
Bài viết này cafedev thảo luận về những điều cơ bản của Softmax Regression và cách triển khai nó trong Python bằng cách sử dụng thư viện TensorFlow.
Nội dung chính
1. Hồi quy Softmax là gì?
Hồi quy Softmax (hay hồi quy logistic đa thức) là tổng quát của hồi quy logistic trong trường hợp chúng ta muốn xử lý nhiều lớp.
Hiểu hồi quy logistic
Trong hồi quy logistic nhị phân, chúng ta giả định rằng các nhãn là nhị phân, tức i^th là để quan sát,
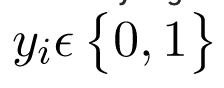
Nhưng hãy xem xét một tình huống mà chúng ta cần phân loại một quan sát từ hai hoặc nhiều nhãn lớp. Ví dụ, phân loại chữ số. Ở đây, các nhãn có thể có là:
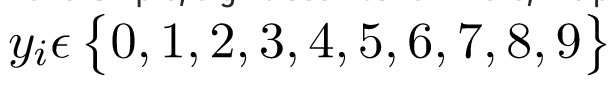
Trong những trường hợp như vậy, chúng ta có thể sử dụng Softmax Regression.
Đầu tiên chúng ta hãy xác định mô hình của mình:
- Để tập dữ liệu có các tính năng ‘m’ và ‘n’ các quan sát. Ngoài ra, có các nhãn lớp ‘k’, tức là mọi quan sát có thể được phân loại là một trong các giá trị mục tiêu có thể có của ‘k’. Ví dụ: nếu chúng ta có một tập dữ liệu gồm 100 hình ảnh chữ số viết tay có kích thước vectơ 28 × 28 để phân loại chữ số, chúng ta có, n = 100, m = 28 × 28 = 784 và k = 10.
- Ma trận đặc điểm
Ma trận đối tượng X, được biểu thị như sau:

Ở đây, Xij biểu thị các giá trị j^th của đối tượng để quan sát i^th. Ma trận có các kích thước: nX(m+1)
- Ma trận trọng lượng
Chúng ta xác định một ma trận trọng số W như sau:

Ở đây, Wij đại diện cho trọng số được gán cho i^th đặc điểm cho nhãn lớp j^th. Ma trận có các kích thước: (m+1)Xk . Ban đầu, ma trận trọng lượng được lấp đầy bằng cách sử dụng một số phân phối chuẩn.
- Ma trận điểm đăng nhập
Sau đó, chúng ta xác định ma trận đầu vào của chúng ta (còn gọi là ma trận điểm logit) Z, như sau: X = ZW
Ma trận có các kích thước: nXk
Hiện tại, chúng ta đang lấy thêm một cột trong ma trận tính năng X và một hàng phụ trong ma trận trọng số W,. Các cột và hàng bổ sung này tương ứng với các điều khoản thiên vị được liên kết với mỗi dự đoán. Điều này có thể được đơn giản hóa bằng cách xác định một ma trận bổ sung cho độ lệch b của kích thước nXk ở bij = w0j. (Trong thực tế, tất cả những gì chúng ta cần là một vectơ có kích thước k và một số kỹ thuật phát sóng cho các điều khoản thiên vị!)
Vì vậy, ma trận điểm cuối cùng, Z là: Z = XW + b
trong đó ma trận X có kích thước nXm trong khi W có kích thước mXk. Nhưng ma trận Z vẫn có cùng giá trị và kích thước!
Nhưng ma trận Z biểu thị điều gì? Thực ra Zij là khả năng xảy ra nhãn j để i^th quan sát. Nó không phải là một giá trị xác suất thích hợp nhưng có thể được coi là điểm cho mỗi nhãn lớp cho mỗi lần quan sát!
Chúng ta xác định vectơ Zi như điểm logit để quan sát i^th.
Ví dụ, để véc tơ:
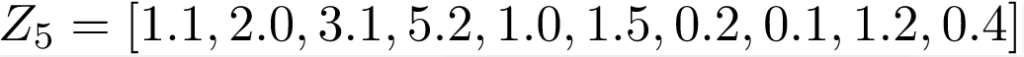
đại diện cho điểm của mỗi lớp nhãn 0,2,3,4,5,6,7,8,9 trong bài toán phân loại chữ số viết tay để quan sát 5^th.
Ở đây, điểm tối đa là 5,2 tương ứng với nhãn lớp ‘3’. Do đó, mô hình của chúng tôi hiện dự đoán quan sát 5^th / hình ảnh là “3”.
