
Bài này Cafedev sẽ tìm hiểu về việc khai thác dữ liệu, phân loại chúng như thế nào trong ML.
Khai thác dữ liệu(Data Mining): Khai thác dữ liệu nói chung có nghĩa là khai thác hoặc đào sâu vào dữ liệu ở các dạng khác nhau để có được các mẫu và để có được kiến thức về mẫu đó. Trong quá trình khai thác dữ liệu, các tập dữ liệu lớn trước tiên được sắp xếp, sau đó các mẫu được xác định và các mối quan hệ được thiết lập để thực hiện phân tích dữ liệu và giải quyết vấn đề.
Phân loại(Classification): Đây là một nhiệm vụ Phân tích dữ liệu, tức là quá trình tìm kiếm một mô hình mô tả và phân biệt các lớp và khái niệm dữ liệu. Phân loại là vấn đề xác định một tập hợp các danh mục (quần thể con), một dữ liệu quan sát mới thuộc về loại nào, trên cơ sở một tập dữ liệu huấn luyện chứa các quan sát và các loại thành viên đã biết.
Ví dụ: Trước khi bắt đầu bất kỳ Dự án nào, chúng ta cần kiểm tra tính khả thi của dự án đó. Trong trường hợp này, cần có bộ phân loại để dự đoán các nhãn lớp như ‘An toàn’ và ‘Rủi ro’ để áp dụng Dự án và phê duyệt thêm. Đây là một quá trình gồm hai bước như:
- Bước học tập (Giai đoạn đào tạo): Xây dựng mô hình phân loại
Các thuật toán khác nhau được sử dụng để xây dựng một bộ phân loại bằng cách làm cho mô hình học bằng cách sử dụng tập huấn luyện có sẵn. Mô hình phải được đào tạo để dự đoán kết quả chính xác.
- Bước phân loại: Mô hình được sử dụng để dự đoán nhãn lớp và thử nghiệm mô hình đã xây dựng trên dữ liệu thử nghiệm và do đó ước tính độ chính xác của các quy tắc phân loại.
Nội dung chính
1. Đào tạo và Kiểm tra
Giả sử có một người đang ngồi dưới quạt và quạt bắt đầu rơi vào người anh ta, anh ta nên tránh sang một bên để không bị thương. Vì vậy, đây là phần huấn luyện của anh ấy để chuyển đi. Trong khi Thử nghiệm nếu người đó nhìn thấy bất kỳ vật nặng nào tiến về phía mình hoặc rơi vào người và di chuyển sang một bên thì hệ thống được thử nghiệm dương tính và nếu người đó không di chuyển sang một bên thì hệ thống được thử nghiệm âm tính.
Tương tự như vậy với dữ liệu, nó cần được đào tạo để có được kết quả chính xác và tốt nhất.
Có một số kiểu dữ liệu nhất định liên quan đến khai thác dữ liệu thực sự cho chúng ta biết định dạng của tệp (cho dù nó ở định dạng văn bản hay định dạng số).
Thuộc tính – Đại diện cho các tính năng khác nhau của một đối tượng. Các loại thuộc tính khác nhau là:
- Nhị phân: Chỉ sở hữu hai giá trị, tức là Đúng hoặc Sai
Ví dụ: Giả sử có một cuộc khảo sát đánh giá sản phẩm nào đó. Chúng tôi cần kiểm tra xem nó có hữu ích hay không. Vì vậy, Khách hàng phải trả lời là Có hoặc Không.
Tính hữu ích của sản phẩm: Có / Không
- Tính đối xứng: Cả hai giá trị đều quan trọng như nhau về mọi mặt
- Không đối xứng: Khi cả hai giá trị có thể không quan trọng.
2. Danh nghĩa: Khi có thể có nhiều hơn hai kết quả. Nó ở dạng Bảng chữ cái chứ không phải ở dạng Số nguyên.
Ví dụ: Một người cần chọn một số vật liệu nhưng có màu sắc khác nhau. Vì vậy, màu có thể là Vàng, Xanh lá, Đen, Đỏ.
