
Điều kiện tiên quyết cần phải biết: Hiểu Logistic Regression và TensorFlow.
Nội dung chính
1. Tóm tắt ngắn gọn về hồi quy logistic:
Hồi quy logistic là thuật toán phân loại thường được sử dụng trong ML. Nó cho phép phân loại dữ liệu thành các lớp rời rạc bằng cách học mối quan hệ từ một tập hợp dữ liệu có nhãn nhất định. Nó học một mối quan hệ tuyến tính từ tập dữ liệu đã cho và sau đó đưa vào một mối quan hệ không tuyến tính ở dạng hàm Sigmoid.
Trong trường hợp hồi quy Logistic, giả thuyết là Sigmoid của một đường thẳng, tức là
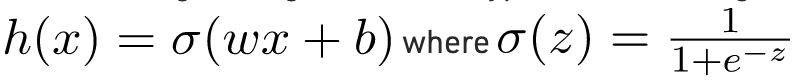
Trong đó vectơ w đại diện cho Trọng số và vô hướng b đại diện cho Độ lệch của mô hình.
Hãy để chúng ta hình dung về Hàm Sigmoid –
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
return 1 / (1 + np.exp( - z))
plt.plot(np.arange(-5, 5, 0.1), sigmoid(np.arange(-5, 5, 0.1)))
plt.title('Visualization of the Sigmoid Function')
plt.show() 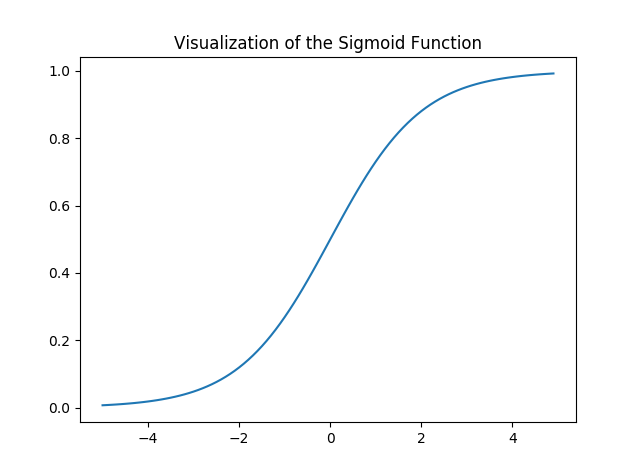
Lưu ý rằng phạm vi của hàm Sigmoid là (0, 1) có nghĩa là các giá trị kết quả nằm trong khoảng từ 0 đến 1. Thuộc tính này của hàm Sigmoid làm cho nó trở thành một lựa chọn thực sự tốt của Hàm kích hoạt cho Phân loại nhị phân. Cũng đối với z = 0, Sigmoid (z) = 0,5 là điểm giữa của phạm vi hàm Sigmoid.
Cũng giống như Hồi quy tuyến tính, chúng ta cần tìm các giá trị tối ưu của w và b để hàm chi phí J là nhỏ nhất. Trong trường hợp này, chúng ta sẽ sử dụng hàm chi phí Sigmoid Cross Entropy được cung cấp bởi
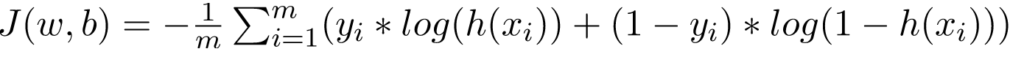
chi phí của Hàm này sau đó sẽ được tối ưu hóa bằng cách sử dụng Gradient Descent.
2. Thực hiện:
Chúng ta sẽ bắt đầu bằng cách nhập các thư viện cần thiết. Chúng ta sẽ sử dụng Numpy cùng với Tensorflow để tính toán, Pandas để phân tích dữ liệu cơ bản và Matplotlib để vẽ biểu đồ. Chúng tôi cũng sẽ sử dụng mô-đun tiền xử lý của Scikit-Learn for One Hot Encoding dữ liệu.
