
Bài này cafedev chia sẽ cho ace kiến thức về TIỀN XỬ LÝ DỮ LIỆU trước khi dùng dữ liệu cho ML để nó học. Chúng ta hãy tham khảo bài sau đây.
• Tiền xử lý đề cập đến các phép biến đổi được áp dụng cho dữ liệu của chúng ta trước khi đưa nó vào thuật toán.
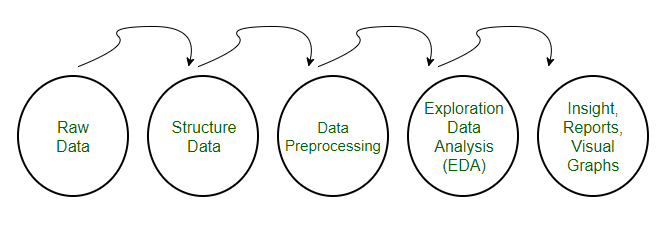
• Tiền xử lý dữ liệu là một kỹ thuật được sử dụng để chuyển đổi dữ liệu thô thành một tập dữ liệu sạch. Nói cách khác, bất cứ khi nào dữ liệu được thu thập từ các nguồn khác nhau, nó được thu thập ở định dạng thô không khả thi cho việc phân tích.
Nội dung chính
1. Cần tiền xử lý dữ liệu
• Để đạt được kết quả tốt hơn từ mô hình được áp dụng trong các dự án ML , định dạng của dữ liệu phải theo cách phù hợp. Một số mô hình ML được chỉ định cần thông tin ở định dạng được chỉ định, ví dụ: thuật toán Rừng ngẫu nhiên không hỗ trợ giá trị null, do đó, để thực thi thuật toán rừng ngẫu nhiên, giá trị rỗng phải được quản lý từ tập dữ liệu thô ban đầu.
• Một khía cạnh khác là tập dữ liệu nên được định dạng theo cách mà nhiều hơn một thuật toán ML và Học sâu được thực thi trong một tập dữ liệu và tốt nhất trong số chúng được chọn.
Bài viết này bao gồm 3 kỹ thuật tiền xử lý dữ liệu khác nhau cho ML:
Bộ dữ liệu về bệnh tiểu đường ở Ấn Độ Pima được sử dụng trong từng kỹ thuật.
Đây là một bài toán phân loại nhị phân trong đó tất cả các thuộc tính đều là số và có các tỷ lệ khác nhau.
Đây là một ví dụ tuyệt vời về tập dữ liệu có thể được hưởng lợi từ việc xử lý trước.
Bạn có thể tìm thấy bộ dữ liệu này trên trang web của Kho lưu trữ Máy học UCI.
2. Tuỳ chỉnh lại dữ liệu
• Khi dữ liệu của chúng ta bao gồm các thuộc tính với các tỷ lệ khác nhau, nhiều thuật toán ML có thể hưởng lợi từ việc thay đổi tỷ lệ các thuộc tính để tất cả các thuộc tính có cùng tỷ lệ.
• Điều này hữu ích cho các thuật toán tối ưu hóa được sử dụng trong lõi của các thuật toán ML như gradient descent.
• Nó cũng hữu ích cho các thuật toán có trọng số đầu vào như hồi quy và mạng nơ-ron và các thuật toán sử dụng các phép đo khoảng cách như K-Nearest Neighbors.
• Chúng ta có thể bán lại dữ liệu của bạn bằng scikit-learning bằng cách sử dụng lớp MinMaxScaler.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# Python code to Rescale data (between 0 and 1)
import pandas
import scipy
import numpy
from sklearn.preprocessing import MinMaxScaler
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = pandas.read_csv(url, names=names)
array = dataframe.values
# separate array into input and output components
X = array[:,0:8]
Y = array[:,8]
scaler = MinMaxScaler(feature_range=(0, 1))
rescaledX = scaler.fit_transform(X)
# summarize transformed data
numpy.set_printoptions(precision=3)
print(rescaledX[0:5,:]) Sau khi thay đổi tỷ lệ, hãy thấy rằng tất cả các giá trị đều nằm trong khoảng từ 0 đến 1.
