
Điều kiện tiên quyết: Hiểu về hồi quy logistic
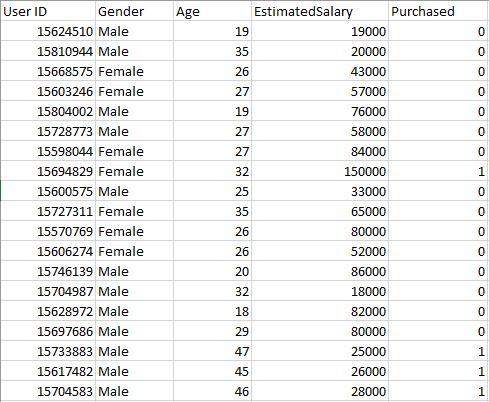
Cơ sở dữ liệu người dùng – Tập dữ liệu này chứa thông tin của người dùng từ cơ sở dữ liệu công ty. Nó chứa thông tin về UserID, Giới tính, Tuổi, Ước tính giá trị, Đã mua. Chúng ta đang sử dụng tập dữ liệu này để dự đoán rằng người dùng có mua sản phẩm mới ra mắt của công ty hay không.
Dữ liệu –
Tải User_Data
Hãy tạo mô hình Hồi quy logistic, dự đoán liệu người dùng có mua sản phẩm hay không.
Thư viện Inputing
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt Đang tải tập dữ liệu – User_Data
filter_none
dataset = pd.read_csv('...\\User_Data.csv') Bây giờ, để dự đoán liệu người dùng có mua sản phẩm hay không, người ta cần tìm hiểu mối quan hệ giữa Tuổi và Mức lương ước tính. Ở đây User ID và Giới tính không phải là yếu tố quan trọng để tìm ra điều này.
# input
x = dataset.iloc[:, [2, 3]].values
# output
y = dataset.iloc[:, 4].values Tách tập dữ liệu để đào tạo và kiểm tra. 75% dữ liệu được sử dụng để đào tạo mô hình và 25% dữ liệu được sử dụng để kiểm tra hiệu suất của mô hình của chúng ta.
from sklearn.cross_validation import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(
x, y, test_size = 0.25, random_state = 0) Bây giờ, điều rất quan trọng là phải thực hiện mở rộng đặc điểm ở đây vì giá trị Độ tuổi và Mức lương ước tính nằm trong các phạm vi khác nhau. Nếu chúng ta không chia tỷ lệ các đặc điểm thì đặc điểm Mức lương ước tính sẽ thống trị đặc điểm Độ tuổi khi mô hình tìm thấy người hàng xóm gần nhất với điểm dữ liệu trong không gian dữ liệu.
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
xtrain = sc_x.fit_transform(xtrain)
xtest = sc_x.transform(xtest)
print (xtrain[0:10, :])Output:
[[ 0.58164944 -0.88670699]
[-0.60673761 1.46173768]
[-0.01254409 -0.5677824 ]
[-0.60673761 1.89663484]
[ 1.37390747 -1.40858358]
[ 1.47293972 0.99784738]
[ 0.08648817 -0.79972756]
[-0.01254409 -0.24885782]
[-0.21060859 -0.5677824 ]
[-0.21060859 -0.19087153]]Ở đây, một lần nữa thấy rằng các giá trị của các đặc điểm Tuổi và Lương ước tính được ẩn và bây giờ ở đó từ -1 đến 1. Do đó, mỗi đặc điểm sẽ đóng góp như nhau trong việc đưa ra quyết định, tức là hoàn thiện giả thuyết.
Cuối cùng, chúng ta đang đào tạo mô hình hồi quy logistic của mình.
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(xtrain, ytrain) Sau khi đào tạo mô hình, đã đến lúc sử dụng nó để dự đoán trên dữ liệu thử nghiệm.
y_pred = classifier.predict(xtest)Hãy kiểm tra hiệu suất của mô hình của chúng ta – Ma trận nhầm lẫn
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(ytest, y_pred)
print ("Confusion Matrix : \n", cm) Output:
Confusion Matrix :
[[65 3]
[ 8 24]]Trong số 100:
TruePostive + TrueNegative = 65 + 24
FalsePositive + FalseNegative = 3 + 8
Đo lường hiệu suất – Độ chính xác
from sklearn.metrics import accuracy_score
print ("Accuracy : ", accuracy_score(ytest, y_pred)) Output
Accuracy : 0.89Hình dung hiệu suất của mô hình của chúng ta.
from matplotlib.colors import ListedColormap
X_set, y_set = xtest, ytest
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(
np.array([X1.ravel(), X2.ravel()]).T).reshape(
X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show() Output:
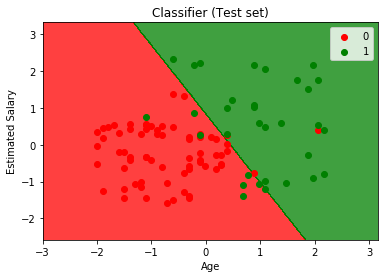
Phân tích các thước đo hiệu suất – độ chính xác và ma trận nhầm lẫn và biểu đồ, chúng ta có thể nói rõ ràng rằng mô hình của chúng ta đang hoạt động thực sự tốt.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}