- Lớp Softmax
Khó đào tạo mô hình bằng cách sử dụng các giá trị điểm vì khó có thể phân biệt chúng trong khi triển khai thuật toán Gradient Descent để giảm thiểu hàm chi phí. Vì vậy, chúng ta cần một số hàm để chuẩn hóa điểm logit cũng như giúp chúng dễ dàng phân biệt! Để chuyển ma trận điểm Z thành xác suất, chúng ta sử dụng hàm Softmax.
Đối với một vectơ y, hàm softmax S(y) được định nghĩa là:
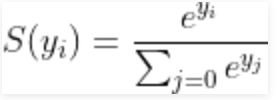
Vì vậy, hàm softmax sẽ thực hiện 2 việc:
1. chuyển đổi tất cả các điểm số thành xác suất.
2. tổng của tất cả các xác suất là 1.
Nhớ lại rằng trong phân loại Binary Logistic, chúng ta đã sử dụng hàm sigmoid cho cùng một nhiệm vụ. Hàm Softmax không là gì ngoài một tổng quát của hàm sigmoid! Bây giờ, hàm softmax này tính toán i^th xác suất để mẫu đào tạo thuộc về lớp J cho trước vectơ logits Zi là:

Ở dạng vectơ, chúng ta có thể viết đơn giản:
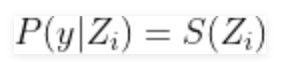
Để đơn giản, hãy biểu thị Si vectơ xác suất softmax để i^th quan sát.
- Ma trận mục tiêu được mã hóa one hot
Vì hàm softmax cung cấp cho chúng ta vectơ xác suất của mỗi nhãn lớp cho một quan sát nhất định, chúng ta cần chuyển đổi vectơ mục tiêu theo cùng một định dạng để tính chi phí của hàm! Tương ứng với mỗi quan sát, có một vectơ đích (thay vì giá trị đích!) Chỉ bao gồm các số không và các vectơ chỉ đặt nhãn đúng là 1. Kỹ thuật này được gọi là mã hóa nóng(one hot). Hãy xem sơ đồ dưới đây để biết rõ hơn. hiểu biết:
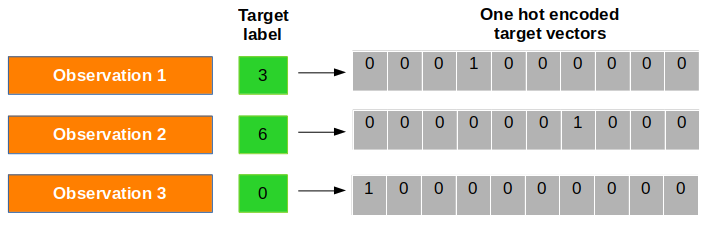
Bây giờ, chúng ta biểu thị vectơ mã hóa nóng(one hot) i^th để quan sát là Ti
- Chức năng ước lượng
Bây giờ, chúng ta cần xác định một chi phí của hàm, chúng ta phải so sánh các xác suất softmax và vectơ mục tiêu được mã hóa một nóng để có sự giống nhau. Chúng ta sử dụng khái niệm Cross-Entropy cho tương tự. Cross-entropy là một hàm tính toán khoảng cách lấy các xác suất được tính toán từ hàm softmax và ma trận mã hóa một nóng được tạo để tính khoảng cách. Đối với các lớp mục tiêu phù hợp, giá trị khoảng cách sẽ nhỏ hơn và giá trị khoảng cách sẽ lớn hơn đối với các lớp mục tiêu sai. Chúng ta xác định entropy chéo D(Si,Ti), để quan sát j^th với vectơ xác suất softmax Si và vectơ mục tiêu one hot Ti, như:
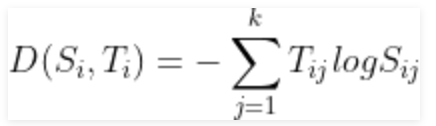
Và bây giờ, chi phí của hàm, J có thể được định nghĩa là entropy chéo trung bình, tức là:
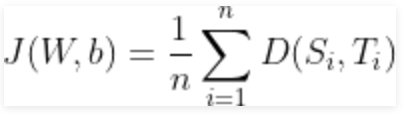
và nhiệm vụ là giảm thiểu chi phí của hàm này!
