
Điều kiện tiên quyết: K-means Clustering – Giới thiệu
Nội dung chính
1. Mặt hạn chế của thuật toán K-mean tiêu chuẩn:
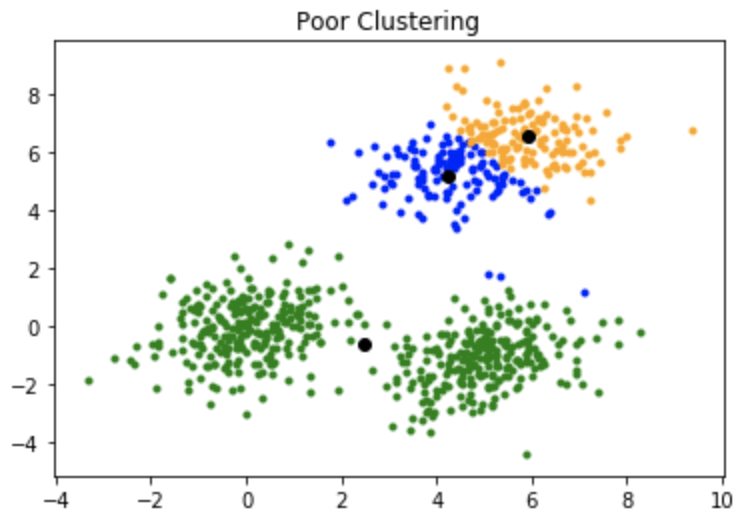
Một nhược điểm của thuật toán K-mean là nó nhạy cảm với việc khởi tạo các trọng tâm hoặc các điểm trung bình. Vì vậy, nếu một centroid được khởi tạo là một điểm “xa”, nó có thể chỉ kết thúc không có điểm nào được liên kết với nó và đồng thời, nhiều hơn một cụm có thể kết thúc với một centroid duy nhất. Tương tự, nhiều hơn một trung tâm có thể được khởi tạo vào cùng một cụm dẫn đến phân cụm kém. Ví dụ, hãy xem xét các hình ảnh hiển thị bên dưới.
2. Khởi tạo trung tâm kém dẫn đến phân cụm kém.
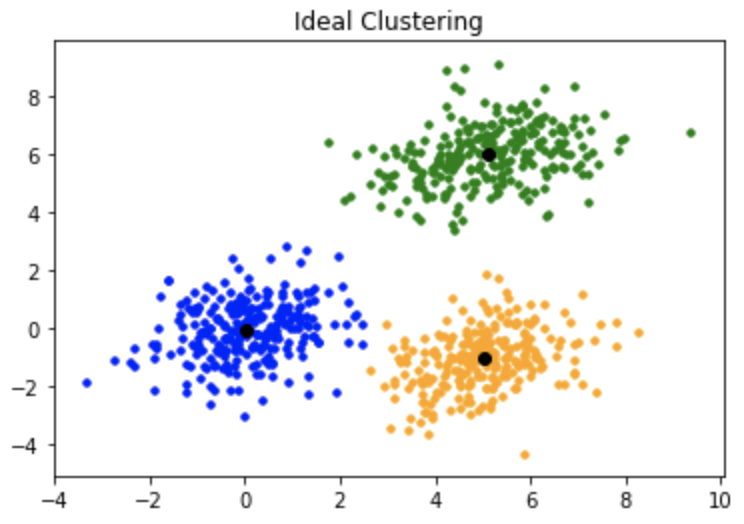
Đây là cách phân cụm lẽ ra:
3. K-mean ++:
Để khắc phục nhược điểm nêu trên, chúng ta sử dụng K-mean ++. Thuật toán này đảm bảo khởi tạo centroid thông minh hơn và cải thiện chất lượng của phân cụm. Ngoài phần khởi tạo, phần còn lại của thuật toán giống như thuật toán K-mean tiêu chuẩn. Đó là K-mean ++ là thuật toán K-mean tiêu chuẩn kết hợp với việc khởi tạo centroid thông minh hơn.
4. Thuật toán khởi tạo:
Các bước liên quan là:
Chọn ngẫu nhiên centroid đầu tiên từ các điểm dữ liệu.
Đối với mỗi điểm dữ liệu, tính toán khoảng cách của nó từ trung tâm gần nhất, đã chọn trước đó.
Chọn centroid tiếp theo từ các điểm dữ liệu sao cho xác suất chọn một điểm làm centroid tỷ lệ thuận với khoảng cách của nó từ centroid gần nhất, đã chọn trước đó. (tức là điểm có khoảng cách tối đa từ tâm gần nhất có nhiều khả năng được chọn tiếp theo làm tâm)
Lặp lại các bước 2 và 3 cho đến khi k centroid được lấy mẫu
Trực giác:
Bằng cách thực hiện theo quy trình khởi tạo ở trên, chúng ta nhận ra các centroid cách xa nhau. Điều này làm tăng cơ hội ban đầu nhặt được các trung tâm nằm trong các cụm khác nhau. Ngoài ra, vì các centroid được chọn từ các điểm dữ liệu, mỗi centroid có một số điểm dữ liệu được liên kết với nó ở cuối.
