
Mọi cây quyết định đều có phương sai cao, nhưng khi chúng ta kết hợp tất cả chúng lại với nhau song song thì phương sai của kết quả sẽ thấp vì mỗi cây quyết định được đào tạo hoàn hảo trên dữ liệu mẫu cụ thể đó và do đó kết quả đầu ra không phụ thuộc vào một cây quyết định mà là nhiều quyết định cây. Trong trường hợp có vấn đề phân loại, kết quả cuối cùng được thực hiện bằng cách sử dụng bộ phân loại biểu quyết đa số. Trong trường hợp bài toán hồi quy, đầu ra cuối cùng là giá trị trung bình của tất cả các đầu ra. Phần này là Tổng hợp.
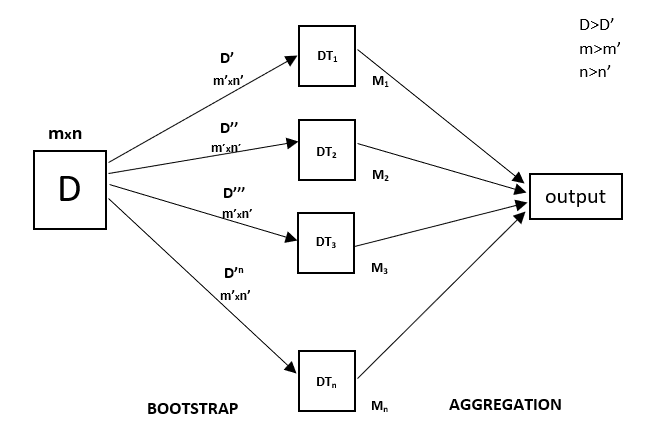
Rừng ngẫu nhiên là một kỹ thuật tổng hợp có khả năng thực hiện cả nhiệm vụ hồi quy và phân loại với việc sử dụng nhiều cây quyết định và một kỹ thuật được gọi là Bootstrap và Aggregation, thường được gọi là bagging. Ý tưởng cơ bản đằng sau điều này là kết hợp nhiều cây quyết định để xác định đầu ra cuối cùng thay vì dựa vào các cây quyết định riêng lẻ.
Rừng Ngẫu nhiên có nhiều cây quyết định làm mô hình học tập cơ sở. Chúng tôi thực hiện ngẫu nhiên lấy mẫu hàng và lấy mẫu tính năng từ tập dữ liệu tạo thành tập dữ liệu mẫu cho mọi mô hình. Phần này được gọi là Bootstrap.
Chúng ta cần tiếp cận kỹ thuật hồi quy Rừng ngẫu nhiên giống như bất kỳ kỹ thuật ML nào khác
- Thiết kế một câu hỏi hoặc dữ liệu cụ thể và lấy nguồn để xác định dữ liệu cần thiết.
- Đảm bảo dữ liệu ở định dạng có thể truy cập được, nếu không hãy chuyển đổi dữ liệu sang định dạng yêu cầu.
- Chỉ định tất cả các điểm bất thường đáng chú ý và các điểm dữ liệu bị thiếu có thể được yêu cầu để đạt được dữ liệu cần thiết.
- Tạo mô hình ML
- Đặt mô hình cơ sở mà bạn muốn đạt được
- Đào tạo mô hình học máy dữ liệu.
- Cung cấp thông tin chi tiết về mô hình với dữ liệu thử nghiệm
- Bây giờ, hãy so sánh các chỉ số hiệu suất của cả dữ liệu thử nghiệm và dữ liệu dự đoán từ mô hình.
- Nếu nó không đáp ứng mong đợi của bạn, bạn có thể thử cải thiện mô hình của mình cho phù hợp hoặc xác định niên đại dữ liệu của bạn hoặc sử dụng một kỹ thuật lập mô hình dữ liệu khác.
- Ở giai đoạn này, bạn giải thích dữ liệu bạn đã thu được và báo cáo cho phù hợp.
