
Điều kiện tiên quyết để học bài này:
Chúng ta sẽ tóm tắt ngắn gọn Hồi quy tuyến tính trước khi triển khai nó bằng Tensorflow. Vì chúng ta sẽ không đi sâu vào chi tiết của Hồi quy tuyến tính hoặc Tensorflow, vui lòng đọc các bài viết sau để biết thêm chi tiết:
- Hồi quy tuyến tính (Triển khai Python)
- Giới thiệu về TensorFlow
- Giới thiệu về Tensor với Tensorflow
Nội dung chính
1. Tóm tắt ngắn gọn về hồi quy tuyến tính
Hồi quy tuyến tính là một phương pháp thống kê rất phổ biến cho phép chúng ta tìm hiểu một hàm hoặc mối quan hệ từ một tập dữ liệu liên tục nhất định. Ví dụ, chúng ta được cung cấp một số điểm dữ liệu của x và y tương ứng và chúng ta cần tìm hiểu mối quan hệ giữa chúng được gọi là giả thuyết.
Trong trường hợp hồi quy tuyến tính, giả thuyết là một đường thẳng, tức là
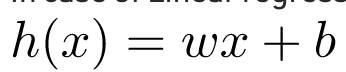
Trong đó w là một vectơ được gọi là Trọng số và b là một đại lượng vô hướng được gọi là Bias. Trọng số và Độ lệch được gọi là các tham số của mô hình.
Tất cả những gì chúng ta cần làm là ước tính giá trị của w và b từ tập dữ liệu đã cho sao cho giả thuyết kết quả tạo ra chi phí J ít nhất được xác định bởi chi phí hàm sau
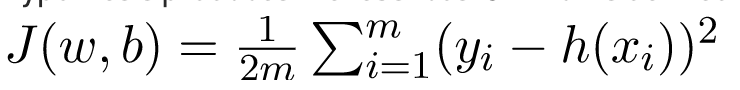
với m là số điểm dữ liệu trong tập dữ liệu đã cho. Chi phí Hàm này còn được gọi là Lỗi bình phương trung bình.
Để tìm giá trị được tối ưu hóa của các tham số mà J là nhỏ nhất, chúng tôi sẽ sử dụng một thuật toán tối ưu hóa thường được sử dụng gọi là Gradient Descent. Sau đây là mã giả cho Gradient Descent:
Lặp lại cho đến khi hội tụ
{
w = w - α * δJ/δw
b = b - α * δJ/δb
}trong đó α là một siêu tham số được gọi là Tốc độ Học tập.
2. Tensorflow
Tensorflow là một thư viện tính toán mã nguồn mở do Google tạo ra. Đây là một lựa chọn phổ biến để tạo các ứng dụng yêu cầu tính toán số cao cấp và / hoặc cần sử dụng Bộ xử lý đồ họa cho mục đích tính toán. Đây là những lý do chính mà Tensorflow là một trong những lựa chọn phổ biến nhất cho các ứng dụng Học máy, đặc biệt là Học sâu. Nó cũng có các API như Công cụ ước tính cung cấp mức độ trừu tượng cao trong khi xây dựng Ứng dụng Học máy. Trong bài viết này, chúng ta sẽ không sử dụng bất kỳ API cấp cao nào, thay vào đó chúng ta sẽ xây dựng mô hình Hồi quy tuyến tính bằng cách sử dụng Tensorflow cấp thấp trong Chế độ thực thi lười biếng trong đó Tensorflow tạo Đồ thị theo chu kỳ được hướng dẫn hoặc DAG để theo dõi tất cả tính toán, và sau đó thực thi tất cả các tính toán được thực hiện bên trong một Phiên Tensorflow.
3. Thực hiện
Chúng ta sẽ bắt đầu bằng cách nhập các thư viện cần thiết. Chúng ta sẽ sử dụng Numpy cùng với Tensorflow để tính toán và Matplotlib để vẽ biểu đồ.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt Để làm cho các số ngẫu nhiên có thể dự đoán được, chúng ta sẽ xác định các hạt cố định cho cả Numpy và Tensorflow.
np.random.seed(101)
tf.set_random_seed(101)Bây giờ, chúng ta hãy tạo một số dữ liệu ngẫu nhiên để đào tạo Mô hình hồi quy tuyến tính.
# Genrating random linear data
# There will be 50 data points ranging from 0 to 50
x = np.linspace(0, 50, 50)
y = np.linspace(0, 50, 50)
# Adding noise to the random linear data
x += np.random.uniform(-4, 4, 50)
y += np.random.uniform(-4, 4, 50)
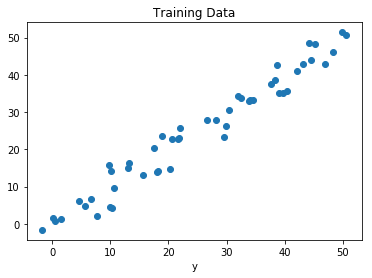
n = len(x) # Number of data points Chúng ta hình dung dữ liệu đào tạo.
# Plot of Training Data
plt.scatter(x, y)
plt.xlabel('x')
plt.xlabel('y')
plt.title("Training Data")
plt.show()Output
Bây giờ chúng ta sẽ bắt đầu tạo mô hình của mình bằng cách xác định các trình giữ chỗ X và Y, để chúng ta có thể cung cấp các ví dụ đào tạo X và Y vào trình tối ưu hóa trong quá trình đào tạo.