5. Thực hiện:
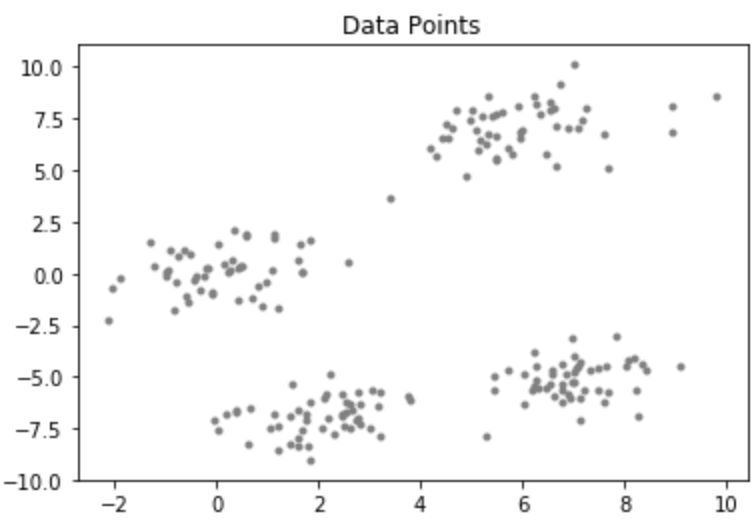
Hãy xem xét một tập dữ liệu có phân phối sau:
Mã: Mã Python cho Thuật toán KMean ++
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# importing dependencies
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sys
# creating data
mean_01 = np.array([0.0, 0.0])
cov_01 = np.array([[1, 0.3], [0.3, 1]])
dist_01 = np.random.multivariate_normal(mean_01, cov_01, 100)
mean_02 = np.array([6.0, 7.0])
cov_02 = np.array([[1.5, 0.3], [0.3, 1]])
dist_02 = np.random.multivariate_normal(mean_02, cov_02, 100)
mean_03 = np.array([7.0, -5.0])
cov_03 = np.array([[1.2, 0.5], [0.5, 1,3]])
dist_03 = np.random.multivariate_normal(mean_03, cov_01, 100)
mean_04 = np.array([2.0, -7.0])
cov_04 = np.array([[1.2, 0.5], [0.5, 1,3]])
dist_04 = np.random.multivariate_normal(mean_04, cov_01, 100)
data = np.vstack((dist_01, dist_02, dist_03, dist_04))
np.random.shuffle(data)
# function to plot the selected centroids
def plot(data, centroids):
plt.scatter(data[:, 0], data[:, 1], marker = '.',
color = 'gray', label = 'data points')
plt.scatter(centroids[:-1, 0], centroids[:-1, 1],
color = 'black', label = 'previously selected centroids')
plt.scatter(centroids[-1, 0], centroids[-1, 1],
color = 'red', label = 'next centroid')
plt.title('Select % d th centroid'%(centroids.shape[0]))
plt.legend()
plt.xlim(-5, 12)
plt.ylim(-10, 15)
plt.show()
# function to compute euclidean distance
def distance(p1, p2):
return np.sum((p1 - p2)**2)
# initialization algorithm
def initialize(data, k):
'''
initialized the centroids for K-means++
