
Nội dung chính
1. Học tập không giám sát:
Đó là một kiểu học tập mà chúng ta không đưa ra mục tiêu cho mô hình của mình trong khi đào tạo, tức là mô hình đào tạo chỉ có các giá trị tham số đầu vào. Bản thân mô hình phải tìm ra cách nó có thể học được. Tập dữ liệu trong Hình A là dữ liệu trung tâm thương mại chứa thông tin của các khách hàng đăng ký với họ. Sau khi đăng ký, họ sẽ được cung cấp thẻ thành viên và do đó, trung tâm mua sắm có thông tin đầy đủ về khách hàng và của họ mỗi lần mua hàng. Giờ đây, bằng cách sử dụng dữ liệu này và các kỹ thuật học tập không giám sát, trung tâm mua sắm có thể dễ dàng nhóm khách hàng dựa trên các thông số mà chúng ta đang cung cấp.
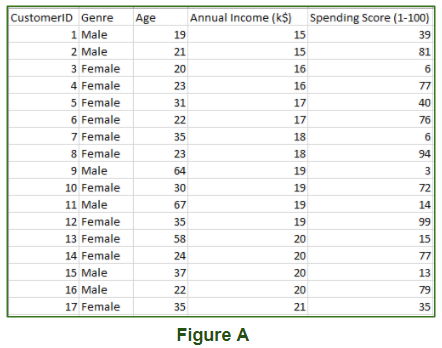
Dữ liệu đào tạo mà chúng ta đang cung cấp là
- Dữ liệu phi cấu trúc: Có thể chứa dữ liệu nhiễu (vô nghĩa), thiếu giá trị hoặc dữ liệu không xác định
- Dữ liệu không được gắn nhãn: Dữ liệu chỉ chứa giá trị cho các tham số đầu vào, không có giá trị được nhắm mục tiêu (đầu ra). Nó dễ dàng thu thập so với được gắn nhãn trong phương pháp được Giám sát.
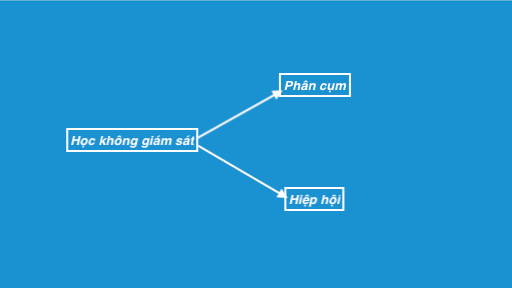
Các kiểu học không giám sát:
- Phân cụm: Nói chung, kỹ thuật này được áp dụng để nhóm dữ liệu dựa trên các mẫu khác nhau, mô hình máy của chúng ta nhận thấy. Ví dụ trong hình trên, chúng ta không được cung cấp giá trị tham số đầu ra, vì vậy kỹ thuật này sẽ được sử dụng để nhóm các khách hàng dựa trên các tham số đầu vào được cung cấp bởi dữ liệu của chúng tôi.
- Kết hợp(hiệp hội): Kỹ thuật này là một kỹ thuật ML dựa trên quy tắc tìm ra một số mối quan hệ rất hữu ích giữa các tham số của một tập dữ liệu lớn. Ví dụ cửa hàng mua sắm sử dụng các thuật toán dựa trên kỹ thuật này để tìm ra mối quan hệ giữa việc bán một sản phẩm này với việc bán hàng khác dựa trên hành vi của khách hàng. Sau khi được đào tạo tốt, những mô hình như vậy có thể được sử dụng để tăng doanh số bán hàng của họ bằng cách lập kế hoạch chào hàng khác nhau.
2. Một số thuật toán:
- K-Means Clustering
- DBSCAN – Phân cụm không gian dựa trên mật độ của các ứng dụng có tiếng ồn
- BIRCH – Giảm lặp lại cân bằng và phân cụm bằng cách sử dụng cấu trúc phân cấp
- Phân cụm phân cấp
3. Học tập bán giám sát:
Như tên cho thấy, hoạt động của nó nằm giữa các kỹ thuật được giám sát và không được giám sát. Chúng ta sử dụng các kỹ thuật này khi chúng ta xử lý dữ liệu có một chút ít được gắn nhãn và phần lớn còn lại của nó không được gắn nhãn. Chúng ta có thể sử dụng kỹ thuật không được giám sát để dự đoán các nhãn và sau đó cung cấp các nhãn này cho các kỹ thuật được giám sát. Kỹ thuật này hầu như được áp dụng trong trường hợp tập dữ liệu hình ảnh thường tất cả các hình ảnh không được gắn nhãn.
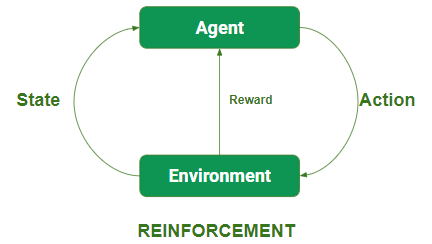
4. Học tăng cường:
Trong kỹ thuật này, mô hình tiếp tục tăng hiệu suất của nó bằng cách sử dụng Phản hồi khen thưởng để tìm hiểu hành vi hoặc mô hình. Các thuật toán này dành riêng cho một vấn đề cụ thể, ví dụ: Xe tự lái của Google, AlphaGo, nơi một bot cạnh tranh với con người và thậm chí với chính nó để trở nên ngày càng hoạt động tốt hơn trong Trò chơi cờ vây. Mỗi khi chúng ta cung cấp dữ liệu, chúng sẽ tìm hiểu và thêm dữ liệu vào kiến thức của nó, đó là dữ liệu đào tạo. Vì vậy, nó học càng nhiều thì nó càng được đào tạo tốt hơn và do đó có kinh nghiệm.
- Nơi quan sát đầu vào.
- Tác nhân thực hiện một hành động bằng cách đưa ra một số quyết định.
- Sau khi thực hiện, có một nơi nhận được phần thưởng và theo đó củng cố và mô hình lưu trữ trong cặp thông tin hành động trạng thái.
Một số thuật toán:
- Sự khác biệt theo thời gian (TD)
- Q-Learning
- Mạng đối thủ sâu
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}