X = tf.placeholder("float")
Y = tf.placeholder("float") Bây giờ chúng ta sẽ khai báo hai biến Tensorflow có thể đào tạo cho Trọng số và Độ lệch và khởi tạo chúng ngẫu nhiên bằng cách sử dụng np.random.randn ().
W = tf.Variable(np.random.randn(), name = "W")
b = tf.Variable(np.random.randn(), name = "b")
Bây giờ chúng ta sẽ xác định các siêu tham số của mô hình, Tỷ lệ học tập và số Kỷ nguyên.
learning_rate = 0.01
training_epochs = 1000Bây giờ, chúng ta sẽ xây dựng Giả thuyết, Chi phí Hàm và Trình tối ưu hóa. Chúng ta sẽ không triển khai Gradient Descent Optimizer theo cách thủ công vì nó được xây dựng bên trong Tensorflow. Sau đó, chúng ta sẽ khởi tạo các Biến.
# Hypothesis
y_pred = tf.add(tf.multiply(X, W), b)
# Mean Squared Error Cost Function
cost = tf.reduce_sum(tf.pow(y_pred-Y, 2)) / (2 * n)
# Gradient Descent Optimizer
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# Global Variables Initializer
init = Bây giờ chúng ta sẽ bắt đầu quá trình đào tạo bên trong một Phiên Tensorflow.
# Starting the Tensorflow Session
with tf.Session() as sess:
# Initializing the Variables
sess.run(init)
# Iterating through all the epochs
for epoch in range(training_epochs):
# Feeding each data point into the optimizer using Feed Dictionary
for (_x, _y) in zip(x, y):
sess.run(optimizer, feed_dict = {X : _x, Y : _y})
# Displaying the result after every 50 epochs
if (epoch + 1) % 50 == 0:
# Calculating the cost a every epoch
c = sess.run(cost, feed_dict = {X : x, Y : y})
print("Epoch", (epoch + 1), ": cost =", c, "W =", sess.run(W), "b =", sess.run(b))
# Storing necessary values to be used outside the Session
training_cost = sess.run(cost, feed_dict ={X: x, Y: y})
weight = sess.run(W)
bias = sess.run(b) Bây giờ chúng ta hãy nhìn vào kết quả.
Epoch: 50 cost = 5.8868036 W = 0.9951241 b = 1.2381054
Epoch: 100 cost = 5.7912707 W = 0.99812365 b = 1.0914398
Epoch: 150 cost = 5.7119675 W = 1.0008028 b = 0.96044314
Epoch: 200 cost = 5.6459413 W = 1.0031956 b = 0.8434396
Epoch: 250 cost = 5.590799 W = 1.0053328 b = 0.7389357
Epoch: 300 cost = 5.544608 W = 1.007242 b = 0.6455922
Epoch: 350 cost = 5.5057883 W = 1.008947 b = 0.56222
Epoch: 400 cost = 5.473066 W = 1.01047 b = 0.48775345
Epoch: 450 cost = 5.4453845 W = 1.0118302 b = 0.42124167
Epoch: 500 cost = 5.421903 W = 1.0130452 b = 0.36183488
Epoch: 550 cost = 5.4019217 W = 1.0141305 b = 0.30877414
Epoch: 600 cost = 5.3848577 W = 1.0150996 b = 0.26138115
Epoch: 650 cost = 5.370246 W = 1.0159653 b = 0.21905091
Epoch: 700 cost = 5.3576994 W = 1.0167387 b = 0.18124212
Epoch: 750 cost = 5.3468933 W = 1.0174294 b = 0.14747244
Epoch: 800 cost = 5.3375573 W = 1.0180461 b = 0.11730931
Epoch: 850 cost = 5.3294764 W = 1.0185971 b = 0.090368524
Epoch: 900 cost = 5.322459 W = 1.0190892 b = 0.0663058
Epoch: 950 cost = 5.3163586 W = 1.0195289 b = 0.044813324
Epoch: 1000 cost = 5.3110332 W = 1.0199214 b = 0.02561663Bây giờ chúng ta hãy nhìn vào kết quả.
# Calculating the predictions
predictions = weight * x + bias
print("Training cost =", training_cost, "Weight =", weight, "bias =", bias, '\n') Output
Training cost = 5.3110332 Weight = 1.0199214 bias = 0.02561663Lưu ý rằng trong trường hợp này cả Trọng số và thiên vị đều là những đại lượng vô hướng. Điều này là do, chúng ta chỉ xem xét một biến phụ thuộc trong dữ liệu huấn luyện. Nếu chúng ta có m biến phụ thuộc trong tập dữ liệu huấn luyện của mình, thì Trọng số sẽ là một vectơ m chiều trong khi thiên vị sẽ là một đại lượng vô hướng.
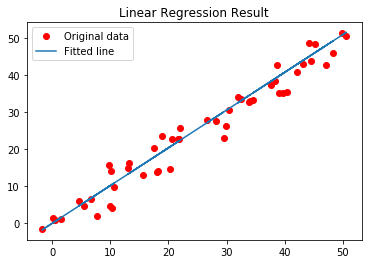
Cuối cùng, chúng ta sẽ vẽ kết quả của chúng ta.
# Plotting the Results
plt.plot(x, y, 'ro', label ='Original data')
plt.plot(x, predictions, label ='Fitted line')
plt.title('Linear Regression Result')
plt.legend()
plt.show() Output
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}