
Mở rộng đặt tính là một kỹ thuật để chuẩn hóa các đặc tính độc lập có trong dữ liệu trong một phạm vi cố định. Nó được thực hiện trong quá trình xử lý trước của dữ liệu để xử lý các cường độ hoặc giá trị hoặc các đơn vị khác nhau. Nếu đặc tính mở rộng quy mô không được thực hiện, thì thuật toán ML có xu hướng cân nhắc các giá trị lớn hơn, cao hơn và coi các giá trị nhỏ hơn là giá trị thấp hơn, bất kể đơn vị của các giá trị.
Ví dụ: Nếu thuật toán không sử dụng phương pháp chia để mở rộng đối tượng thì nó có thể coi giá trị 3000 mét lớn hơn 5 km nhưng điều đó thực sự không đúng và trong trường hợp này, thuật toán sẽ đưa ra dự đoán sai. Vì vậy, chúng ta sử dụng Feature Scaling để đưa tất cả các giá trị về cùng độ lớn và giải quyết vấn đề này.
Các kỹ thuật thực hiện đặc tính Mở rộng:
Hãy xem xét hai điều quan trọng nhất:
- Chuẩn hóa tối thiểu – tối đa: Kỹ thuật này chia tỷ lệ lại một đặc tính hoặc giá trị quan sát với giá trị phân phối từ 0 đến 1.
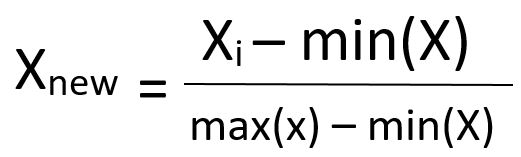
- Chuẩn hóa: Đây là một kỹ thuật rất hiệu quả trong đó cân nhắc lại một giá trị của đối tượng địa lý để nó phân phối với giá trị trung bình bằng 0 và phương sai bằng 1.
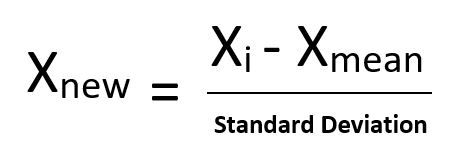
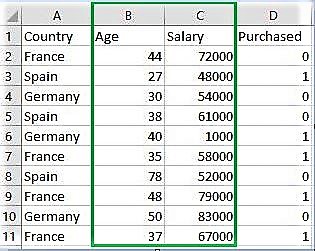
Tải xuống tập dữ liệu:
Truy cập liên kết và tải xuống Data_for_Feature_Scaling.csv
Dưới đây là code Python:
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# Python code explaining How to
# perform Feature Scaling
""" PART 1
Importing Libraries """
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Sklearn library
from sklearn import preprocessing
""" PART 2
Importing Data """
data_set = pd.read_csv('C:\\Users\\dell\\Desktop\\Data_for_Feature_Scaling.csv')
data_set.head()
# here Features - Age and Salary columns
# are taken using slicing
# to handle values with varying magnitude
x = data_set.iloc[:, 1:3].values
print ("\nOriginal data values : \n", x)
""" PART 4
Handling the missing values """
from sklearn import preprocessing
""" MIN MAX SCALER """
min_max_scaler = preprocessing.MinMaxScaler(feature_range =(0, 1))
# Scaled feature
x_after_min_max_scaler = min_max_scaler.fit_transform(x)
print ("\nAfter min max Scaling : \n", x_after_min_max_scaler)
""" Standardisation """
Standardisation = preprocessing.StandardScaler()
# Scaled feature
x_after_Standardisation = Standardisation.fit_transform(x)
print ("\nAfter Standardisation : \n", x_after_Standardisation) Output:
Country Age Salary Purchased
0 France 44 72000 0
1 Spain 27 48000 1
2 Germany 30 54000 0
3 Spain 38 61000 0
4 Germany 40 1000 1
Original data values :
[[ 44 72000]
[ 27 48000]
[ 30 54000]
[ 38 61000]
[ 40 1000]
[ 35 58000]
[ 78 52000]
[ 48 79000]
[ 50 83000]
[ 37 67000]]
After min max Scaling :
[[ 0.33333333 0.86585366]
[ 0. 0.57317073]
[ 0.05882353 0.64634146]
[ 0.21568627 0.73170732]
[ 0.25490196 0. ]
[ 0.15686275 0.69512195]
[ 1. 0.62195122]
[ 0.41176471 0.95121951]
[ 0.45098039 1. ]
[ 0.19607843 0.80487805]]
After Standardisation :
[[ 0.09536935 0.66527061]
[-1.15176827 -0.43586695]
[-0.93168516 -0.16058256]
[-0.34479687 0.16058256]
[-0.1980748 -2.59226136]
[-0.56487998 0.02294037]
[ 2.58964459 -0.25234403]
[ 0.38881349 0.98643574]
[ 0.53553557 1.16995867]
[-0.41815791 0.43586695]]Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}