
Hồi quy tuyến tính là một thuật toán học máy dựa trên việc học có giám sát. Nó thực hiện một nhiệm vụ hồi quy. Mô hình hồi quy một giá trị dự đoán mục tiêu dựa trên các biến độc lập. Nó chủ yếu được sử dụng để tìm ra mối quan hệ giữa các biến và dự báo. Các mô hình hồi quy khác nhau khác nhau dựa trên – loại mối quan hệ giữa các biến phụ thuộc và độc lập, chúng đang xem xét và số lượng biến độc lập đang được sử dụng.
Nếu bạn chưa hiểu rõ về Hồi quy tuyến tính, bạn có thể tham khảo tại series này.
Bài viết này sẽ trình bày cách sử dụng các thư viện Python khác nhau để triển khai hồi quy tuyến tính trên một tập dữ liệu nhất định. Chúng ta sẽ chứng minh một mô hình tuyến tính nhị phân vì điều này sẽ dễ hình dung hơn.
Trong phần trình diễn này, mô hình sẽ sử dụng Gradient Descent để học. Bạn có thể tìm hiểu về nó ở đây.
Nội dung chính
1. Bước 1: Nhập tất cả các thư viện bắt buộc
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing, svm
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression 2. Bước 2: Đọc tập dữ liệu
Bạn có thể tải xuống bộ dữ liệu tại đây.
cd C:\Users\Dev\Desktop\Kaggle\Salinity
# Changing the file read location to the location of the dataset
df = pd.read_csv('bottle.csv')
df_binary = df[['Salnty', 'T_degC']]
# Taking only the selected two attributes from the dataset
df_binary.columns = ['Sal', 'Temp']
# Renaming the columns for easier writing of the code
df_binary.head()
# Displaying only the 1st rows along with the column names 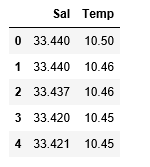
3. Bước 3: Khám phá phân tán dữ liệu
sns.lmplot(x ="Sal", y ="Temp", data = df_binary, order = 2, ci = None)
# Plotting the data scatter 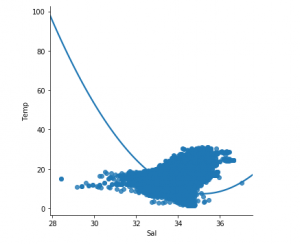
4. Bước 4: Làm sạch dữ liệu
# Eliminating NaN or missing input numbers
df_binary.fillna(method ='ffill', inplace = True) 5. Bước 5: Đào tạo mô hình của chúng ta
X = np.array(df_binary['Sal']).reshape(-1, 1)
y = np.array(df_binary['Temp']).reshape(-1, 1)
# Separating the data into independent and dependent variables
# Converting each dataframe into a numpy array
# since each dataframe contains only one column
df_binary.dropna(inplace = True)
# Dropping any rows with Nan values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
# Splitting the data into training and testing data
regr = LinearRegression()
regr.fit(X_train, y_train)
print(regr.score(X_test, y_test))6. Bước 6: Khám phá kết quả của chúng ta
y_pred = regr.predict(X_test)
plt.scatter(X_test, y_test, color ='b')
plt.plot(X_test, y_pred, color ='k')
plt.show()
# Data scatter of predicted values 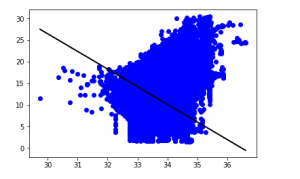
Điểm chính xác thấp của mô hình của chúng ta cho thấy rằng mô hình hồi quy của chúng ta không phù hợp lắm với dữ liệu hiện có. Điều này cho thấy rằng dữ liệu của chúng ta không phù hợp với hồi quy tuyến tính. Nhưng đôi khi, một tập dữ liệu có thể chấp nhận một công cụ hồi quy tuyến tính nếu chúng ta chỉ xem xét một phần của nó. Hãy để chúng ta kiểm tra khả năng đó.
7. Bước 7: Làm việc với tập dữ liệu nhỏ hơn
df_binary500 = df_binary[:][:500]
# Selecting the 1st 500 rows of the data
sns.lmplot(x ="Sal", y ="Temp", data = df_binary500,
order = 2, ci = None) 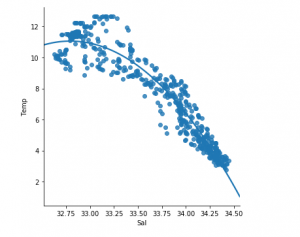
Chúng ta đã có thể thấy rằng 500 hàng đầu tiên tuân theo mô hình tuyến tính. Tiếp tục các bước tương tự như trước.
df_binary500.fillna(method ='ffill', inplace = True)
X = np.array(df_binary500['Sal']).reshape(-1, 1)
y = np.array(df_binary500['Temp']).reshape(-1, 1)
df_binary500.dropna(inplace = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
regr = LinearRegression()
regr.fit(X_train, y_train)
print(regr.score(X_test, y_test))
brightness_4
y_pred = regr.predict(X_test)
plt.scatter(X_test, y_test, color ='b')
plt.plot(X_test, y_pred, color ='k')
plt.show() 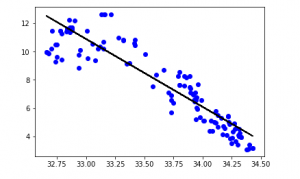
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}