- Thuật toán Gradient Descent
Để tìm hiểu mô hình softmax của chúng ta thông qua gradient descent, chúng ta cần tính đạo hàm:
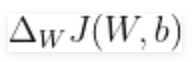
và
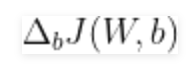
sau đó chúng ta sử dụng để cập nhật trọng số và độ lệch theo hướng ngược lại của gradient:
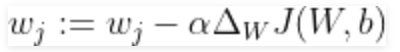
và
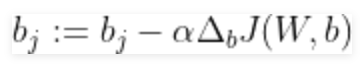
cho mỗi lớp j có j thuộc 1,2,3..k và anpla đang học tốc độ. Sử dụng chi phí gradient này, chúng ta cập nhật lặp đi lặp lại ma trận trọng số cho đến khi chúng ta đạt đến một số kỷ nguyên cụ thể (vượt qua tập huấn luyện) hoặc đạt đến ngưỡng chi phí mong muốn.
2. Triển khai
Bây giờ chúng ta hãy triển khai Softmax Regression trên bộ dữ liệu chữ số viết tay MNIST bằng cách sử dụng thư viện TensorFlow.
Để được giới thiệu về TensorFlow, hãy làm theo hướng dẫn sau:
Bạn có thể tìm hiểu về TensorFlow tại đây.
Bước 1: Nhập phần phụ thuộc
Trước hết, chúng ta nhập các phụ thuộc.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt Bước 2: Tải xuống dữ liệu
TensorFlow cho phép bạn tải xuống và đọc dữ liệu MNIST tự động. Hãy xem xét đoạn mã dưới đây. Nó sẽ tải xuống và lưu dữ liệu vào thư mục, MNIST_data, trong thư mục dự án hiện tại của bạn và tải nó trong chương trình hiện tại.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gzBước 3: Tìm hiểu dữ liệu
Bây giờ, chúng ta cố gắng hiểu cấu trúc của tập dữ liệu.
Dữ liệu MNIST được chia thành ba phần: 55.000 điểm dữ liệu đào tạo (mnist.train), 10.000 điểm dữ liệu kiểm tra (mnist.test) và 5.000 điểm dữ liệu xác thực (mnist.validation).
Mỗi hình ảnh có kích thước 28 pixel x 28 pixel đã được làm phẳng thành mảng 1-D có kích thước 784. Số nhãn lớp là 10. Mỗi nhãn đích đã được cung cấp ở dạng mã hóa nóng.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
print("Shape of feature matrix:", mnist.train.images.shape)
print("Shape of target matrix:", mnist.train.labels.shape)
print("One-hot encoding for 1st observation:\n", mnist.train.labels[0])
# visualize data by plotting images
fig,ax = plt.subplots(10,10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(mnist.train.images[k].reshape(28,28), aspect='auto')
k += 1
plt.show() Kết quả
Shape of feature matrix: (55000, 784)
Shape of target matrix: (55000, 10)
One-hot encoding for 1st observation:
[ 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
Bước 4: Xác định đồ thị tính toán
Bây giờ, chúng ta tạo một đồ thị tính toán.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# number of features
num_features = 784
# number of target labels
num_labels = 10
# learning rate (alpha)
learning_rate = 0.05
# batch size
batch_size = 128
# number of epochs
num_steps = 5001
# input data
train_dataset = mnist.train.images
train_labels = mnist.train.labels
test_dataset = mnist.test.images
test_labels = mnist.test.labels
valid_dataset = mnist.validation.images
valid_labels = mnist.validation.labels
# initialize a tensorflow graph
graph = tf.Graph()
with graph.as_default():
"""
defining all the nodes
"""
# Inputs
tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, num_features))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
weights = tf.Variable(tf.truncated_normal([num_features, num_labels]))
biases = tf.Variable(tf.zeros([num_labels]))
