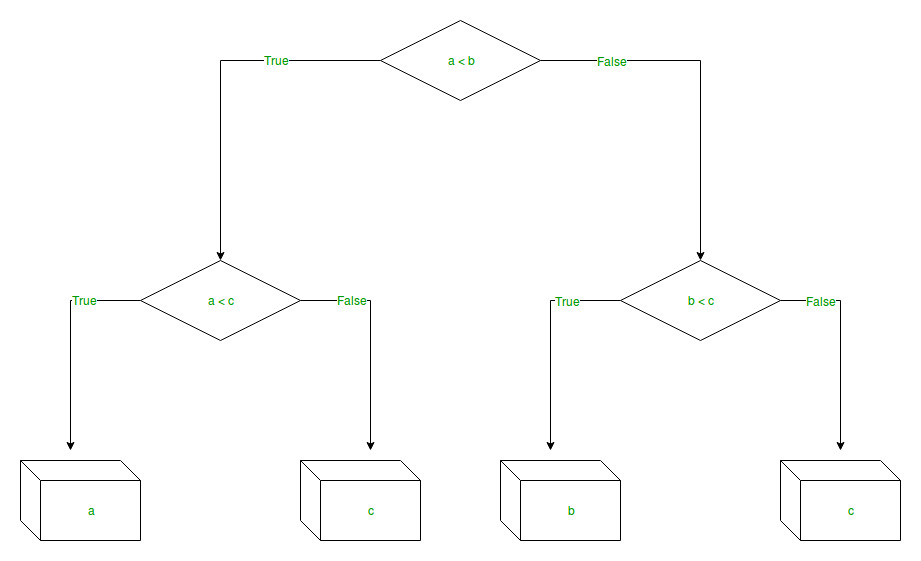
Các nhánh / cạnh đại diện cho sự thật / sai của câu lệnh và đưa ra quyết định dựa trên điều đó trong ví dụ dưới đây hiển thị cây quyết định đánh giá số nhỏ nhất trong ba số:
Hồi quy cây quyết định:
Hồi quy cây quyết định quan sát các đặc điểm của một đối tượng và đào tạo một mô hình trong cấu trúc của cây để dự đoán dữ liệu trong tương lai nhằm tạo ra đầu ra liên tục có ý nghĩa. Đầu ra liên tục có nghĩa là đầu ra / kết quả không rời rạc, tức là nó không được biểu diễn chỉ bằng một tập hợp số hoặc giá trị rời rạc, đã biết.
Ví dụ về đầu ra rời rạc: Mô hình dự đoán thời tiết dự đoán có hay không có mưa trong một ngày cụ thể.
Ví dụ về sản lượng liên tục: Mô hình dự đoán lợi nhuận cho biết lợi nhuận có thể có được từ việc bán một sản phẩm.
Ở đây, các giá trị liên tục được dự đoán với sự trợ giúp của mô hình hồi quy cây quyết định.
Hãy xem việc triển khai từng bước –
Bước 1: Nhập các thư viện bắt buộc
//Python
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# import numpy package for arrays and stuff
import numpy as np
# import matplotlib.pyplot for plotting our result
import matplotlib.pyplot as plt
# import pandas for importing csv files
import pandas as pd Bước 2: Khởi tạo và in Dataset.
