
Mô hình ML được định nghĩa là một mô hình toán học với một số tham số cần được học từ dữ liệu. Tuy nhiên, có một số tham số, được gọi là Hyperparameters và chúng không thể học trực tiếp được. Chúng thường được con người lựa chọn dựa trên một số trực giác hoặc đánh và thử trước khi khóa huấn luyện thực sự bắt đầu. Các tham số này thể hiện tầm quan trọng của chúng bằng cách cải thiện hiệu suất của mô hình như độ phức tạp hoặc tốc độ học của nó. Mô hình có thể có nhiều siêu tham số(tham số cứ lớn) và việc tìm kiếm sự kết hợp tốt nhất của các tham số có thể được coi là một bài toán tìm kiếm.
SVM cũng có một số siêu tham số (như giá trị C hoặc gamma để sử dụng) và việc tìm kiếm siêu tham số tối ưu là một nhiệm vụ rất khó giải quyết. Nhưng nó có thể được tìm thấy bằng cách thử tất cả các kết hợp và xem thông số nào hoạt động tốt nhất. Ý tưởng chính đằng sau nó là tạo một lưới các siêu tham số và chỉ cần thử tất cả các kết hợp của chúng (do đó, phương pháp này được gọi là Gridsearch, nhưng đừng lo! Chúng ta không phải làm thủ công vì Scikit-learning có chức năng này được tích hợp sẵn với GridSearchCV.
GridSearchCV lấy một từ điển mô tả các tham số có thể được thử trên một mô hình để huấn luyện nó. Lưới tham số được định nghĩa như một từ điển, trong đó các khóa là các tham số và các giá trị là cài đặt cần kiểm tra.
Bài viết này cafedev trình bày cách sử dụng phương pháp tìm kiếm GridSearchCV để tìm các siêu tham số tối ưu và do đó cải thiện độ chính xác / kết quả dự đoán
Nội dung chính
1. Nhập các thư viện cần thiết và lấy Dữ liệu –
Chúng ta sẽ sử dụng bộ dữ liệu ung thư vú được tích hợp sẵn từ Scikit Learn. Chúng ta có thể nhận được với hàm tải:
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
cancer = load_breast_cancer()
# The data set is presented in a dictionary form:
print(cancer.keys()) dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])Bây giờ chúng tôi sẽ trích xuất tất cả các tính năng vào khung dữ liệu mới và các tính năng mục tiêu của chúng tôi vào khung dữ liệu riêng biệt.
df_feat = pd.DataFrame(cancer['data'],
columns = cancer['feature_names'])
# cancer column is our target
df_target = pd.DataFrame(cancer['target'],
columns =['Cancer'])
print("Feature Variables: ")
print(df_feat.info())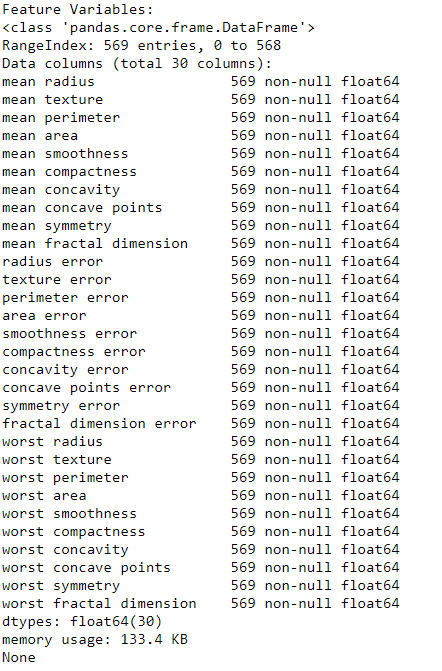
print("Dataframe looks like : ")
print(df_feat.head())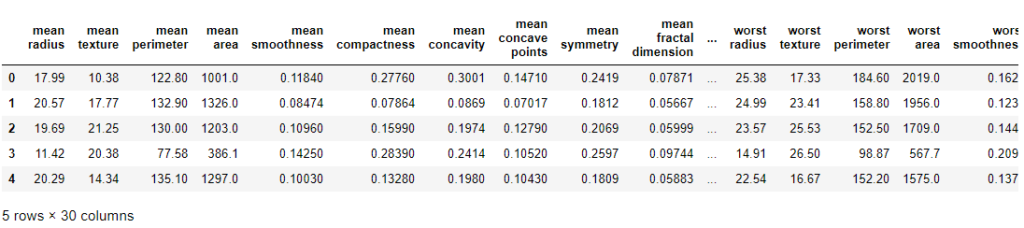
2. Tách kiểm tra tàu hỏa
Bây giờ chúng ta sẽ chia dữ liệu của mình thành tập huấn luyện và thử nghiệm với tỷ lệ 70: 30
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
df_feat, np.ravel(df_target),
test_size = 0.30, random_state = 101) Đào tạo Bộ phân loại vectơ hỗ trợ mà không cần Điều chỉnh siêu tham số –
Đầu tiên, chúng ta sẽ đào tạo mô hình của mình bằng cách gọi hàm SVC () tiêu chuẩn mà không thực hiện Điều chỉnh siêu tham số và xem ma trận phân loại và nhầm lẫn của nó.