# Training computation.
logits = tf.matmul(tf_train_dataset, weights) + biases
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
labels=tf_train_labels, logits=logits))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
valid_prediction = tf.nn.softmax(tf.matmul(tf_valid_dataset, weights) + biases)
test_prediction = tf.nn.softmax(tf.matmul(tf_test_dataset, weights) + biases) Một số điểm quan trọng cần lưu ý:
Đối với dữ liệu đào tạo, chúng ta sử dụng trình giữ chỗ sẽ được cung cấp tại thời điểm chạy với một minibatch đào tạo. Kỹ thuật sử dụng các minibatch cho mô hình đào tạo sử dụng gradient descent được gọi là Stochastic Gradient Descent
Trong dốc xuống (GD) và giảm độ dốc ngẫu nhiên (SGD), bạn cập nhật một bộ tham số theo cách lặp đi lặp lại để giảm thiểu hàm lỗi. Trong khi ở trong GD, bạn phải chạy qua TẤT CẢ các mẫu trong tập huấn luyện của mình để thực hiện một lần cập nhật cho một tham số trong một lần lặp cụ thể, trong SGD, mặt khác, bạn chỉ sử dụng MỘT hoặc BỔ SUNG mẫu huấn luyện từ tập huấn luyện của mình để thực hiện cập nhật cho một tham số trong một lần lặp cụ thể. Nếu bạn sử dụng SUBSET, nó được gọi là Minibatch Stochastic gradient Descent. Do đó, nếu số lượng mẫu huấn luyện lớn, trên thực tế là rất lớn, thì việc sử dụng gradient descent có thể mất quá nhiều thời gian vì trong mỗi lần lặp khi bạn cập nhật giá trị của các tham số, bạn đang chạy qua toàn bộ tập huấn luyện. Mặt khác, sử dụng SGD sẽ nhanh hơn vì bạn chỉ sử dụng một mẫu đào tạo và nó bắt đầu tự cải thiện ngay từ mẫu đầu tiên. SGD thường hội tụ nhanh hơn nhiều so với GD nhưng chức năng lỗi không được giảm thiểu tốt như trong trường hợp của GD. Thông thường, trong hầu hết các trường hợp, giá trị gần đúng mà bạn nhận được trong SGD cho các giá trị tham số là đủ vì chúng đạt đến giá trị tối ưu và tiếp tục dao động ở đó.
- Ma trận trọng số được khởi tạo bằng cách sử dụng các giá trị ngẫu nhiên theo phân phối chuẩn (cắt ngắn). Điều này đạt được bằng cách sử dụng phương pháp tf.truncated_normal. Các thành kiến được khởi tạo bằng 0 bằng phương thức tf.zeros.
- Bây giờ, chúng ta nhân các đầu vào với ma trận trọng số và thêm các thành phần. Chúng ta tính toán softmax và cross-entropy bằng tf.nn.softmax_cross_entropy_with_logits (đây là một hoạt động trong TensorFlow, vì nó rất phổ biến và có thể được tối ưu hóa). Chúng ta lấy giá trị trung bình của entropy chéo này trên tất cả các ví dụ đào tạo bằng phương pháp tf.reduce_mean.
- Chúng ta sẽ giảm thiểu sự mất mát bằng cách sử dụng gradient descent. Đối với điều này, chúng ta sử dụng tf.train.GradientDescentOptimizer.
- train_prediction, valid_prediction và test_prediction không phải là một phần của đào tạo, mà chỉ ở đây để chúng ta có thể báo cáo số liệu chính xác khi chúng ta đào tạo.
Bước 5: Chạy đồ thị tính toán
Vì chúng ta đã xây dựng biểu đồ tính toán, nên bây giờ đã đến lúc chạy nó trong một phiên.
# utility function to calculate accuracy
def accuracy(predictions, labels):
correctly_predicted = np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1))
accu = (100.0 * correctly_predicted) / predictions.shape[0]
return accu
with tf.Session(graph=graph) as session:
# initialize weights and biases
tf.global_variables_initializer().run()
print("Initialized")
for step in range(num_steps):
# pick a randomized offset
offset = np.random.randint(0, train_labels.shape[0] - batch_size - 1)