# import dataset
# dataset = pd.read_csv('Data.csv')
# alternatively open up .csv file to read data
dataset = np.array(
[['Asset Flip', 100, 1000],
['Text Based', 500, 3000],
['Visual Novel', 1500, 5000],
['2D Pixel Art', 3500, 8000],
['2D Vector Art', 5000, 6500],
['Strategy', 6000, 7000],
['First Person Shooter', 8000, 15000],
['Simulator', 9500, 20000],
['Racing', 12000, 21000],
['RPG', 14000, 25000],
['Sandbox', 15500, 27000],
['Open-World', 16500, 30000],
['MMOFPS', 25000, 52000],
['MMORPG', 30000, 80000]
])
# print the dataset
print(dataset) 
Bước 3: Chọn tất cả các hàng và cột 1 từ tập dữ liệu thành “X”
# select all rows by : and column 1
# by 1:2 representing features
X = dataset[:, 1:2].astype(int)
# print X
print(X) 
Bước 4: Chọn tất cả các hàng và cột 2 từ tập dữ liệu thành “y”
# select all rows by : and column 2
# by 2 to Y representing labels
y = dataset[:, 2].astype(int)
# print y
print(y) 
Bước 5: Điều chỉnh hồi quy cây quyết định với tập dữ liệu
# import the regressor
from sklearn.tree import DecisionTreeRegressor
# create a regressor object
regressor = DecisionTreeRegressor(random_state = 0)
# fit the regressor with X and Y data
regressor.fit(X, y) 
Bước 6: Dự đoán giá trị mới
# predicting a new value
# test the output by changing values, like 3750
y_pred = regressor.predict(3750)
# print the predicted price
print("Predicted price: % d\n"% y_pred)
Predicted price: 8000Bước 7: Hình dung kết quả
//Python
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# arange for creating a range of values
# from min value of X to max value of X
# with a difference of 0.01 between two
# consecutive values
X_grid = np.arange(min(X), max(X), 0.01)
# reshape for reshaping the data into
# a len(X_grid)*1 array, i.e. to make
# a column out of the X_grid values
X_grid = X_grid.reshape((len(X_grid), 1))
# scatter plot for original data
plt.scatter(X, y, color = 'red')
# plot predicted data
plt.plot(X_grid, regressor.predict(X_grid), color = 'blue')
# specify title
plt.title('Profit to Production Cost (Decision Tree Regression)')
# specify X axis label
plt.xlabel('Production Cost')
# specify Y axis label
plt.ylabel('Profit')
# show the plot
plt.show() 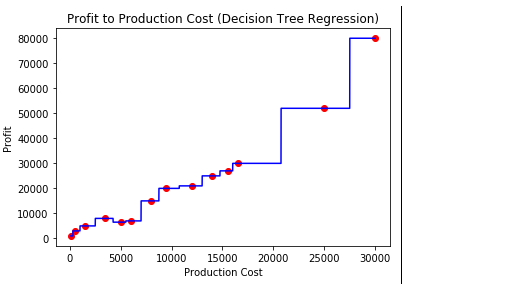
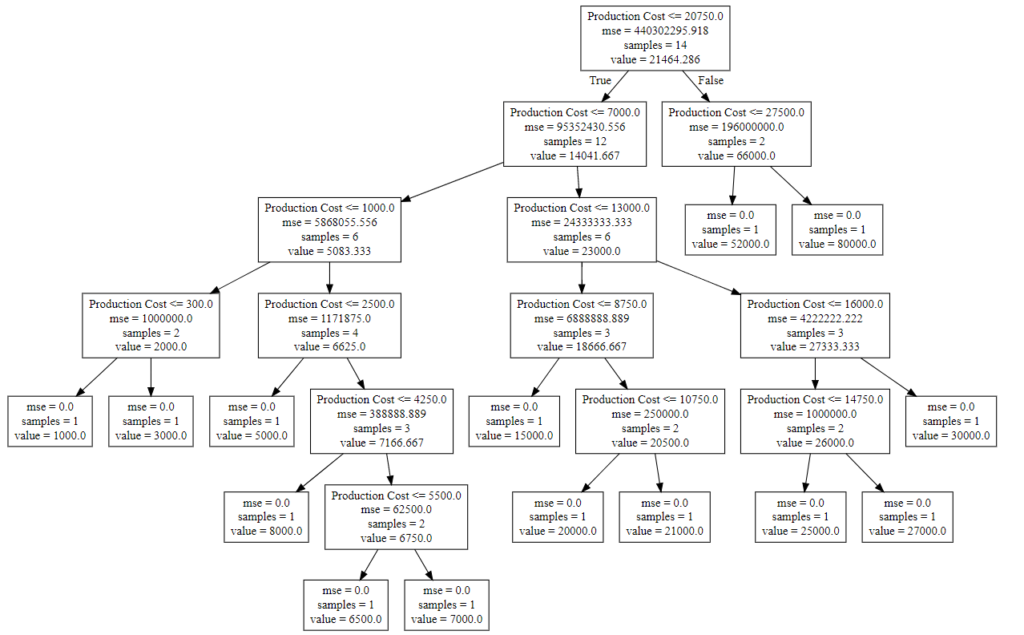
Bước 8: Cây cuối cùng được xuất và hiển thị trong CẤU TRÚC CÂY bên dưới, được hiển thị trực quan bằng cách sử dụng http://www.webgraphviz.com/ bằng cách sao chép dữ liệu từ tệp ‘tree.dot’.
# import export_graphviz
from sklearn.tree import export_graphviz
# export the decision tree to a tree.dot file
# for visualizing the plot easily anywhere
export_graphviz(regressor, out_file ='tree.dot',
feature_names =['Production Cost']) Đầu ra (Cây quyết định):
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}