# importing modules
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.preprocessing import OneHotEncoder Tiếp theo, chúng ta sẽ nhập tập dữ liệu. Chúng tôi sẽ sử dụng một tập con của tập dữ liệu Iris nổi tiếng.
data = pd.read_csv('dataset.csv', header = None)
print("Data Shape:", data.shape)
print(data.head()) Kết quả:
Data Shape: (100, 4)
0 1 2 3
0 0 5.1 3.5 1
1 1 4.9 3.0 1
2 2 4.7 3.2 1
3 3 4.6 3.1 1
4 4 5.0 3.6 1Bây giờ, hãy lấy ma trận tính năng và các nhãn tương ứng và trực quan hóa.
# Feature Matrix
x_orig = data.iloc[:, 1:-1].values
# Data labels
y_orig = data.iloc[:, -1:].values
print("Shape of Feature Matrix:", x_orig.shape)
print("Shape Label Vector:", y_orig.shape) Hình dung dữ liệu đã cho
# Positive Data Points
x_pos = np.array([x_orig[i] for i in range(len(x_orig))
if y_orig[i] == 1])
# Negative Data Points
x_neg = np.array([x_orig[i] for i in range(len(x_orig))
if y_orig[i] == 0])
# Plotting the Positive Data Points
plt.scatter(x_pos[:, 0], x_pos[:, 1], color = 'blue', label = 'Positive')
# Plotting the Negative Data Points
plt.scatter(x_neg[:, 0], x_neg[:, 1], color = 'red', label = 'Negative')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Plot of given data')
plt.legend()
plt.show() 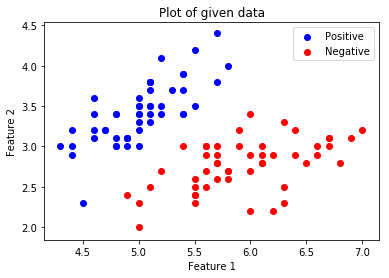
Bây giờ chúng ta sẽ là One Hot Encoding dữ liệu để nó hoạt động với thuật toán. Một mã hóa nóng chuyển đổi các tính năng phân loại sang định dạng hoạt động tốt hơn với các thuật toán phân loại và hồi quy. Chúng tôi cũng sẽ thiết lập Tỷ lệ học tập và số lượng Kỷ nguyên.
# Creating the One Hot Encoder
oneHot = OneHotEncoder()
# Encoding x_orig
oneHot.fit(x_orig)
x = oneHot.transform(x_orig).toarray()
# Encoding y_orig
oneHot.fit(y_orig)
y = oneHot.transform(y_orig).toarray()
alpha, epochs = 0.0035, 500
m, n = x.shape
print('m =', m)
print('n =', n)
print('Learning Rate =', alpha)
print('Number of Epochs =', epochs) Kết quả:
m = 100
n = 7
Learning Rate = 0.0035
Number of Epochs = 500Bây giờ chúng ta sẽ bắt đầu tạo mô hình bằng cách xác định các trình giữ chỗ X và Y, để chúng ta có thể cung cấp các ví dụ đào tạo x và y của mình vào trình tối ưu hóa trong quá trình đào tạo. Chúng ta cũng sẽ tạo các Biến W và b có thể huấn luyện được, những biến này có thể được tối ưu hóa bởi Gradient Descent Optimizer.
# There are n columns in the feature matrix
# after One Hot Encoding.
X = tf.placeholder(tf.float32, [None, n])
# Since this is a binary classification problem,
# Y can take only 2 values.
Y = tf.placeholder(tf.float32, [None, 2])
# Trainable Variable Weights
W = tf.Variable(tf.zeros([n, 2]))
# Trainable Variable Bias
b = tf.Variable(tf.zeros([2])) Bây giờ hãy khai báo hàm Hypothesis, Cost, Optimizer và Global Variables Initializer.
# Hypothesis
Y_hat = tf.nn.sigmoid(tf.add(tf.matmul(X, W), b))
# Sigmoid Cross Entropy Cost Function
cost = tf.nn.sigmoid_cross_entropy_with_logits(
logits = Y_hat, labels = Y)
# Gradient Descent Optimizer
optimizer = tf.train.GradientDescentOptimizer(
learning_rate = alpha).minimize(cost)
# Global Variables Initializer
init = tf.global_variables_initializer()Bắt đầu quá trình đào tạo bên trong Phiên Tensorflow.