Màu sắc khác nhau: Đỏ, Xanh lá cây, Đen, Vàng
Thứ tự: Các giá trị phải có một số thứ tự có ý nghĩa.
Ví dụ: Giả sử có bảng điểm của một vài học sinh có thể chứa các điểm khác nhau theo thành tích của họ, chẳng hạn như A, B, C, D
Hạng: A, B, C, D
Liên tục: Có thể có vô số giá trị, nó ở kiểu float
Ví dụ: Đo trọng lượng của một vài Học sinh theo một trình tự hoặc theo thứ tự, tức là 50, 51, 52, 53
Cân nặng: 50, 51, 52, 53
Rời rạc: Số lượng giá trị hữu hạn.
Ví dụ: Điểm của một học sinh trong một số môn học: 65, 70, 75, 80, 90
Mác: 65, 70, 75, 80, 90
2. Cú pháp:
- Ký hiệu toán học: Phân loại dựa trên việc xây dựng một hàm lấy vectơ đặc trưng đầu vào “X” và dự đoán kết quả của nó là “Y” (Phản hồi định tính lấy các giá trị trong tập C)
- Ở đây Bộ phân loại (hoặc mô hình) được sử dụng, là một chức năng được Giám sát, có thể được thiết kế theo cách thủ công dựa trên kiến thức của chuyên gia. Nó đã được xây dựng để dự đoán các nhãn của lớp (Ví dụ: Nhãn – “Có” hoặc “Không” để chấp thuận một số sự kiện).
Bộ phân loại có thể được phân loại thành hai loại chính:
- Phân biệt: Nó là một bộ phân loại rất cơ bản và chỉ xác định một lớp cho mỗi hàng dữ liệu. Nó cố gắng mô hình hóa chỉ bằng cách phụ thuộc vào dữ liệu được quan sát, phụ thuộc nhiều vào chất lượng của dữ liệu hơn là vào các phân phối.
Ví dụ: Hồi quy logistic
Sự chấp nhận của một sinh viên tại một trường Đại học (Bài kiểm tra và điểm số cần được xem xét)
Giả sử có ít học sinh và kết quả của chúng như sau:
Student 1 : Test Score: 9/10, Grades: 8/10 Result: Accepted
Student 2 : Test Score: 3/10, Grades: 4/10, Result: Rejected
Student 3 : Test Score: 7/10, Grades: 6/10, Result: to be tested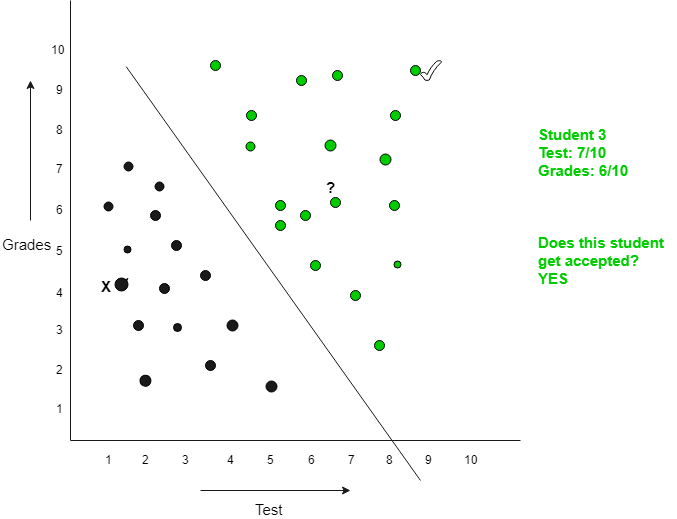
2. Sinh sản: Nó mô hình hóa sự phân bố của các lớp riêng lẻ và cố gắng tìm hiểu mô hình tạo ra dữ liệu đằng sau hậu trường bằng cách ước tính các giả định và phân phối của mô hình. Được sử dụng để dự đoán dữ liệu không nhìn thấy.
Ví dụ: Bộ phân loại Naive Bayes
Phát hiện email Spam bằng cách xem dữ liệu trước đó. Giả sử 100 email và con số đó được chia theo tỷ lệ 1: 4, tức là Loại A: 25% (Email rác) và Loại B: 75% (Email không Spam). Bây giờ nếu người dùng muốn kiểm tra xem email có chứa từ rẻ hay không thì email đó có thể được gọi là Spam.