# Generate a minibatch.
batch_data = train_dataset[offset:(offset + batch_size), :]
batch_labels = train_labels[offset:(offset + batch_size), :]
# Prepare the feed dict
feed_dict = {tf_train_dataset : batch_data,
tf_train_labels : batch_labels}
# run one step of computation
_, l, predictions = session.run([optimizer, loss, train_prediction],
feed_dict=feed_dict)
if (step % 500 == 0):
print("Minibatch loss at step {0}: {1}".format(step, l))
print("Minibatch accuracy: {:.1f}%".format(
accuracy(predictions, batch_labels)))
print("Validation accuracy: {:.1f}%".format(
accuracy(valid_prediction.eval(), valid_labels)))
print("\nTest accuracy: {:.1f}%".format(
accuracy(test_prediction.eval(), test_labels))) Kết quả
Initialized
Minibatch loss at step 0: 11.68728256225586
Minibatch accuracy: 10.2%
Validation accuracy: 14.3%
Minibatch loss at step 500: 2.239773750305176
Minibatch accuracy: 46.9%
Validation accuracy: 67.6%
Minibatch loss at step 1000: 1.0917563438415527
Minibatch accuracy: 78.1%
Validation accuracy: 75.0%
Minibatch loss at step 1500: 0.6598564386367798
Minibatch accuracy: 78.9%
Validation accuracy: 78.6%
Minibatch loss at step 2000: 0.24766433238983154
Minibatch accuracy: 91.4%
Validation accuracy: 81.0%
Minibatch loss at step 2500: 0.6181786060333252
Minibatch accuracy: 84.4%
Validation accuracy: 82.5%
Minibatch loss at step 3000: 0.9605385065078735
Minibatch accuracy: 85.2%
Validation accuracy: 83.9%
Minibatch loss at step 3500: 0.6315320730209351
Minibatch accuracy: 85.2%
Validation accuracy: 84.4%
Minibatch loss at step 4000: 0.812285840511322
Minibatch accuracy: 82.8%
Validation accuracy: 85.0%
Minibatch loss at step 4500: 0.5949224233627319
Minibatch accuracy: 80.5%
Validation accuracy: 85.6%
Minibatch loss at step 5000: 0.47554320096969604
Minibatch accuracy: 89.1%
Validation accuracy: 86.2%
Test accuracy: 86.5%Một số điểm quan trọng cần lưu ý:
Trong mỗi lần lặp, một minibatch được chọn bằng cách chọn một giá trị bù ngẫu nhiên bằng phương pháp np.random.randint.
Để cấp dữ liệu cho các trình giữ chỗ tf_train_dataset và tf_train_label, chúng ta tạo một feed_dict như sau:
feed_dict = {tf_train_dataset: batch_data, tf_train_labels: batch_labels}Một cách tắt để thực hiện một bước tính toán là:
_, l, predictions = session.run([optimizer, loss, train_prediction], feed_dict=feed_dict)Nút này trả về các giá trị mới của tổn thất và dự đoán sau khi thực hiện bước tối ưu hóa.
Điều này đưa chúng ta đến phần cuối của việc thực hiện. Toàn bộ mã có thể được tìm thấy ở đây.
Cuối cùng, đây là một số điểm cần suy ngẫm:
Bạn có thể thử tinh chỉnh với các thông số như tốc độ học, kích thước lô, số kỷ nguyên, v.v. và đạt được kết quả tốt hơn. Bạn cũng có thể thử một trình tối ưu hóa khác như tf.train.AdamOptimizer.
Độ chính xác của mô hình trên có thể được cải thiện bằng cách sử dụng mạng nơ-ron với một hoặc nhiều lớp ẩn. Chúng ta sẽ thảo luận về việc triển khai nó bằng cách sử dụng TensorFlow trong một số bài viết sắp tới.
13. Softmax Regression so với k Binary Classifier
Người ta nên biết các trường hợp mà hồi quy softmax hoạt động và nơi nào không. Trong nhiều trường hợp, bạn có thể cần sử dụng k bộ phân loại logistic nhị phân khác nhau cho mỗi k giá trị có thể có của nhãn lớp.
Giả sử bạn đang giải quyết một vấn đề về thị giác máy tính trong đó bạn đang cố gắng phân loại hình ảnh thành ba lớp khác nhau:
Trường hợp 1: Giả sử rằng các lớp của bạn là trong nhà_scene, ngoài trời_urban_scene và ngoài trời_wilderness_scene.
Trường hợp 2: Giả sử các lớp của bạn là trong nhà_scene, black_and_white_image và image_has_people.
Trong trường hợp nào bạn sẽ sử dụng bộ phân loại Hồi quy Softmax và trong trường hợp nào thì bạn sẽ sử dụng 3 bộ phân loại hồi quy Binary Logistic?
Điều này sẽ phụ thuộc vào việc 3 lớp có loại trừ lẫn nhau hay không.
Trong trường hợp 1, một cảnh có thể là trong nhà_scene, ngoài trời_urban_scene hoặc ngoài trời_wilderness_scene. Vì vậy, giả sử rằng mỗi ví dụ huấn luyện được gắn nhãn chính xác một trong 3 lớp, chúng ta nên xây dựng một bộ phân loại softmax với k = 3.
Tuy nhiên, trong trường hợp 2, các lớp không loại trừ lẫn nhau vì một cảnh có thể là cả trong nhà và có người trong đó. Vì vậy, trong trường hợp này, sẽ thích hợp hơn nếu xây dựng 3 bộ phân loại hồi quy logistic nhị phân. Bằng cách này, đối với mỗi cảnh mới, thuật toán của bạn có thể quyết định riêng xem cảnh đó có thuộc từng loại trong 3 loại hay không.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}