
Nội dung chính
1. Giới thiệu
Như tên cho thấy, Phân loại là nhiệm vụ “phân loại mọi thứ” thành các danh mục con. Nếu điều đó nghe có vẻ không mơ hồ, hãy tưởng tượng máy tính của bạn có thể phân biệt giữa bạn và người lạ. Giữa một củ khoai tây và một quả cà chua. Giữa điểm A và điểm F-.
Vâng. Bây giờ nghe có vẻ thú vị!
Trong ML và Thống kê, Phân loại là vấn đề xác định tập hợp các danh mục (quần thể con), một dữ liệu để quan sát mới thuộc về cái gì, trên cơ sở một tập dữ liệu huấn luyện chứa các dữ liệu quan sát và các thành viên của danh mục được biết đến.
2. Các kiểu phân loại
Phân loại có hai kiểu:
- Phân loại nhị phân(Binary Classification): Khi chúng ta phải phân loại dữ liệu đã cho thành 2 lớp riêng biệt. Ví dụ – Căn cứ vào tình trạng sức khoẻ của một người, ta phải xác định người đó có mắc một bệnh nào đó hay không.
- Phân loại nhiều kiểu(Multiclass Classification): Số lớp nhiều hơn 2. Ví dụ – Trên cơ sở dữ liệu về các loài hoa khác nhau, chúng ta phải xác định loài nào mà chúng ta quan sát được.
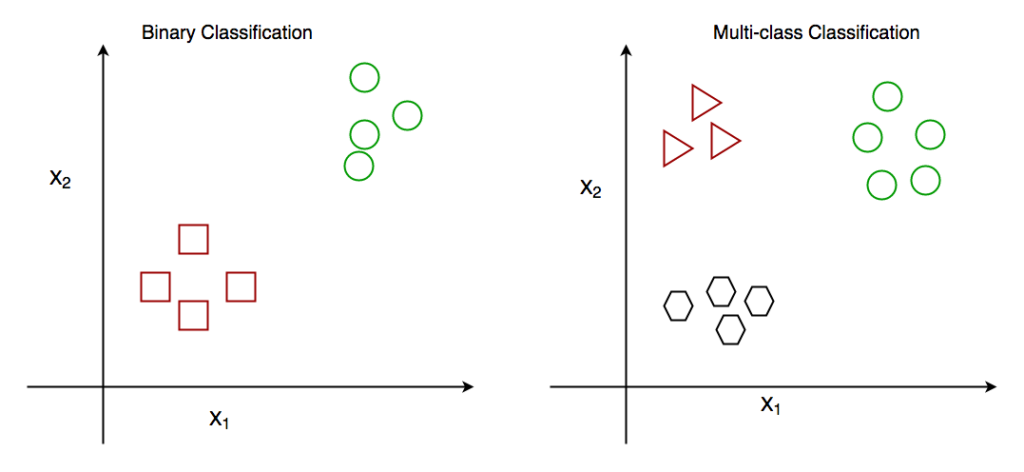
Hình: Phân loại Binary và Multiclass. Ở đây x1 và x2 là các biến của chúng ta mà lớp được dự đoán.
3. Phân loại hoạt động như thế nào?
Giả sử chúng ta phải dự đoán xem một bệnh nhân nhất định có mắc một bệnh nào đó hay không, trên cơ sở 3 biến, được gọi là các đặc trưng.
Có nghĩa là có hai kết quả có thể xảy ra:
Bệnh nhân mắc bệnh nói trên. Về cơ bản, kết quả có nhãn “Có” hoặc “Đúng”.
Bệnh nhân khỏi bệnh. Kết quả có nhãn “Không” hoặc “Sai”.
Đây là một vấn đề phân loại nhị phân.
Chúng ta có một tập hợp các dữ liệu đã được quan sát được gọi là tập dữ liệu huấn luyện, bao gồm dữ liệu mẫu với kết quả phân loại thực tế. Chúng ta đào tạo một mô hình, được gọi là Bộ phân loại trên tập dữ liệu này và sử dụng mô hình đó để dự đoán liệu một bệnh nhân nhất định có mắc bệnh hay không.
Do đó, kết quả bây giờ phụ thuộc vào:
Các tính năng này có thể “ánh xạ” đến kết quả tốt như thế nào.
Chất lượng của tập dữ liệu của chúng ta. Về chất lượng, ta đề cập đến chất lượng thống kê và Toán học.
Trình phân loại của chúng ta tổng quát hóa mối quan hệ này giữa các tính năng và kết quả tốt như thế nào.
Giá trị của x1 và x2.
Sau đây là sơ đồ khối tổng quát của nhiệm vụ phân loại.
