
Giới thiệu về SVM:
Trong ML, hỗ trợ máy vectơ (SVM, cũng hỗ trợ mạng vectơ) là mô hình học có giám sát với các thuật toán học liên quan phân tích dữ liệu được sử dụng để phân loại và phân tích hồi quy.
Hỗ trợ máy vectơ (SVM) là một bộ phân loại phân biệt được xác định chính thức bởi một siêu phẳng phân tách. Nói cách khác, với dữ liệu đào tạo được gắn nhãn (học có giám sát), thuật toán sẽ xuất ra một siêu phẳng tối ưu phân loại các ví dụ mới.
Nội dung chính
1. Máy hỗ trợ Vector là gì?
Mô hình SVM là một biểu diễn của các ví dụ dưới dạng các điểm trong không gian, được ánh xạ sao cho các ví dụ của các danh mục riêng biệt được chia theo một khoảng trống rõ ràng càng rộng càng tốt.
Ngoài việc thực hiện phân loại tuyến tính, SVM có thể thực hiện phân loại phi tuyến tính một cách hiệu quả, ánh xạ ngầm các đầu vào của chúng vào không gian đặc trưng chiều cao.
2. SVM làm gì?
Đưa ra một tập hợp các ví dụ đào tạo, mỗi ví dụ được đánh dấu là thuộc một hoặc thuộc hai danh mục, thuật toán đào tạo SVM xây dựng một mô hình gán các ví dụ mới cho một danh mục này hoặc danh mục kia, biến nó thành một bộ phân loại tuyến tính nhị phân không xác suất.
Để bạn có những hiểu biết cơ bản từ bài viết này trước khi bạn tiến hành thêm. Ở đây ta sẽ thảo luận một ví dụ về phân loại SVM của tập dữ liệu UCI ung thư bằng cách sử dụng các công cụ học máy, tức là scikit-learning tương thích với Python.
Điều kiện tiên quyết phải biết: Numpy, Pandas, matplot-lib, scikit-learning
Hãy xem một ví dụ nhanh về phân loại vectơ hỗ trợ. Trước tiên, chúng ta cần tạo một tập dữ liệu:
# importing scikit learn with make_blobs
from sklearn.datasets.samples_generator import make_blobs
# creating datasets X containing n_samples
# Y containing two classes
X, Y = make_blobs(n_samples=500, centers=2,
random_state=0, cluster_std=0.40)
import matplotlib.pyplot as plt
# plotting scatters
plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap='spring');
plt.show() Output
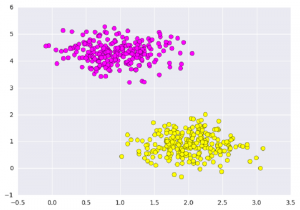
Điều mà máy hỗ trợ vectơ làm, là không chỉ vẽ một đường thẳng giữa hai lớp ở đây, mà còn xem xét một vùng nằm về đường có độ rộng nhất định. Dưới đây là một ví dụ về những gì nó có thể trông như thế nào:
# creating line space between -1 to 3.5
xfit = np.linspace(-1, 3.5)
# plotting scatter
plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap='spring')
# plot a line between the different sets of data
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, '-k')
plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none',
color='#AAAAAA', alpha=0.4)
plt.xlim(-1, 3.5);
plt.show()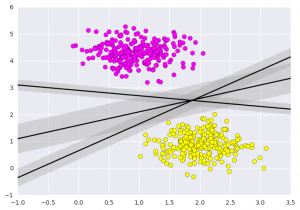
3. Nhập tập dữ liệu
Đây là trực giác của máy vectơ hỗ trợ, tối ưu hóa mô hình phân biệt tuyến tính biểu thị khoảng cách vuông góc giữa các tập dữ liệu. Bây giờ, hãy đào tạo người phân loại bằng cách sử dụng dữ liệu đào tạo của chúng ta. Trước khi đào tạo, chúng tôi cần nhập bộ dữ liệu ung thư dưới dạng tệp csv, nơi chúng tôi sẽ đào tạo hai tính năng trong số tất cả các tính năng.
//Python
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# importing required libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# reading csv file and extracting class column to y.
x = pd.read_csv("C:\...\cancer.csv")
a = np.array(x)
y = a[:,30] # classes having 0 and 1
# extracting two features
x = np.column_stack((x.malignant,x.benign))
# 569 samples and 2 features
x.shape
print (x),(y) [[ 122.8 1001. ]
[ 132.9 1326. ]
[ 130. 1203. ]
...,
[ 108.3 858.1 ]
[ 140.1 1265. ]
[ 47.92 181. ]]
array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 1., 1., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 1., 1., 1.,
1., 0., 0., 1., 0., 0., 1., 1., 1., 1., 0., 1., ....,
1.])4. Lắp hỗ trợ máy vectơ
Bây giờ chúng ta sẽ điều chỉnh một Bộ phân loại máy vectơ hỗ trợ đến những điểm này. Mặc dù các chi tiết toán học của mô hình khả năng rất thú vị, nhưng chúng ta sẽ đọc về các chi tiết đó ở những nơi khác. Thay vào đó, chúng tôi sẽ chỉ coi thuật toán scikit-learning như một hộp đen hoàn thành nhiệm vụ ở trên.
# import support vector classifier
# "Support Vector Classifier"
from sklearn.svm import SVC
clf = SVC(kernel='linear')
# fitting x samples and y classes
clf.fit(x, y)Sau khi được trang bị, mô hình sau đó có thể được sử dụng để dự đoán các giá trị mới:
clf.predict([[120, 990]])
clf.predict([[85, 550]]) array([ 0.])
array([ 1.])Hãy cùng xem biểu đồ này hiển thị như thế nào.
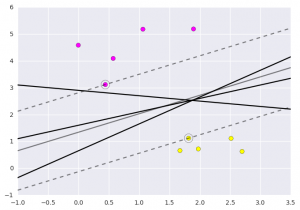
Điều này có được bằng cách phân tích dữ liệu đã lấy và các phương pháp xử lý trước để tạo ra các siêu máy bay tối ưu bằng cách sử dụng hàm matplotlib.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


 là mô hình học có giám sát với các thuật toán học liên quan phân tích dữ liệu được sử dụng để phân loại và phân tích hồi quy.){kind=link}