
Nội dung chính
1. Gradient Descent là gì?
Trước khi giải thích Stochastic Gradient Descent (SGD), trước tiên chúng ta hãy mô tả Gradient Descent là gì. Gradient Descent là một kỹ thuật tối ưu hóa phổ biến trong ML và Học sâu và nó có thể được sử dụng với hầu hết, nếu không phải tất cả, các thuật toán học tập. Gradient là độ dốc của một hàm. Nó đo lường mức độ thay đổi của một biến để đáp ứng với những thay đổi của một biến khác. Về mặt toán học, Gradient Descent là một hàm lồi có đầu ra là đạo hàm riêng của một tập các tham số đầu vào của nó. Gradient càng lớn thì độ dốc càng lớn.
Bắt đầu từ một giá trị ban đầu, Gradient Descent được chạy lặp đi lặp lại để tìm các giá trị tối ưu của các tham số để tìm giá trị nhỏ nhất có thể có của chi phí hàm đã cho.
2. Các loại Gradient Descent:
Thông thường, có ba loại Gradient Descent:
- Batch Gradient Descent
- Stochastic Gradient Descent
- Đổ dốc màu theo lô nhỏ
Trong bài viết này, chúng ta sẽ thảo luận về Stochastic Gradient Descent hoặc SGD.
3. Stochastic Gradient Descent (SGD):
Từ ‘stochastic‘ có nghĩa là một hệ thống hoặc một quá trình được liên kết với một xác suất ngẫu nhiên. Do đó, trong Stochastic Gradient Descent, một vài mẫu được chọn ngẫu nhiên thay vì toàn bộ tập dữ liệu cho mỗi lần lặp. Trong Gradient Descent, có một thuật ngữ gọi là “batch”, biểu thị tổng số mẫu từ tập dữ liệu được sử dụng để tính toán gradient cho mỗi lần lặp. Trong tối ưu hóa Gradient Descent điển hình, như Batch Gradient Descent, lô được coi là toàn bộ tập dữ liệu. Mặc dù, việc sử dụng toàn bộ tập dữ liệu thực sự hữu ích để đi đến cực tiểu theo cách ít ồn ào hơn và ít ngẫu nhiên hơn, nhưng vấn đề nảy sinh khi tập dữ liệu của chúng ta lớn hơn.
Giả sử, bạn có một triệu mẫu trong tập dữ liệu của mình, vì vậy nếu bạn sử dụng kỹ thuật tối ưu hóa Gradient Descent điển hình, bạn sẽ phải sử dụng tất cả một triệu mẫu để hoàn thành một lần lặp trong khi thực hiện Gradient Descent, và nó phải được thực hiện cho mỗi lần lặp cho đến khi đạt đến cực tiểu. Do đó, nó trở nên rất tốn kém về mặt tính toán để thực hiện.
Vấn đề này được giải quyết bằng Stochastic Gradient Descent. Trong SGD, nó chỉ sử dụng một mẫu duy nhất, tức là kích thước lô của một mẫu, để thực hiện mỗi lần lặp. Mẫu được xáo trộn ngẫu nhiên và được chọn để thực hiện lặp lại.
Thuật toán SGD:
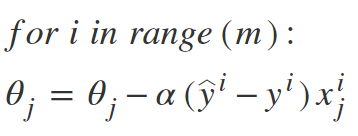
Vì vậy, trong SGD, chúng ta tìm ra gradient của chi phí hàm của một ví dụ duy nhất tại mỗi lần lặp thay vì tổng gradient của hàm chi phí của tất cả các ví dụ.
Trong SGD, vì chỉ có một mẫu từ tập dữ liệu được chọn ngẫu nhiên cho mỗi lần lặp, nên đường dẫn mà thuật toán thực hiện để đến cực tiểu thường ồn ào hơn so với thuật toán Gradient Descent điển hình của bạn. Nhưng điều đó không quan trọng lắm vì đường đi của thuật toán không quan trọng, miễn là chúng ta đạt đến cực tiểu và với thời gian đào tạo ngắn hơn đáng kể.
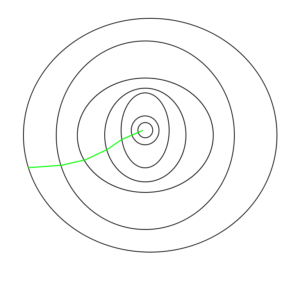
Đường dẫn được thực hiện bởi Batch Gradient Descent –
Đường dẫn được thực hiện bởi Stochastic Gradient Descent –
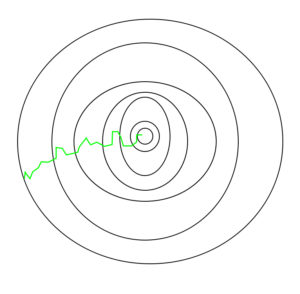
Một điều cần lưu ý là, vì SGD nói chung ồn hơn so với Gradient Descent điển hình, nên nó thường mất một số lần lặp lại cao hơn để đạt đến cực tiểu, vì tính ngẫu nhiên trong dữ liệu của nó. Mặc dù nó yêu cầu số lần lặp lại cao hơn để đạt đến cực tiểu so với Gradient Descent truyền thống, nhưng về mặt tính toán nó vẫn ít tốn kém hơn nhiều so với Gradient Descent truyền thống. Do đó, trong hầu hết các tình huống, SGD được ưu tiên hơn Batch Gradient Descent để tối ưu hóa thuật toán học tập.
Mã giả cho SGD bằng Python:
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
def SGD(f, theta0, alpha, num_iters):
"""
Arguments:
f -- the function to optimize, it takes a single argument
and yield two outputs, a cost and the gradient
with respect to the arguments
theta0 -- the initial point to start SGD from
num_iters -- total iterations to run SGD for
Return:
theta -- the parameter value after SGD finishes
"""
start_iter = 0
theta = theta0
for iter in xrange(start_iter + 1, num_iters + 1):
_, grad = f(theta)
# there is NO dot product ! return theta
theta = theta - (alpha * grad) Chu kỳ lấy các giá trị và điều chỉnh chúng dựa trên các tham số khác nhau để giảm hàm mất mát được gọi là lan truyền ngược.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


, trước tiên chúng ta hãy mô tả Gradient Descent là gì. Gradient Descent là một kỹ thuật tối ưu hóa phổ biến trong ML và Học sâu){kind=link}