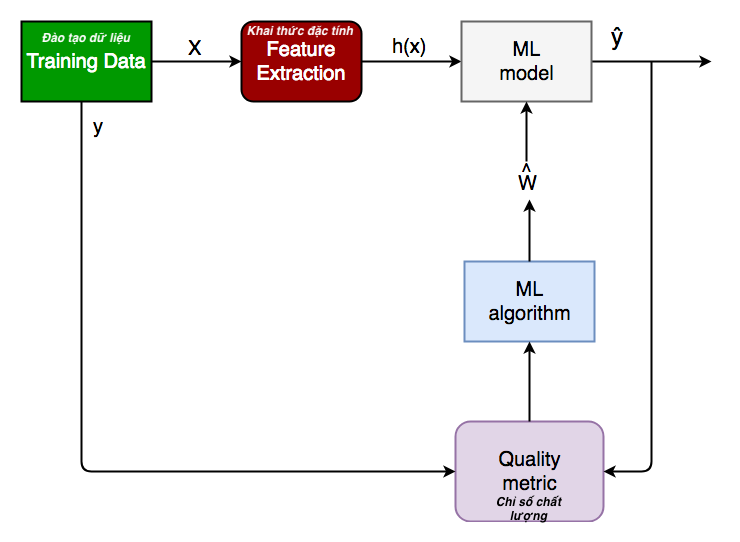
4. Sơ đồ khối phân loại tổng quát.
X: dữ liệu được phân loại trước, ở dạng ma trận N * M. N là không. trong số các quan sát và M là số đối tượng
y: Một vectơ N-d tương ứng với các lớp dự đoán cho mỗi N quan sát.
Tính năng trích xuất: Trích xuất thông tin có giá trị từ đầu vào X bằng một loạt các phép biến đổi.
Mô hình ML: “Bộ phân loại” mà chúng ta sẽ đào tạo.
y ’: Các nhãn do Bộ phân loại dự đoán.
Chỉ số chất lượng: Chỉ số được sử dụng để đo lường hiệu suất của mô hình.
Thuật toán ML: Thuật toán được sử dụng để cập nhật trọng số w ’, cập nhật mô hình và“ học ”lặp đi lặp lại.
5. Các kiểu bộ phân loại (thuật toán)
Có nhiều kiểu phân loại. Một số trong số đó là:
- Bộ phân loại tuyến tính: Hồi quy logistic
- Bộ phân loại dựa trên cây: Bộ phân loại cây quyết định
- Hỗ trợ các Bộ Máy Vector
- Mạng lưới thần kinh nhân tạo
- Hồi quy Bayes
- Gaussian Naive Bayes phân loại
- Bộ phân loại Stochastic Gradient Descent (SGD)
- Phương pháp kết hợp: Rừng ngẫu nhiên, AdaBoost, Bộ phân loại đóng gói, Bộ phận loại bỏ phiếu, Bộ phân loại ExtraTrees
Mô tả chi tiết về các phương pháp này trong các bài tiếp theo nha ace.
6. Ứng dụng thực tế của phân loại
- Xe tự lái của Google sử dụng các kỹ thuật phân loại hỗ trợ học sâu(Deep learning), cho phép nó phát hiện và phân loại chướng ngại vật.
- Thư rác Lọc e-mail là một trong những cách sử dụng phổ biến nhất và được công nhận của kỹ thuật Phân loại.
- Phát hiện các vấn đề về sức khỏe, Nhận dạng khuôn mặt, Nhận dạng giọng nói, Phát hiện đối tượng, Phân tích cảm xúc đều sử dụng Phân loại làm cốt lõi của chúng.
7. Thực hiện
Hãy cùng tìm hiểu kinh nghiệm về cách hoạt động của Phân loại. Chúng ta sẽ nghiên cứu về các Bộ phân loại khác nhau và xem một so sánh phân tích khá đơn giản về hiệu suất của chúng trên một tập dữ liệu chuẩn, nổi tiếng, tập dữ liệu Iris.
Yêu cầu để chạy tập lệnh đã cho:
- Python 2.7
- Scipy và Numpy
- Matplotlib để trực quan hóa dữ liệu
- Pandas cho dữ liệu i / o
- Scikit-learning Cung cấp tất cả các bộ phân loại
Triển khai Python – Liên kết Github tới Dự án
8. Phần kết luận
Phân loại là một lĩnh vực nghiên cứu rất rộng lớn. Mặc dù nó bao gồm một phần nhỏ của M L nói chung, nhưng nó là một trong những phần quan trọng nhất.
Trong bài viết tiếp theo, chúng ta sẽ xem cách Phân loại hoạt động trong thực tế với Mã Python.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}