
Bất cứ khi nào chúng ta nghĩ đến ML, điều đầu tiên xuất hiện trong đầu chúng ta là một tập dữ liệu. Mặc dù có rất nhiều bộ dữ liệu mà bạn có thể tìm thấy trên các trang web, nhưng đôi khi việc trích xuất dữ liệu của riêng bạn và tạo bộ dữ liệu của riêng bạn sẽ rất hữu ích. Việc tạo tập dữ liệu của riêng bạn cho phép bạn kiểm soát dữ liệu nhiều hơn và cho phép bạn đào tạo mô hình ML của mình.
Trong bài viết này, Cafedev sẽ tạo tập dữ liệu ngẫu nhiên bằng cách sử dụng thư viện Numpy trong Python.
Các thư viện cần có:
-> Numpy: sudo pip install numpy
-> Pandas: sudo pip install pandas
-> Matplotlib: sudo pip install matplotlib
Nội dung chính
1. Phân phối bình thường:
Trong lý thuyết xác suất, phân phối chuẩn hoặc Gaussian là một phân bố xác suất liên tục rất phổ biến, đối xứng với giá trị trung bình, cho thấy rằng dữ liệu gần giá trị trung bình thường xuất hiện hơn dữ liệu xa giá trị trung bình. Phân phối chuẩn được sử dụng trong thống kê và thường được sử dụng để biểu diễn các biến ngẫu nhiên có giá trị thực.
Phân phối chuẩn là loại phân phối phổ biến nhất trong phân tích thống kê. Phân phối chuẩn chuẩn có hai tham số: giá trị trung bình và độ lệch chuẩn. Giá trị trung bình là xu hướng trung tâm của phân phối. Độ lệch chuẩn là một thước đo của sự thay đổi. Nó xác định chiều rộng của phân phối chuẩn. Độ lệch chuẩn xác định khoảng cách xa giá trị trung bình mà các giá trị có xu hướng giảm. Nó thể hiện khoảng cách điển hình giữa các quan sát và giá trị trung bình. nó phù hợp với nhiều hiện tượng tự nhiên, Ví dụ: chiều cao, huyết áp, sai số đo và điểm IQ tuân theo phân phối chuẩn.
2. Đồ thị phân phối chuẩn:
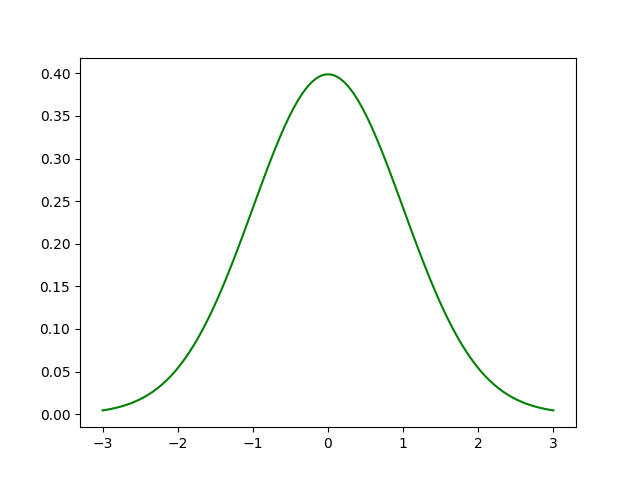
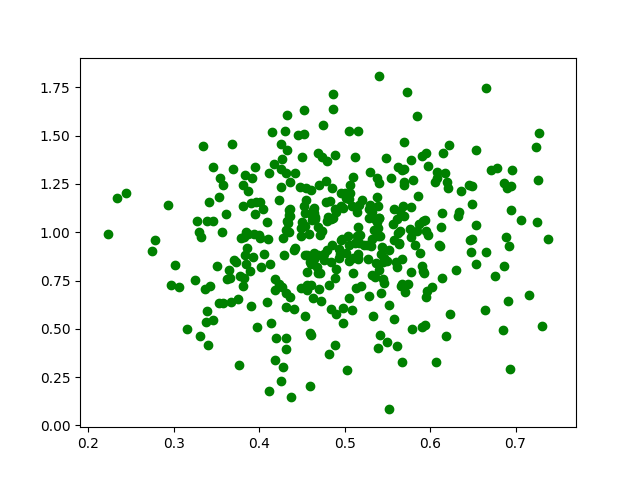
Ví dụ:
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# importing libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# initialize the parameters for the normal