# train the model on train set
model = SVC()
model.fit(X_train, y_train)
# print prediction results
predictions = model.predict(X_test)
print(classification_report(y_test, predictions)) 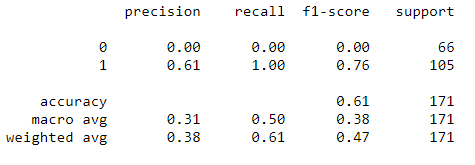
Chúng ta có độ chính xác 61% nhưng bạn có nhận thấy điều gì lạ không?
Lưu ý rằng sự thu hồi và độ chính xác cho lớp 0 luôn bằng 0. Có nghĩa là trình phân loại luôn phân loại mọi thứ thành một lớp duy nhất, tức là lớp 1! Điều này có nghĩa là mô hình của chúng ta cần được điều chỉnh các thông số của nó.
Đây là lúc tính hữu ích của GridSearch được đưa ra. Chúng ta có thể tìm kiếm các tham số bằng GridSearch!
3. Sử dụng GridsearchCV
Một trong những điều tuyệt vời về GridSearchCV là nó là một công cụ ước tính meta. Nó cần một công cụ ước tính như SVC và tạo một công cụ ước tính mới, hoạt động giống hệt nhau – trong trường hợp này, giống như một trình phân loại. Bạn nên thêm refit = True và chọn dài dòng cho bất kỳ số nào bạn muốn, số càng cao thì càng dài (dài chỉ có nghĩa là đầu ra văn bản mô tả quá trình).
from sklearn.model_selection import GridSearchCV
# defining parameter range
param_grid = {'C': [0.1, 1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001, 0.0001],
'kernel': ['rbf']}
grid = GridSearchCV(SVC(), param_grid, refit = True, verbose = 3)
# fitting the model for grid search
grid.fit(X_train, y_train) Những gì phù hợp làm là tham gia nhiều hơn một chút so với bình thường. Đầu tiên, nó chạy cùng một vòng lặp với xác nhận chéo, để tìm ra kết hợp tham số tốt nhất. Sau khi có sự kết hợp tốt nhất, nó sẽ chạy khớp trở lại trên tất cả dữ liệu được truyền cho vừa khớp (không xác nhận chéo), để tạo một mô hình mới duy nhất bằng cách sử dụng cài đặt thông số tốt nhất.
Bạn có thể kiểm tra các thông số tốt nhất do GridSearchCV tìm thấy trong thuộc tính best_params_ và công cụ ước tính tốt nhất trong thuộc tính best_estimator_:
# print best parameter after tuning
print(grid.best_params_)
# print how our model looks after hyper-parameter tuning
print(grid.best_estimator_) 
Sau đó, bạn có thể chạy lại các dự đoán và xem báo cáo phân loại trên đối tượng lưới này giống như bạn làm với mô hình bình thường.
grid_predictions = grid.predict(X_test)
# print classification report
print(classification_report(y_test, grid_predictions)) 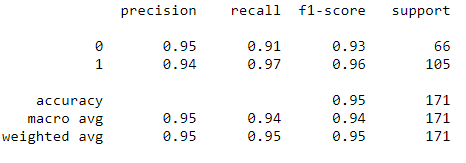
Chúng ta đã có kết quả dự đoán gần như 95%.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}