Output
[[ 0.353 0.744 0.59 0.354 0.0 0.501 0.234 0.483]
[ 0.059 0.427 0.541 0.293 0.0 0.396 0.117 0.167]
[ 0.471 0.92 0.525 0. 0.0 0.347 0.254 0.183]
[ 0.059 0.447 0.541 0.232 0.111 0.419 0.038 0.0 ]
[ 0.0 0.688 0.328 0.354 0.199 0.642 0.944 0.2 ]]3. Binarize Data (Tạo nhị phân)
• Chúng ta có thể biến đổi dữ liệu của mình bằng cách sử dụng ngưỡng nhị phân. Tất cả các giá trị trên ngưỡng được đánh dấu 1 và tất cả bằng hoặc thấp hơn được đánh dấu là 0.
• Điều này được gọi là mã hóa dữ liệu của bạn hoặc ngưỡng dữ liệu của bạn. Nó có thể hữu ích khi bạn có xác suất mà bạn muốn tạo ra các giá trị rõ nét. Nó cũng hữu ích khi kỹ thuật tính năng và bạn muốn thêm các tính năng mới cho biết điều gì đó có ý nghĩa.
• Chúng ta có thể tạo các thuộc tính nhị phân mới trong Python bằng cách sử dụng scikit-learning với lớp Binarizer.
# Python code for binarization
from sklearn.preprocessing import Binarizer
import pandas
import numpy
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = pandas.read_csv(url, names=names)
array = dataframe.values
# separate array into input and output components
X = array[:,0:8]
Y = array[:,8]
binarizer = Binarizer(threshold=0.0).fit(X)
binaryX = binarizer.transform(X)
# summarize transformed data
numpy.set_printoptions(precision=3)
print(binaryX[0:5,:]) Chúng ta có thể thấy rằng tất cả các giá trị bằng hoặc nhỏ hơn 0 được đánh dấu 0 và tất cả các giá trị trên 0 được đánh dấu 1.
Output
[[ 1. 1. 1. 1. 0. 1. 1. 1.]
[ 1. 1. 1. 1. 0. 1. 1. 1.]
[ 1. 1. 1. 0. 0. 1. 1. 1.]
[ 1. 1. 1. 1. 1. 1. 1. 1.]
[ 0. 1. 1. 1. 1. 1. 1. 1.]]3. Chuẩn hóa dữ liệu
• Chuẩn hóa là một kỹ thuật hữu ích để biến đổi các thuộc tính có phân phối Gaussian và các phương tiện khác nhau và độ lệch chuẩn thành phân phối Gaussian chuẩn với giá trị trung bình là 0 và độ lệch chuẩn là 1.
• Chúng ta có thể chuẩn hóa dữ liệu bằng cách sử dụng scikit-learning với lớp StandardScaler.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# Python code to Standardize data (0 mean, 1 stdev)
from sklearn.preprocessing import StandardScaler
import pandas
import numpy
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = pandas.read_csv(url, names=names)
array = dataframe.values
# separate array into input and output components
X = array[:,0:8]
Y = array[:,8]
scaler = StandardScaler().fit(X)
rescaledX = scaler.transform(X)
# summarize transformed data
numpy.set_printoptions(precision=3)
print(rescaledX[0:5,:]) Các giá trị cho mỗi thuộc tính hiện có giá trị trung bình là 0 và độ lệch chuẩn là 1.
Output
[[ 0.64 0.848 0.15 0.907 -0.693 0.204 0.468 1.426]
[-0.845 -1.123 -0.161 0.531 -0.693 -0.684 -0.365 -0.191]
[ 1.234 1.944 -0.264 -1.288 -0.693 -1.103 0.604 -0.106]
[-0.845 -0.998 -0.161 0.155 0.123 -0.494 -0.921 -1.042]
[-1.142 0.504 -1.505 0.907 0.766 1.41 5.485 -0.02 ]]Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}