# distribution, namely mean and std.
# deviation
# defining the mean
mu = 0.5
# defining the standard deviation
sigma = 0.1
# The random module uses the seed value as a base
# to generate a random number. If seed value is not
# present, it takes the system’s current time.
np.random.seed(0)
# define the x co-ordinates
X = np.random.normal(mu, sigma, (395, 1))
# define the y co-ordinates
Y = np.random.normal(mu * 2, sigma * 3, (395, 1))
# plot a graph
plt.scatter(X, Y, color = 'g')
plt.show() Output:
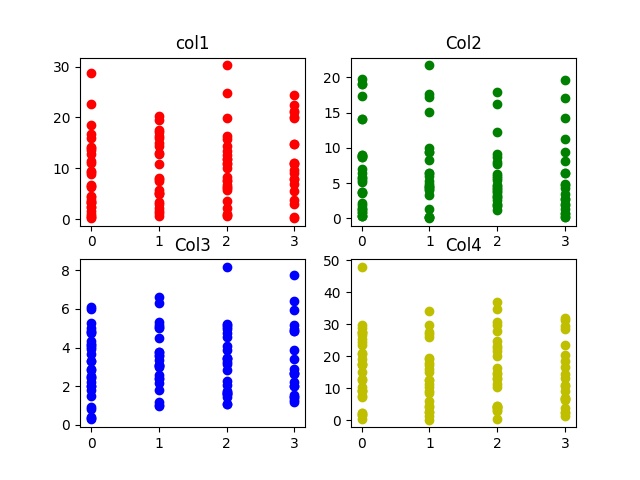
3. Ví dụ
Chúng ta sẽ tạo một tập dữ liệu với 4 cột. Mỗi cột trong tập dữ liệu đại diện cho một tính năng. Cột thứ 5 của tập dữ liệu là nhãn đầu ra. Nó thay đổi trong khoảng 0-3. Tập dữ liệu này có thể được sử dụng để đào tạo một bộ phân loại như bộ phân loại hồi quy logistic, bộ phân loại mạng nơ ron, ML vectơ hỗ trợ, v.v.
# -----------------------------------------------------------
#Cafedev.vn - Kênh thông tin IT hàng đầu Việt Nam
#@author cafedevn
#Contact: cafedevn@gmail.com
#Fanpage: https://www.facebook.com/cafedevn
#Group: https://www.facebook.com/groups/cafedev.vn/
#Instagram: https://instagram.com/cafedevn
#Twitter: https://twitter.com/CafedeVn
#Linkedin: https://www.linkedin.com/in/cafe-dev-407054199/
#Pinterest: https://www.pinterest.com/cafedevvn/
#YouTube: https://www.youtube.com/channel/UCE7zpY_SlHGEgo67pHxqIoA/
# -----------------------------------------------------------
# importing libraries
import numpy as np
import pandas as pd
import math
import random
import matplotlib.pyplot as plt
# defining the columns using normal distribution
# column 1
point1 = abs(np.random.normal(1, 12, 100))
# column 2
point2 = abs(np.random.normal(2, 8, 100))
# column 3
point3 = abs(np.random.normal(3, 2, 100))
# column 4
point4 = abs(np.random.normal(10, 15, 100))
# x contains the features of our dataset
# the points are concatenated horizontally
# using numpy to form a feature vector.
x = np.c_[point1, point2, point3, point4]
# the output labels vary from 0-3
y = [int(np.random.randint(0, 4)) for i in range(100)]
# defining a pandas data frame to save
# the data for later use
data = pd.DataFrame()
# defining the columns of the dataset
data['col1'] = point1
data['col2'] = point2
data['col3'] = point3
data['col4'] = point4
# plotting the various features (x)
# against the labels (y).
plt.subplot(2, 2, 1)
plt.title('col1')
plt.scatter(y, point1, color ='r', label ='col1')
plt.subplot(2, 2, 2)
plt.title('Col2')
plt.scatter(y, point2, color = 'g', label ='col2')
plt.subplot(2, 2, 3)
plt.title('Col3')
plt.scatter(y, point3, color ='b', label ='col3')
plt.subplot(2, 2, 4)
plt.title('Col4')
plt.scatter(y, point4, color ='y', label ='col4')
# saving the graph
plt.savefig('data_visualization.jpg')
# displaying the graph
plt.show() Output:
Cài ứng dụng cafedev để dễ dàng cập nhật tin và học lập trình mọi lúc mọi nơi tại đây.
Nguồn và Tài liệu tiếng anh tham khảo:
Tài liệu từ cafedev:
- Full series tự học Python từ cơ bản tới nâng cao tại đây nha.
- Tự học ML bằng Python từ cơ bản tới nâng cao.
- Ebook về python tại đây.
- Các series tự học lập trình MIỄN PHÍ khác
- Nơi liên hệ hợp tác hoặc quảng cáo cùng Cafedevn tại đây.
Nếu bạn thấy hay và hữu ích, bạn có thể tham gia các kênh sau của cafedev để nhận được nhiều hơn nữa:
Chào thân ái và quyết thắng!




 trong C++")


{kind=link}