//Python
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# Starting the Tensorflow Session
with tf.Session() as sess:
# Initializing the Variables
sess.run(init)
# Lists for storing the changing Cost and Accuracy in every Epoch
cost_history, accuracy_history = [], []
# Iterating through all the epochs
for epoch in range(epochs):
cost_per_epoch = 0
# Running the Optimizer
sess.run(optimizer, feed_dict = {X : x, Y : y})
# Calculating cost on current Epoch
c = sess.run(cost, feed_dict = {X : x, Y : y})
# Calculating accuracy on current Epoch
correct_prediction = tf.equal(tf.argmax(Y_hat, 1),
tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,
tf.float32))
# Storing Cost and Accuracy to the history
cost_history.append(sum(sum(c)))
accuracy_history.append(accuracy.eval({X : x, Y : y}) * 100)
# Displaying result on current Epoch
if epoch % 100 == 0 and epoch != 0:
print("Epoch " + str(epoch) + " Cost: "
+ str(cost_history[-1]))
Weight = sess.run(W) # Optimized Weight
Bias = sess.run(b) # Optimized Bias
# Final Accuracy
correct_prediction = tf.equal(tf.argmax(Y_hat, 1),
tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,
tf.float32))
print("\nAccuracy:", accuracy_history[-1], "%")Output
Epoch 100 Cost: 125.700202942
Epoch 200 Cost: 120.647117615
Epoch 300 Cost: 118.151592255
Epoch 400 Cost: 116.549999237
Accuracy: 91.0000026226 %Hãy vẽ biểu đồ sự thay đổi của chi phí qua các kỷ nguyên
plt.plot(list(range(epochs)), cost_history)
plt.xlabel('Epochs')
plt.ylabel('Cost')
plt.title('Decrease in Cost with Epochs')
plt.show() 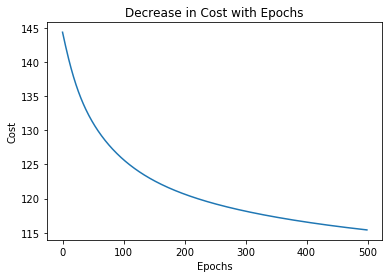
Vẽ biểu đồ sự thay đổi độ chính xác qua các kỷ nguyên.
plt.plot(list(range(epochs)), accuracy_history)
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.title('Increase in Accuracy with Epochs')
plt.show() 
Bây giờ chúng ta sẽ vẽ Ranh giới Quyết định cho trình phân loại được đào tạo của chúng ta. Ranh giới quyết định là một siêu bề mặt phân chia không gian vectơ cơ bản thành hai tập, một cho mỗi lớp.
# Calculating the Decision Boundary
decision_boundary_x = np.array([np.min(x_orig[:, 0]),
np.max(x_orig[:, 0])])
decision_boundary_y = (- 1.0 / Weight[0]) *
(decision_boundary_x * Weight + Bias)
decision_boundary_y = [sum(decision_boundary_y[:, 0]),
sum(decision_boundary_y[:, 1])]
# Positive Data Points
x_pos = np.array([x_orig[i] for i in range(len(x_orig))
if y_orig[i] == 1])
# Negative Data Points
x_neg = np.array([x_orig[i] for i in range(len(x_orig))
if y_orig[i] == 0])
# Plotting the Positive Data Points
plt.scatter(x_pos[:, 0], x_pos[:, 1],
color = 'blue', label = 'Positive')
# Plotting the Negative Data Points
plt.scatter(x_neg[:, 0], x_neg[:, 1],
color = 'red', label = 'Negative')
# Plotting the Decision Boundary
plt.plot(decision_boundary_x, decision_boundary_y)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Plot of Decision Boundary')
plt.legend()
plt.show() 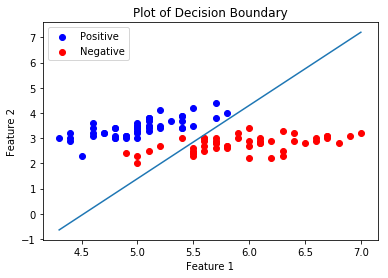
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}