
Trong ML , chúng ta thường xử lý các tập dữ liệu chứa nhiều nhãn trong một hoặc nhiều cột. Các nhãn này có thể ở dạng từ hoặc số. Để làm cho dữ liệu dễ hiểu hoặc ở dạng con người có thể đọc được, dữ liệu huấn luyện thường được gắn nhãn bằng chữ.
Mã hóa nhãn đề cập đến việc chuyển đổi các nhãn thành dạng số để chuyển nó thành dạng máy có thể đọc được. Sau đó, các thuật toán ML có thể quyết định theo cách tốt hơn về cách các nhãn đó phải được vận hành. Đây là bước tiền xử lý quan trọng đối với tập dữ liệu có cấu trúc trong học có giám sát.
Thí dụ :
Giả sử chúng ta có một cột Chiều cao trong một số tập dữ liệu.
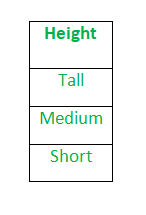
Sau khi áp dụng mã hóa nhãn, cột Chiều cao được chuyển đổi thành:
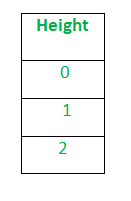
trong đó 0 là nhãn cho chiều cao, 1 là nhãn cho chiều cao trung bình và 2 là nhãn cho chiều cao ngắn.
Chúng ta áp dụng Mã hóa nhãn trên tập dữ liệu mống mắt trên cột mục tiêu là Loài. Nó chứa ba loài Iris-setosa, Iris-versicolor, Iris-virginica.
# Import libraries
import numpy as np
import pandas as pd
# Import dataset
df = pd.read_csv('../../data/Iris.csv')
df['species'].unique() Output
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)Sau khi áp dụng code mã hóa nhãn –
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# Import label encoder
from sklearn import preprocessing
# label_encoder object knows how to understand word labels.
label_encoder = preprocessing.LabelEncoder()
# Encode labels in column 'species'.
df['species']= label_encoder.fit_transform(df['species'])
df['species'].unique() Output:
array([0, 1, 2], dtype=int64)Giới hạn của mã hóa nhãn
Mã hóa nhãn chuyển đổi dữ liệu ở dạng máy có thể đọc được, nhưng nó chỉ định một số duy nhất (bắt đầu từ 0) cho mỗi lớp dữ liệu. Điều này có thể dẫn đến phát sinh vấn đề ưu tiên trong việc đào tạo các tập dữ liệu. Nhãn có giá trị cao có thể được coi là có mức độ ưu tiên cao hơn nhãn có giá trị thấp hơn.
Thí dụ
Một thuộc tính có các lớp đầu ra mexico, paris, dubai. Trong Mã hóa nhãn cột này, mexico được thay thế bằng 0, paris được thay bằng 1 và dubai được thay bằng 2.
Với điều này, có thể hiểu rằng dubai có mức độ ưu tiên cao hơn mexico và paris trong khi đào tạo người mẫu, Nhưng thực tế không có mối quan hệ ưu tiên như vậy giữa các thành phố này ở đây.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}