Có vẻ như ở Lớp A (tức là trong 25% dữ liệu), 20 trong số 25 email là thư rác và phần còn lại thì không.
Và trong loại B (tức là trong 75% dữ liệu), 70 trong số 75 email không phải là thư rác và phần còn lại là thư rác.
Vì vậy, nếu email có chứa từ rẻ, khả năng nó là thư rác là bao nhiêu ?? (= 80%)
Các bộ phân loại trong ML:
- Cây quyết định
- Máy phân loại Bayes
- Mạng thần kinh
- K-Hàng xóm gần nhất
- Hỗ trợ Bộ Máy Vector
- Hồi quy tuyến tính
- Hồi quy logistic <
- Công cụ và ngôn ngữ liên kết: Được sử dụng để khai thác / trích xuất thông tin hữu ích từ dữ liệu thô.
Các ngôn ngữ chính được sử dụng: R, SAS, Python, SQL
Các công cụ chính được sử dụng: RapidMiner, Orange, KNIME, Spark, Weka
Các thư viện được sử dụng: Jupyter, NumPy, Matplotlib, Pandas, ScikitLearn, NLTK, TensorFlow, Seaborn, Basemap, v.v.
3. Ví dụ trong cuộc sống thực:
- Phân tích giỏ thị trường:
Nó là một kỹ thuật mô hình hóa đã được kết hợp với các giao dịch mua một số mặt hàng kết hợp thường xuyên.
Ví dụ: Amazon và nhiều Nhà bán lẻ khác sử dụng kỹ thuật này. Trong khi xem một số sản phẩm, một số gợi ý nhất định về hàng hóa cho thấy rằng một số người đã mua trong quá khứ.
- Dự báo thời tiết:
Các mẫu thay đổi trong điều kiện thời tiết cần được quan sát dựa trên các thông số như nhiệt độ, độ ẩm, hướng gió. Sự quan sát nhạy bén này cũng yêu cầu sử dụng các bản ghi trước đó để dự đoán chính xác.
4. Ưu điểm:
- Phương pháp khai thác dựa trên chi phí hiệu quả và hiệu quả
- Giúp xác định nghi phạm tội phạm
- Giúp dự đoán nguy cơ mắc bệnh
- Giúp các Ngân hàng và Tổ chức Tài chính xác định những người không trả được nợ để họ có thể phê duyệt Thẻ, Khoản vay, v.v.
5. Nhược điểm:
- Quyền riêng tư: Khi dữ liệu là cơ hội mà một công ty có thể cung cấp một số thông tin về khách hàng của họ cho các nhà cung cấp khác hoặc sử dụng thông tin này vì lợi nhuận của họ.
- Vấn đề về độ chính xác: Việc lựa chọn mô hình chính xác phải có để có được độ chính xác và kết quả tốt nhất.
6. CÁC ỨNG DỤNG:
- Tiếp thị và Bán lẻ
- Chế tạo
- Công nghiệp viễn thông
- Phát hiện xâm nhập
- Hệ thống giáo dục
- Phát hiện gian lận
- GIST KHAI THÁC DỮ LIỆU:
Chọn phương pháp phân loại chính xác, như cây quyết định, mạng Bayes hoặc mạng nơ-ron.
Cần một mẫu dữ liệu, nơi tất cả các giá trị của lớp đều được biết. Sau đó, dữ liệu sẽ được chia thành hai phần, một tập huấn luyện và một tập kiểm tra.
Bây giờ, tập huấn luyện được trao cho một thuật toán học tập, thuật toán này dẫn xuất một bộ phân loại. Sau đó, bộ phân loại được kiểm tra với bộ kiểm tra, nơi tất cả các giá trị của lớp được ẩn.
Nếu bộ phân loại phân loại hầu hết các trường hợp trong tập kiểm tra một cách chính xác, thì có thể giả định rằng nó hoạt động chính xác cũng trên dữ liệu trong tương lai, nếu không nó có thể là một mô hình được chọn sai.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}