Bạn sẽ sử dụng một kỹ thuật mẫu tương tự trong ví dụ dưới đây.
1. Thí dụ
Dưới đây là từng bước thực hiện theo mẫu của Rando Forest Regression.
Bước 1: Nhập các thư viện cần thiết.
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd Bước 2: Nhập và in tập dữ liệu
data = pd.read_csv('Salaries.csv')
print(data) 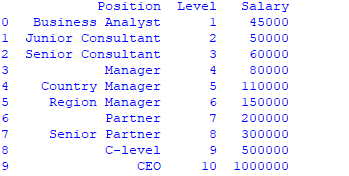
Bước 3: Chọn tất cả các hàng và cột 1 từ tập dữ liệu thành x và tất cả các hàng và cột 2 là y
x = data.iloc[:, 1:2].values
print(x)
y = data.iloc[:, 2].values 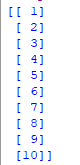

Bước 4: Điều chỉnh bộ hồi quy rừng ngẫu nhiên vào tập dữ liệu
# Fitting Random Forest Regression to the dataset
# import the regressor
from sklearn.ensemble import RandomForestRegressor
# create regressor object
regressor = RandomForestRegressor(n_estimators = 100, random_state = 0)
# fit the regressor with x and y data
regressor.fit(x, y)
Bước 5: Dự đoán một kết quả mới
Y_pred = regressor.predict(np.array([6.5]).reshape(1, 1)) # test the output by changing values
Bước 6: Hình dung kết quả
//Python
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# Visualising the Random Forest Regression results
# arange for creating a range of values
# from min value of x to max
# value of x with a difference of 0.01
# between two consecutive values
X_grid = np.arange(min(x), max(x), 0.01)
# reshape for reshaping the data into a len(X_grid)*1 array,
# i.e. to make a column out of the X_grid value
X_grid = X_grid.reshape((len(X_grid), 1))
# Scatter plot for original data
plt.scatter(x, y, color = 'blue')
# plot predicted data
plt.plot(X_grid, regressor.predict(X_grid),
color = 'green')
plt.title('Random Forest Regression')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()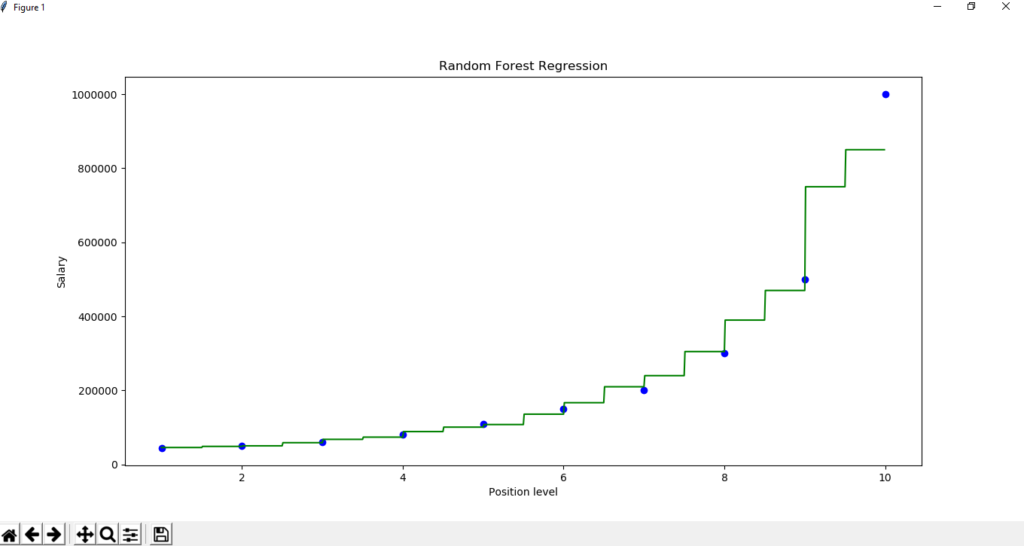
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}