inputs:
data - numpy array of data points having shape (200, 2)
k - number of clusters
'''
## initialize the centroids list and add
## a randomly selected data point to the list
centroids = []
centroids.append(data[np.random.randint(
data.shape[0]), :])
plot(data, np.array(centroids))
## compute remaining k - 1 centroids
for c_id in range(k - 1):
## initialize a list to store distances of data
## points from nearest centroid
dist = []
for i in range(data.shape[0]):
point = data[i, :]
d = sys.maxsize
## compute distance of 'point' from each of the previously
## selected centroid and store the minimum distance
for j in range(len(centroids)):
temp_dist = distance(point, centroids[j])
d = min(d, temp_dist)
dist.append(d)
## select data point with maximum distance as our next centroid
dist = np.array(dist)
next_centroid = data[np.argmax(dist), :]
centroids.append(next_centroid)
dist = []
plot(data, np.array(centroids))
return centroids
# call the initialize function to get the centroids
centroids = initialize(data, k = 4) Output
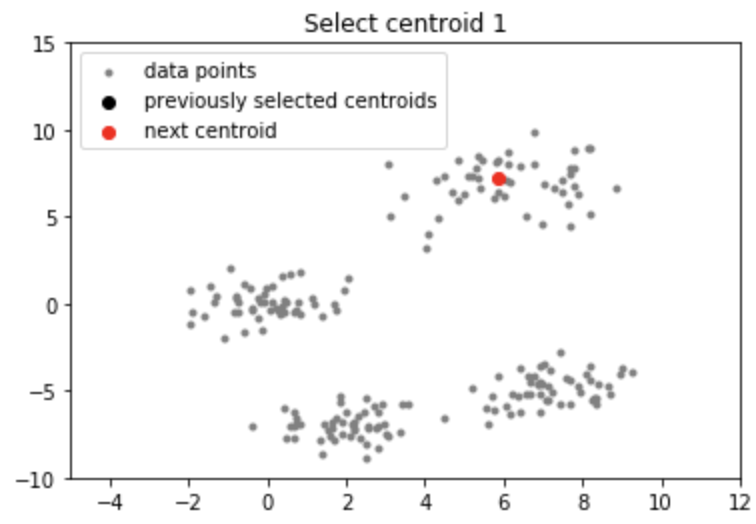
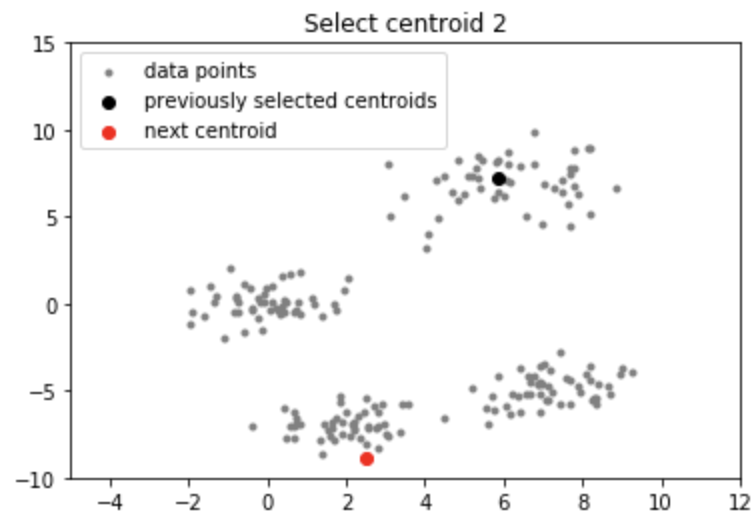
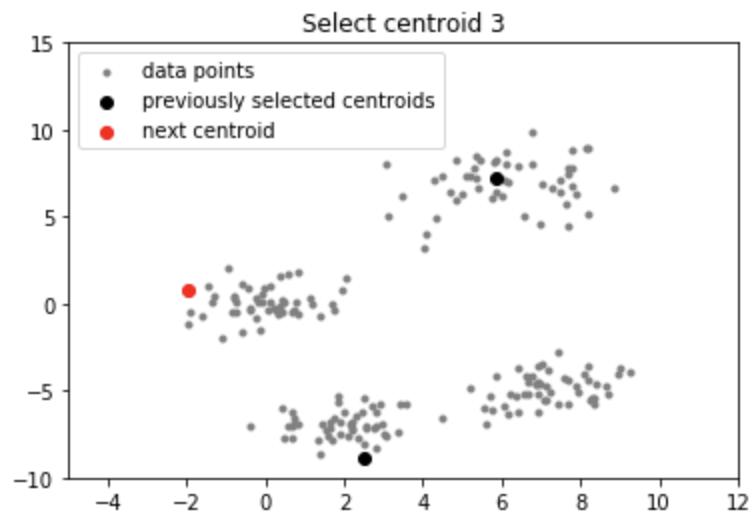
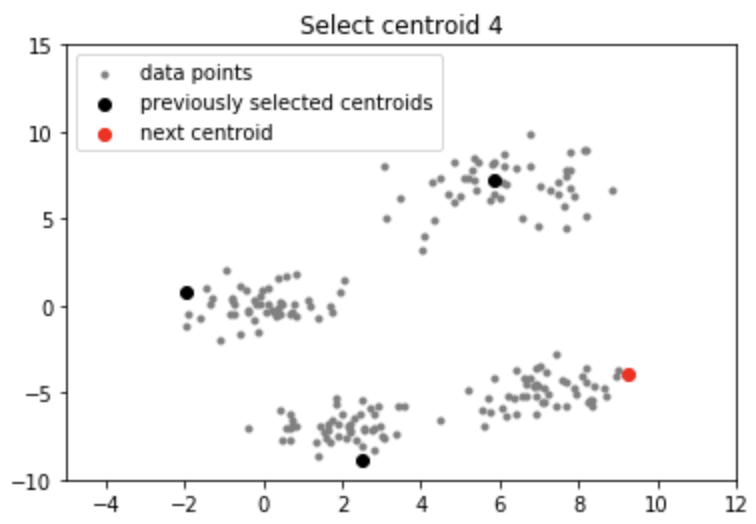
Lưu ý: Mặc dù việc khởi tạo trong K-means ++ đắt hơn về mặt tính toán so với thuật toán K-mean tiêu chuẩn, nhưng thời gian chạy để hội tụ đến mức tối ưu được giảm đáng kể đối với K-means ++. Điều này là do các trung tâm được chọn ban đầu có thể đã nằm trong các cụm khác nhau.
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}